说明:本文仅供学习,未经同意请勿转载
笔记时间:2022年08月
博客公开时间:2023年3月2日
前情回顾
 前面我们大致的了解了Graph Transformer是什么,以及它与GNN、Transformer的差别,关联。如果对这方面不是很熟悉的朋友可以看一下【图-注意力笔记,篇章1】一份PPT带你快速了解Graph Transformer:包括Graph Transformer 的简要回顾且其与GNN、Transformer的关联
前面我们大致的了解了Graph Transformer是什么,以及它与GNN、Transformer的差别,关联。如果对这方面不是很熟悉的朋友可以看一下【图-注意力笔记,篇章1】一份PPT带你快速了解Graph Transformer:包括Graph Transformer 的简要回顾且其与GNN、Transformer的关联
在大致的了解Graph Transformer之后,笔者在篇章2中将介绍一下两篇笔者自身认为必看的经典Graph Transformer的文章——Graphormer和GraphFormers。
 别看这两个名字有点像,但是它们的做法是不一样得。在篇章1中,我们可以知道Graph Transformer实际上就是GNN和Transformer的结合。根据笔者我阅读的文献来看,我大致地将后面改进方向粗略地分成四个(ps:当然本人看的文献有限,存在缺漏,有不对的或者其他更加有趣的点,欢迎学习交流!):
别看这两个名字有点像,但是它们的做法是不一样得。在篇章1中,我们可以知道Graph Transformer实际上就是GNN和Transformer的结合。根据笔者我阅读的文献来看,我大致地将后面改进方向粗略地分成四个(ps:当然本人看的文献有限,存在缺漏,有不对的或者其他更加有趣的点,欢迎学习交流!):
- 怎么设置位置编码,也就是PE。常见的PE编码设置有很多,比如Local PE, Global PE和Relative PE。PE的方式很多,而且很多来源于Transformer的文章,这里我就不找对应的论文来介绍了。在篇章1中,我们知道论文GraphTrans中并没有采用PE,而是采用像VIT一样的[CLS],这样子的[CLS]处理方式可以实现:在聚合信息时,可以实现排列不变性,也就是在不考虑节点重要性的情况下,属于同一类型同一阶的邻居节点没有优先级的区分。
- 怎么融入拓扑结构信息。拓扑结构信息是指边的属性/特征,图路径的属性/特征,拓扑空间的属性,或者图的频谱性等。在多数论文中,常见的就有将边的特征(也就是边的权重矩阵)添加至attetion里面,还有的就是利用结构编码SE实现结构信息的融入,或者是先通过学习子图结构的信息,再进Transformer机制。对于SE,同样常见的也有Local SE, Global SE和Relative SE。最后,还有的论文是把空间上的拓扑特征也添加至attention里面。比如说这里我要讲的第一篇论文Graphormer。
- 怎么考虑更复杂的图属性/结构。要知道在现实中,图多数是异质图,包含多种类型的边/路径,而且不同的节点之间的重要性应该是不一样的。所以,针对多关系的局限,有的研究会考虑关系编码RE或者边类型编码(这个我也把它称之为RE,因为边本身也可以看出一种关系)。针对节点类型/重要性,有的研究会添加类型编码,重要性编码来解决。其中,重要性编码同样在Graphormer中也有应用。
- 怎么结合GNN和Transformer。早期多数的研究都是直接GNN拼接Transformer。其实还有更多结合的方式,这也是本博文想要介绍GraphFormer论文的原因。
基于上面的介绍,其实我想分享的这两篇论文的理由也十分清晰了。后面就来看看这两篇文献吧。
论文信息概览
在介绍之前,我们先概览一下这两篇文章的信息。
可以发现这两篇文献都是NeurlPS 2021的文章,但它们的驱动任务是不同的。Graphormer是在化学分子评分的场景下提出,主要做的是图层面的回归任务,而GraphFormer则是边层面上的任务,做的是边预测,主要应用在文本场景中。在下面的笔记中,笔者我只介绍和概括笔者认为比较重要的内容,对于细节部分,大家感兴趣的话,建议直接看原论文。
Graphormer
论文信息概览
-
paper name:《Do Transformers Really Perform Bad for Graph Representation?》
-
原文链接:https://proceedings.neurips.cc/paper/2021/file/f1c1592588411002af340cbaedd6fc33-Paper.pdf
-
源码链接:https://github.com/Microsoft/Graphormer.
