目录
1,目的
2,hive中的操作
2.1创建数据库
2.2,建表并导入数据
2.3,提取需要的数据
2.4,创建新的表并导入上一步所得数据
3,开发web项目
3.1,创建maven的web项目,并导入依赖
3.2,Util工具包
3.3,pojo层
3.4,dao层
3.5,service层
3.6,control层
3.7,配置web.xml
3.8,html页面
4,页面显示
1,目的
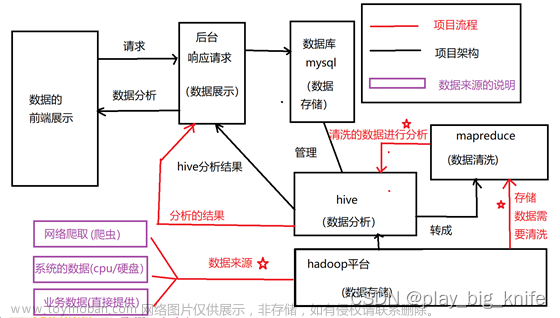
将数据导入到hive中,通过数据分析后将结果存到新的表中,然后读取hive中的数据进行数据可视化。需要项目所需jar包,json文件和js文件以及数据可以关注我的微信公众号大太阳花花公主,在后台回复hive即可。
2,hive中的操作
首先将数据上传到HDFS,然后启动hive,如果因为namenode处于安全模式而无法启动hive可参考我的另一篇博文:
“Name node is in safe mode”的解决方法_大太阳花花公主的博客-CSDN博客
2.1创建数据库
create database nybikedb;2.2,建表并导入数据
注意在创建表之前需要先使用数据库,即use nybikedb;
创建表:
create table tb_trip_06(tripduration int,starttime string,stoptime
string,start_station_id int,start_station_name string,start_station_latitude
double,start_station_longitude double,stop_station_id int,stop_station_name
string,stop_station_latitude double,stop_station_longitude double,bikeid
int,usertype string,birth_year int,gender int) row format delimited fields
terminated by ',';导入数据:
load data inpath 'hdfs://hadoop:9000/201906.csv' overwrite into table
tb_trip_06;
2.3,提取需要的数据
由于项目需求是分析6月份的30天的骑行数据,并对比每天每小时的骑行数量,因此只需要从源数据中提取日期,小时和骑行数量。
select day(starttime),hour(starttime),count(*) from tb_trip_06 group by
day(starttime),hour(starttime) order by `_c0`,`_c1`;_c0, _c1, _c2为临时生成的三个字段,分别表示的是day、hour、 count(日期、小时、数量),需注意的是 _ 是关键字符,如果作为普通字符使用,在外面加上 `
2.4,创建新的表并导入上一步所得数据
创建新表:
create table tb_trip_day_hour_count(day int,hour int,counts int)导入数据:
insert into tb_trip_day_hour_count selectday(starttime),hour(starttime),
count(*) from tb_trip_06 group byday(starttime),hour(starttime) order by `_c0`,`_c1`;3,开发web项目
3.1,创建maven的web项目,并导入依赖
创建maven项目后在webapp目录下创建 data (存放china.json和world.json)和 js 文件夹(存放echarts.js、echarts-gl.js和jquery-1.11.0.min.js)
在pom.xml中导入相关依赖,内容如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.6</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
</dependencies>3.2,Util工具包
在util包中新建一个工具类用于与hive数据库连接。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
//获取hive连接
public class HiveDBUtil {
private static String url="jdbc:hive2://192.168.59.100:10000/nybikedb";
private static String user = "root";
private static String password = "root";
static {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getHiveConn() throws SQLException {
return DriverManager.getConnection(url,user,password);
}
}3.3,pojo层
DayCount与hive中tb_trip_day_hour_count表对应,用于对应后端数据的封装
public class DayCount {
private Integer day;
private Integer hour;
private Integer counts;
public DayCount() {
super();
}
public DayCount(Integer day, Integer hour, Integer counts) {
super();
this.day = day;
this.hour = hour;
this.counts = counts;
}
public Integer getDay() {
return day;
}
public void setDay(Integer day) {
this.day = day;
}
public Integer getHour() {
return hour;
}
public void setHour(Integer hour) {
this.hour = hour;
}
public Integer getCounts() {
return counts;
}
public void setCounts(Integer counts) {
this.counts = counts;
}
@Override
public String toString() {
return "DayCount [day=" + day + ", hour=" + hour + ", counts=" + counts + "]";
}
}
HourCountVO类对应前端数据的封装
import java.util.List;
public class HourCountVO {
private List<Integer> xData;
private List<DayItem> yData;
public HourCountVO() {
super();
}
public HourCountVO(List<Integer> xData, List<DayItem> yData) {
super();
this.xData = xData;
this.yData = yData;
}
public List<Integer> getxData() {
return xData;
}
public void setxData(List<Integer> xData) {
this.xData = xData;
}
public List<DayItem> getyData() {
return yData;
}
public void setyData(List<DayItem> yData) {
this.yData = yData;
}
@Override
public String toString() {
return "HourCount [xData=" + xData + ", yData=" + yData + "]";
}
}
DayItem用于封装每天的数据,其中日期day用于图例。
import java.util.List;
public class DayItem {
private List<Integer> hourData;
private String dataName;
public DayItem() {
super();
}
public DayItem(List<Integer> hourData, String dataName) {
super();
this.hourData = hourData;
this.dataName = dataName;
}
public List<Integer> getHourData() {
return hourData;
}
public void setHourData(List<Integer> hourData) {
this.hourData = hourData;
}
public String getDataName() {
return dataName;
}
public void setDataName(String dataName) {
this.dataName = dataName;
}
@Override
public String toString() {
return "DayItem [hourData=" + hourData + ", dataName=" + dataName + "]";
}
}
3.4,dao层
在dao包中新建一个TripDao接口
import java.util.List;
import pojo.DayCount;
public interface TripDao {
List<DayCount> listCountPreHourOfDay();
}
在dao.impl包中新建一个类用于实现接口TripDao
