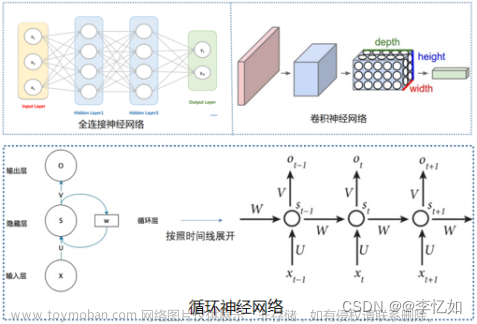
深度学习--RNN基础
RNN(Recurrent Neutral Network,循环神经网络),主要应用于自然语言处理NLP。
RNN表示方法
1.编码
因为Pytorch中没有String类型数据,需要引入序列表示法(sequence representation)对文本进行表示。
表示方法:[seq_len:一句话的单词数,feature_len:每个单词的表示方法]
文本信息的表达方式:
- one-hot:多少个单词就有多少位编码。缺点:非常稀疏(sparse),维度太高,缺乏语意相关性(semantic similarity)
- word2vec
import torch
import torch.nn as nn
word_to_ix = {"hello":0,"world":1}
embeds = nn.Embedding(2,5) #2行5列 一共有2个单词,用5位的feature来表示
lookup_tensor = torch.tensor([word_to_ix["hello"]],dtype=torch.long)
hello_embed = embeds(lookup_tensor)
print(hello_embed)
#tensor([[-0.2169, 0.3653, 0.7812, -0.8420, -0.2815]],
# grad_fn=<EmbeddingBackward0>)
word_to_ix = {"hello":0,"world":1}
embeds = nn.Embedding(2,5) #2行5列 一共有2个单词,用5位的feature来表示
lookup_tensor = torch.tensor([word_to_ix["hello"]],dtype=torch.long)
hello_embed = embeds(lookup_tensor)
print(hello_embed)
#tensor([[-0.2169, 0.3653, 0.7812, -0.8420, -0.2815]],
# grad_fn=<EmbeddingBackward0>)
- glove
from torchnlp.word_to_vector import GloVe
vectors = GloVe()
vector["hello"]
2. batch
两种引入方式:[word num, b, word vec] 或者 [b, word num, word vec ] 第一种常用
RNN原理
naive version
对每一个单词进行 x@w1+b1 操作,每个单词都有不同的参数
Weight sharing
共享参数,用同一个w和b
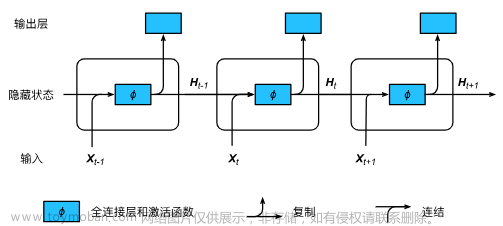
Consistent memory 持续记忆
每一个单词运算表示:x @ wxh +h @ whh
增加了一个h单元,相当于一个memory单元。
总结:
RNN的网络为yt = why*ht
ht=激活函数(Whh* ht-1+Wxh *xt) 常用的为tanh
模型的反向传播:BPTT(back propagation through time)
RNN层的使用方法
run = nn.RNN(100,10) #word vec 单词的表示位数, memory 记忆节点
run._parameters.keys()
#odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
run.weight_hh_l0.shape, run.weight_ih_l0.shape
#(torch.Size([10, 10]), torch.Size([10, 100]))
run.bias_hh_l0.shape, run.bias_ih_l0.shape
#(torch.Size([10]), torch.Size([10]))
1.nn.RNN
nn.RNN(input_size:单词的表示方法维度,hidden_size:记忆的维度:,num_layers:默认是1)
前向传播,一步到位 out, ht = forward(x, h0)
x:[一句话单词数,batch几句话,表示的维度]
h0/ht:[层数,batch,记忆(参数)的维度]
out:[一句话单词数,batch,参数的维度]
import torch
import torch.nn as nn
run = nn.RNN(input_size=100, hidden_size=20, num_layers=1)
print(run)
#RNN(100, 20)
x = torch.randn(10,3,100)
h = torch.zeros(1,3,20)
out,h1 = run(x,h)
print(out.shape,h1.shape)
#torch.Size([10, 3, 20]) torch.Size([1, 3, 20])
2. nn.RNNCell:只完成一个计算
nn.RNNCell(input_size:单词的表示方法维度,hidden_size:记忆的维度:,num_layers:默认是1)
前向传播:ht=rnncell(xt,ht_1)
xt:[batch,word维度]文章来源:https://www.toymoban.com/news/detail-425051.html
ht_1/ht:[层数,batch,参数的维度]文章来源地址https://www.toymoban.com/news/detail-425051.html
#RNNCell
x = torch.randn(10,3,100)
cell = nn.RNNCell(100,20)
h1 = torch.zeros(3,20)
#人为控制一句话的单词数
for xt in x:
print(xt)
h1 = cell(xt,h1)
print(h1.shape)
#torch.Size([3, 20])
到了这里,关于深度学习--RNN基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!