-
来源:大连科大, NeurIPS
-
数据背景:Kaggle比赛,化学分子评分背景
-
年限:2021
论文核心要点介绍

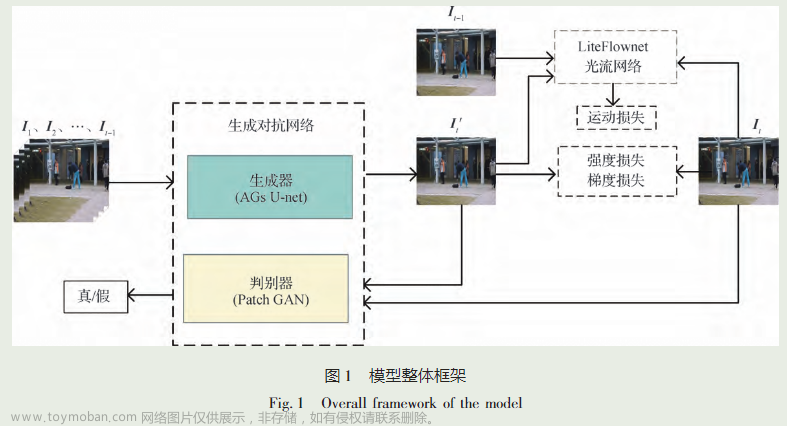
Graphormer论文不得不夸一下这篇论文的图👍,属于那种看图就知道文章在做什么了。
三大编码的介绍
从上面的图,我们可以快速的知道,Graphormer模型的核心内容就是中引入了三种编码方式,分别是Centrality Encoding(中心性编码), Edge Encoding (边特征编码)和Spatial Encoding(空间位置编码)。其中:
Centrality Encoding
Centrality Encoding从名字看就知道作者计算了节点的中心性。在图论中,节点的中心性代表这节点的重要性。节点中心性有很多种,比如特征向量中心性(Eigenvector Centrality), 介数中心性(Betweenness Centrality),接近中心性(Closeness Centrality),PageRank中心性和这里的度中心性等。这些都是图论中比较基础的概念了,如果不了解,建议自己去看一下这些。
在Graphormer论文中(看PPT上面右下角第一行的蓝色标记),作者主要采用的是度中心性。因此,Centrality Encoding考虑了节点的重要性。而且从PPT里面我框的红色公式来看,这里的节点度的计算包括出度 d e g − ( v i ) deg^-{(v_i)} deg−(vi)和入度 d e g + ( v i ) deg^+{(v_i)} deg+(vi),考虑了边的方向。所以进入Transformer之前,节点的特征 h i ( 0 ) h_i^{(0)} hi(0)是原本节点的特征 x i x_i xi加上节点入度的线性变换特征 z d e g + ( v i ) + z^+_{deg^+{(v_i)}} zdeg+(vi)+和节点出度的线性变换特征 z d e g − ( v i ) − z^-_{deg^-{(v_i)}} zdeg−(vi)−。
Spatial Encoding
Spatial Encoding同样非常清晰,空间编码。类似于相对编码。我们知道Transformer主要是关注全局信息,对图的局部拓扑属性的捕捉差。因此,才会有结构编码或者子图结构编码的相关研究。这里, Graphormer论文为了融入图空间上的拓扑结构属性的话,引入了空间编码。那么这个空间编码具体是怎么做呢?可以看到PPT右下角红色框的那部分,Graphormer作者在这里利用弗洛伊德算法计算两个节点之间的最短路径距离(shortest path distance, SPD),以此编码空间属性。那可能有的人就会有“为什么SPD可以表征空间属性"这个疑问。这是因为我们计算了每个节点之间最短路径距离的时候,就可以知道原来有节点与节点之间隔了多少条边,节点与节点之间的连接状态大概是怎么样的。因此,最短路径可以用来捕获图的非欧式空间的拓扑结构属性。
同时,作者考虑不可达的情况,将不可达之间节点的距离定义为-1。因此,到这里,我们应该知道SPD是可以用来捕获空间属性的,而且由于是最短路径SP,所以它获取的是局部信息的空间属性。在论文中Spatial Encoding,也就是最短路径距离
ϕ
(
v
i
,
v
j
)
\phi(v_i, v_j)
ϕ(vi,vj)主要是加在注意力机制
A
A
A的偏置
b
b
b上,也就是上面PPT右上蓝色框的部分,因此attention
A
i
j
A_{ij}
Aij就变成:
A
i
j
=
(
h
i
W
Q
)
(
h
i
W
K
)
T
d
+
b
ϕ
(
v
i
,
v
j
)
A_{ij}=\frac{(h_iW_Q)(h_iW_K)^T}{\sqrt{d}} + b_{\phi(v_i, v_j)}
Aij=d(hiWQ)(hiWK)T+bϕ(vi,vj)
注意,这里跟节点度中心性一样,也对属性进行线性变换。 相当于使用一个可学习缩放函数
b
b
b对我们原始计算的SPD进行缩放编码。这样子做可以让图自适应地调整不同距离的节点重要性。一般来说
b
b
b应该是一个相对最短路径距离
ϕ
(
v
i
,
v
j
)
\phi(v_i, v_j)
ϕ(vi,vj)的递减函数,因为模型认为,随着距离
ϕ
(
v