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import dao.TripDao;
import pojo.DayCount;
import utils.HiveDBUtil;
public class TripDaoHiveTmpl implements TripDao{
public List<DayCount> listCountPreHourOfDay(){
List<DayCount> list = new ArrayList<DayCount>(720);
String sql="select * from tb_trip_day_hour_count";
try {
//获取连接
Connection conn = HiveDBUtil.getHiveConn();
//获取预编译的sql执行对象
PreparedStatement ps = conn.prepareStatement(sql);
//执行sql,获取结果
ResultSet rs = ps.executeQuery();
while(rs.next()) {
int day = rs.getInt("day");
int hour = rs.getInt("hour");
int counts = rs.getInt("counts");
DayCount DC = new DayCount(day,hour,counts);
list.add(DC);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
3.5,service层
在service包中新建一个TripService接口
import pojo.HourCountVO;
public interface TripService {
HourCountVO findCountPreHourOfDay();
}在service.impl包中新建一个类用于实现接口TripService
import Service.TripService;
import dao.TripDao;
import dao.impl.TripDaoHiveTmpl;
import pojo.DayCount;
import pojo.DayItem;
import pojo.HourCountVO;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.TreeSet;
public class TripServiceImpl implements TripService{
private TripDao dao=new TripDaoHiveTmpl();
public HourCountVO findCountPreHourOfDay() {
HourCountVO vo=new HourCountVO();
List<DayCount> list=dao.listCountPreHourOfDay();
Set<Integer> xDataSet = new TreeSet<Integer>();
//声明数组,保存每天的DayItem,数组下标=日期-1
DayItem[] itemArr = new DayItem[31];
for (DayCount dc : list) {
xDataSet.add(dc.getHour());
DayItem item=itemArr[dc.getDay()-1];
if(item==null) {
item = new DayItem();
item.setDataName("6-"+dc.getDay());
item.setHourData(new ArrayList<Integer>(24));
itemArr[dc.getDay()-1]=item;
}
item.getHourData().add(dc.getCounts());
}
List<DayItem> yDataList = new ArrayList<DayItem>();
for (DayItem dayItem : itemArr) {
if(dayItem !=null) {
yDataList.add(dayItem);
}
}
List<Integer> xData = new ArrayList<Integer>(xDataSet);
vo.setxData(xData);
vo.setyData(yDataList);
return vo;
}
}
3.6,control层
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.alibaba.fastjson.JSON;
import Service.TripService;
import Service.impl.TripServiceImpl;
import pojo.HourCountVO;
public class TripServlet extends HttpServlet {
private static final long ServiceVersionUID = 1L;
private TripService service = new TripServiceImpl();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
HourCountVO vo = service.findCountPreHourOfDay();
String jsonStr = JSON.toJSONString(vo);
resp.setContentType("application/json;charset=utf-8");
resp.getWriter().write(jsonStr);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
doGet(req, resp);
}
}
3.7,配置web.xml
在web.xml中添加如下内容:文章来源:https://www.toymoban.com/news/detail-425057.html
<servlet>
<servlet-name>TripServlet</servlet-name>
<servlet-class>control.TripServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TripServlet</servlet-name>
<url-pattern>/trip</url-pattern>
</servlet-mapping>3.8,html页面
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>骑行数据展示</title>
<script type="text/javascript" src="js/echarts.js"></script>
<script type="text/javascript" src="js/jquery-1.11.0.min.js"></script>
</head>
<body>
<div id="main" style="width: 1200px;height: 600px"></div>
<script type="text/javascript">
var url = "http://localhost:8080/Nybike/trip";
$.get(url,function(result){
var xData = result.xData;
var yData = result.yData;
var mySeries = [];
var myLegend = [];
for ( var index in yData) {
var item = yData[index];
var dataName = item.dataName;//6-1
var hourData = item.hourData;
myLegend.push(dataName);
var obj = {
name:dataName,
type:'line',
data:hourData
};
mySeries.push(obj);
}
//初始化的内置对象
var myChart = echarts.init(document.getElementById('main'));
//指定图表的配置项
var option = {
title:{text:'骑行数据显示'},
tooltip:{},
legend:{
bottom:1,
data:myLegend},
toolbox: {
feature: {
magicType: { type: ['line', 'bar'] }}},
xAxis:{
data:xData},
yAxis:{},
series:mySeries,
color:['#FF6699','#FF3366','#CC0066','#CC3366','#CC3399',
'#CC33CC','#CC00FF','#990066','#CC99FF','#993399',
'#666FF','#6699FF','#9966CC','#0099FF','#0066FF',
'#FFCC00','#CC99090','#CC3300','#CC6633','#CC0000',
'#33CCCC','#00CC99','#99FF99','#009966','#66CCCC',
'#00CC00','#009999','#339999','#339999','#CCCC00'],
};
myChart.setOption(option);
});
</script>
</body>
</html>4,页面显示
 文章来源地址https://www.toymoban.com/news/detail-425057.html
文章来源地址https://www.toymoban.com/news/detail-425057.html
到了这里,关于读取hive表中的数据进行数据可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!