i
,
v
j
)
\phi(v_i, v_j)
ϕ(vi,vj)增加,节点重要性会逐渐降低。因此,Spatial Encoding实际上也可以看出节点重要性的间接表达。这里还需要注意的是,
b
b
b在不同层之间是共享的,因为最短的路径距离
ϕ
(
v
i
,
v
j
)
\phi(v_i, v_j)
ϕ(vi,vj)对于这里的Graph来说是固定, Graphormer本身并不会改变图的连接(指0-1连接)状态,因此,每一层的对SPD的缩放
ϕ
(
v
i
,
v
j
)
\phi(v_i, v_j)
ϕ(vi,vj)应该是一致的。
Edge Encoding
Edge Encoding也是非常清晰,作者引入了边特征的编码。前面篇章1中我们也讲过边特征编码的引入,那么在以往边特征的引入有以下三种方法:
- 将边缘特征添加到关联节点的特征中;
- 对于每个节点,其相关边的特征将与聚合中的节点特征一起使用;
- 直接将边的连接权重矩阵进行线性变换后添加至于attention中。
其中,前两种方法是GNN中常见的做法,尤其在有带边的特征的图中应用广泛,而第三种方法则是早期Graph Transformer进阶2中常见的方式。(这里可以跳转至【图-注意力笔记,篇章1】看一下)。然而,前两种做法仅将边信息传播到其关联的节点,无法利用边的特征信息来表达整个图的复杂连接转态,无法从更加全局的角度看待边特征与节点的关联;而第三种做法的话,则无法捕获边连接的局部拓扑属性。
那么针对上面的局限呢,在Graphormer中,作者通过计算节点之间的最短路径SP上所有边特征的加权平均值来得到Edge Encoding, 具体的做法如下面PPT中绿色框的 c i j = 1 N ∑ n = 1 N x e n ( w n E ) T c_{ij}=\frac{1}{N} \sum_{n=1}^Nx_{e_n}(w_n^E)^T cij=N1∑n=1Nxen(wnE)T。其中 e n e_n en为边特征, w n E w_n^E wnE为可学习权重。
与空间编码相似,作者这里同样将边特征编码
c
i
j
c_{ij}
cij添加至注意力机制
A
A
A的偏置上。因此,Graphormer最后的attention
A
i
j
A_{ij}
Aij就变成:
A
i
j
=
(
h
i
W
Q
)
(
h
i
W
K
)
T
d
+
b
ϕ
(
v
i
,
v
j
)
+
c
i
j
,
w
h
e
r
e
:
c
i
j
=
1
N
∑
n
=
1
N
x
e
n
(
w
n
E
)
T
A_{ij}=\frac{(h_iW_Q)(h_iW_K)^T}{\sqrt{d}} + b_{\phi(v_i, v_j)} +c_{ij}, \ where: \ c_{ij}=\frac{1}{N} \sum_{n=1}^Nx_{e_n}(w_n^E)^T
Aij=d(hiWQ)(hiWK)T+bϕ(vi,vj)+cij, where: cij=N1n=1∑Nxen(wnE)T
其他一些需要注意的点
-
多头注意力机制的计算
Graphormer中多头注意力机制的计算如下:
h ′ ( l ) = M H A ( L N ( h ( l − 1 ) ) ) + h ( l − 1 ) h ( l ) = F F N ( L N ( h ′ ( l ) ) ) + h ′ ( l ) h^{′(l)}=MHA(LN(h^{(l−1)}))+h^{(l−1)} \\ \\ h^{(l)}=FFN(LN(h^{′(l)}))+h^{′(l)} h′(l)=MHA(LN(h(l−1)))+h(l−1)h(l)=FFN(LN(h′(l)))+h′(l)
这里跟大多数Transformer层的做法是一样的。 -
全连接节点 [VNode] 的引入
在Graphormer中,作者向图中添加了一个名为 [VNode] 的特殊虚拟节点 Virtual Node,这个节点与其他所有节点相连。因此,这里我称 [VNode] 为全连接节点。基于此,在信息聚合时,[VNode] 就可以聚集所有的节点表示,它的节点特征实际上就是整个图的嵌入。实际上,这里的 [VNode] 有点像BERT模型里的[CLS]。 因此,最终图表示的结果就是这个虚拟节点 [VNode] 的嵌入表示。
根据上面的介绍,既然 [VNode] 为全连接节点,那么它与其他节点的最短路径距离SPD ϕ ( v i , [ V N o d e ] ) \phi(v_i, [VNode]) ϕ(vi,[VNode])就都是1。同时作者考虑到 [VNode] 与其他节点的连接是我们假定连接的(也就是虚拟的),而不是现实存在的。因此,为了区分现实存在的边,也就是Graph的物理连接,与虚拟连接之间的区别,作者在空间编码时,将[VNode]与其他节点的连接看成一种特殊的存在,单独为其设置不同的 b b b,即为 ϕ ( v i , [ V N o d e ] ) \phi(v_i, [VNode]) ϕ(vi,[VNode])和 ϕ ( [ V N o d e ] , v j ) \phi([VNode], v_j) ϕ([VNode],vj)的所有空间编码 b ϕ ( v i , [ V N o d e ] ) b_{\phi(v_i, [VNode])} bϕ(vi,[VNode])和 b ϕ ( [ V N o d e ] , v j ) b_{\phi([VNode], v_j)} bϕ([VNode],vj)重置为一个不同的可学习标量。
结果概览及分析
这里我只截取了我比较关注的结果,更多结果请移步至原论文中查阅。首先从驱动任务出发,Graphormer来源于Kaggle比赛,是化学分子评分背景。在论文中,主要做了三个化学分子图数据集:
- PCQM4M-LSC
- OGBG-MolPCBA
- OGBG-MolHIV
这里笔者只拿其中一个数据集得结果来分析。
PCQM4M-LSC数据集是量子化学数据集,里面是化学分子,对应得任务是预测给定分子的重要特性HOMO-LUMO间隙,这里不用管这种特性是什么东西,我们只需要知道我们是对这种化学分子进行这种特征的评分就好了。因此,这是一个整个图层面的回归问题。
因此,上面 [VNode] 的设计就非常好,因为它实际上就先当于一个ReadOut层,无需像以往部分研究那样子为了实现图层面任务而添加一个ReadOut层来获取整个图的表征。
再回到这里的实验,根据数据集的统计结果(上面PPT右层)来看,这些化学分子是小图,平均每个图有14个节点,但数据集中包含很多个小图。因此,这个数据集属于小图大数据集。
-
从消融实验结果来看空间编码: 这里的空间编码比Graph上的拉普拉斯位置编码(Laplacian PE)具有更好的性能(MAE:0.1427vs0.1483)。实际上,我们知道空间编码的最短路径实际上就可以通过邻接矩阵来直接计算。虽然这篇论文中没有这方面的对比,但笔者看到下面这位博主自己做的实验:
 注,来源于:Graphormer实验与刷榜
注,来源于:Graphormer实验与刷榜可以看到,SPD换成邻接矩阵Adj.好像差的不是很大。去掉Spatial Encoding效果居然还要好一点。笔者认为对于这种小图来说,复杂的空间编码计算不如带权邻接矩阵来得直接,简单。对小图来说,可能更加简单得编码会更加合适。
-
从消融实验结果来看节点重要性: 从实验结果来看效果还不错(MAE:0.1427vs0.1396)。笔者这里同样也为节点的重要性一般来说对图学习很重要性(主要看图任务哈),因为很多GNN研究也会像这样子把节点的各种中心性加入节点的特征中,此外,还有加入其他节点属性特征的,比如节点的局部连接属性,这里建议看一下图论中节点的属性。
-
从消融实验结果来看边特征引入方式: 可以看出,将边特征编码加入偏置中,对atttion具有更好的性能。为什么好呢,这里上面笔者将边特征编码的时候已经介绍了,这里就不在赘述了。
GraphFormer
论文信息概览
-
paper name:《GraphFormers: GNN-nested Transformers for Representation Learning on Textual Graph》
-
原文链接:https://proceedings.neurips.cc/paper/2021/file/f18a6d1cde4b205199de8729a6637b42-Paper.pdf
-
源码链接:https://github.com/microsoft/GraphFormers
-
来源:中科大, 微软亚洲研究院, NeurIPS
-
数据背景:边预测场景(主要在文本)
-
年限:2021
论文核心要点介绍
背景的了解
GraphFormer的驱动背景是文本图的表示学习(Textual Graph Representation)。那么什么是文本图表示学习呢?文本图的表示学习是基于单个文本特征和邻域信息为节点生成低维嵌入。文本图的表示学习在推荐系统、文本检索中的应用广泛。目前,对文本图的表征学习的主要处理方式为:(1)首先通过预训练语言模型(PLM: Pretrained Language Model)对节点的文本特征进行独立编码; (2)然后通过图神经网络GNN对文本嵌入进行聚合。因此,PLM与GNN的结合是生成高质量文本图表示的主流方法。
那前面我们也介绍了Transformer最初提出的场景是NLP场景。因此,这里的PLM模型也通常采用Transformer来实现。因此,怎么结合Transformer(也就是指这里的PLM)与GNN实现更好的效果? 这也是这篇论文主要的核心点。
要点介绍
在以往的文本图表征研究中,通常借助先几层PLM后GNN的级联架构,如PPT中Figure1中的(A), 即先由 PLM(比如 BERT,Transformer的前身)生成各个节点的文本表示,再借助 GNN(比如 GraphSage)来融合中心节点与邻域的语义。但GraphFormer作者认为这种级联架构是一种相对低效的整合模式。因为在 PLM(Transformer) 的编码阶段,每个节点无法考虑其他邻居节点的信息(文本图领域指语义信息),因此,不利于生成高质量的文本表示。 为此,GraphFormer作者采取了层级化的 PLM-GNN 整合方式,也就是将将 GNN 组件嵌套在 Transformer 语言模型中。如上面PPT中Figure1中的(B)。具体的流程如上面PPT下面的彩图,也就是:
为此,GraphFormer作者采取了层级化的 PLM-GNN 整合方式,也就是将将 GNN 组件嵌套在 Transformer 语言模型中。如上面PPT中Figure1中的(B)。具体的流程如上面PPT下面的彩图,也就是:
- Transformer层编码获取全局信息:首先,在每一层中,每个节点先由各自的 Transformer Block 进行独立的语义编码,编码结果汇总为该层的特征向量(默认由 CLS 所关联的 hidden state 来表征);
- GNN层获取局部/邻居信息:其次,各节点的特征向量汇集到该层的 GNN 模块进行信息整合;之后信息整合的结果会被编码至对应各个节点的图增广(graph augmented)特征向量中,并分发至各个节点;
- 层叠Transformer&GNN:然后,各节点会依照图增广特征向量再进行下一层级的编码,以此层叠。
比前面直接拼接的方式相比,GraphFormers 在 PLM (如Transformer)编码阶段充分考虑了来自GNN中的邻域信息。笔者认为这种结构在文本领域可以更好的融合局部信息和全局信息。
结果概览及分析
因为核心内容主要就是采用层级嵌套的结构,所以下面我们直接看结果吧。这里同样我只放我关注的实验结果。(论文中做的数据集实验主要是“边预测任务“上三个大规模的文本图数据集,因此,这里与前面Graphormer的小图数据集不同是大规模文本数据集)从上面PPT右层的实验结果来看,层级的结构具有更好性能。而且可以发现PLM+Max是次优的,可能数据中Max的影响比较大,或者有部分噪声?
总结
 文章来源:https://www.toymoban.com/news/detail-424918.html
文章来源:https://www.toymoban.com/news/detail-424918.html
下期预告
为了跟上面Graph Transformer的模型做对比,笔者下期将公开自己的另外一篇笔记《GATNE的论文笔记》,而不是图注意力笔记篇章。文章来源地址https://www.toymoban.com/news/detail-424918.html
到了这里,关于【图-注意力笔记,篇章2】Graphormer 和 GraphFormers论文笔记之两篇经典Graph Transformer来入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[自注意力神经网络]Segment Anything(SAM)论文阅读](https://imgs.yssmx.com/Uploads/2024/02/423006-1.png)