目录
一:介绍
一:什么是哈希表
二、哈希表的应用
二:存储结构
a.拉链法:
b.开放寻址法:
三:扩展
a.字符串哈希:
例题:
文章来源地址https://www.toymoban.com/news/detail-425080.html
文章来源:https://www.toymoban.com/news/detail-425080.html
一:介绍
一:什么是哈希表
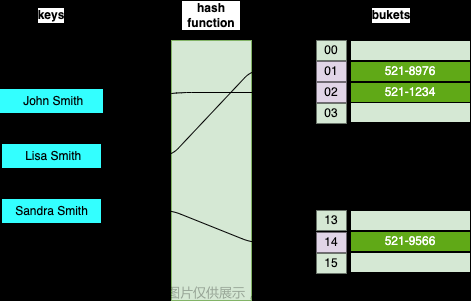
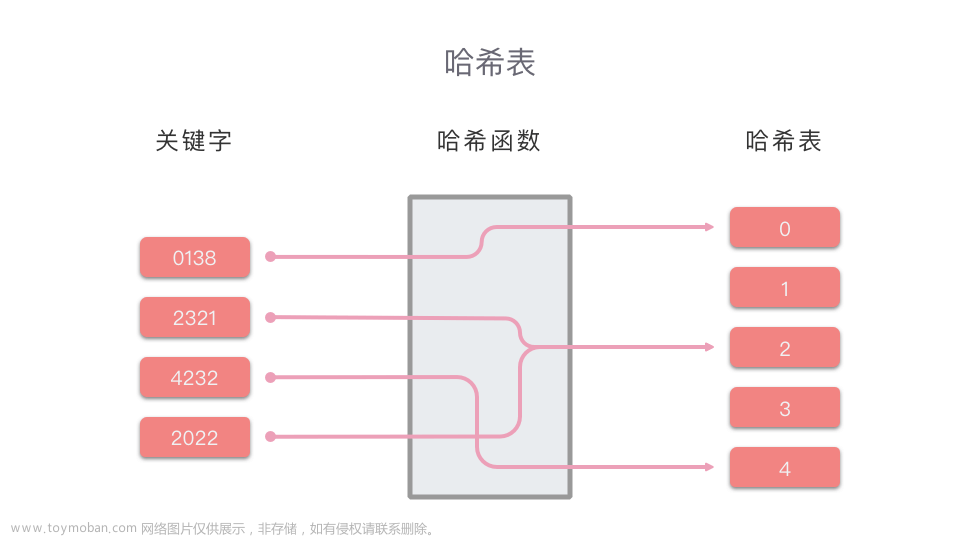
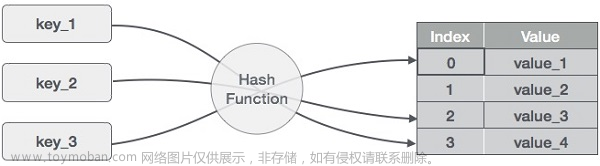
1、哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1),因为哈希表的查找速度非常快,所以在很多程序中都有使用哈希表,例如拼音检查器。
2、哈希表也有自己的缺点,哈希表是基于数组的,我们知道数组创建后扩容成本比较高,所以当哈希表被填满时,性能下降的比较严重。
3、哈希表是由链表和数组组成的:
链表:增删的效率极高,但是查询的效率极低。
数组:查询效率极高,增删效率低
所以哈希表中继承了链表和数组的优缺点,不仅查询效率高,增删效率也高
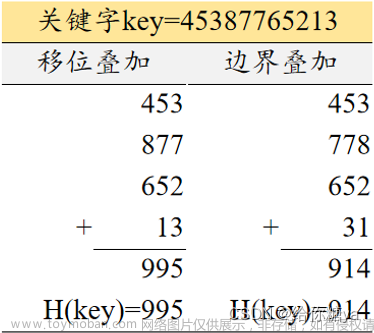
4、哈希表通过键值对的方式存储数据,【key,value】,哈希表会通过散列函数/哈希函数将key转换成对应的数组下标。【采用 先绝对值再% 的方式】
二、哈希表的应用
通常数据都是放在数据库中的,但是有一些数据不需要存放在数据库中 ,太麻烦,那么就需要我们使用缓存层
缓存层一般有俩种:
缓存产品或者自己写一个缓存层(也就是哈希表)
通过一个列子自己构建出哈希表:
看一个实际需求,google公司的一个上机题:
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址..),当输入该员工的id时,要求查找到该员工的 所有信息.
要求: 不使用数据库,尽量节省内存,速度越快越好
思路:
1、首先要求不使用数据库,那么是能用一些缓存产品用来存储数据,所以需要构建一个哈希表
2、哈希表有数组,链表组成。在链表中保存员工数据信息,数组中保存链表
二:存储结构
哈希表的最主要作用是将一个比较大的范围(如10^9)映射到一个比较小的空间(0 ~ N,其中N一般为10^5 - 10^6),通过一个哈希函数h(x)完成上述操作。
这里很容易产生哈希冲突,可能会把若干不同的数映射为同一个数。处理冲突的方法有两种:开放寻址法和拉链法。
a.拉链法:
开辟一个10^5大小的空间,每个空间相当于一个槽,每次映射到某个位置就在下面连接一条链。
其实就是单链表的存储方式。
拉链法是把所有的同义词用单链表链接起来的方法。在这种方法中,哈希表的每个单元存储的不再是元素本身,而是相应同义词单链表的头指针(注意是头指针而不是头节点)。
对于单链表,我们算法比赛可以采用数组的方式进行实现。
(1) 拉链法
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100003;
int n;
int h[N], e[N], ne[N], idx;
// 向哈希表中插入一个数
void insert(int x)
{
int k = (x % N + N) % N; //哈希函数。这里防止k为负数且映射到小范围
e[idx] = x; //单链表的插入
ne[idx] = h[k];
h[k] = idx ++ ;
}
// 在哈希表中查询某个数是否存在
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i]) //遍历
if (e[i] == x)
return true;
return false;
}
int main(){
scanf("%d", &n);
// 初始化链表(链表中-1代表NULL)
memset(h, -1, sizeof h);
while(n--){
char op[2];
int x;
scanf("%s %d", op, &x);
if(*op == 'I'){
insert(x);
}
else{
if(find(x)) puts("Yes");
else puts("No");
}
}
}
b.开放寻址法:
找厕所坑位
(2) 开放寻址法
#include <iostream>
#include <cstring>
using namespace std;
// 约定一个null值作为标准,如果h数组上的某个位置等于这个标准的话,就说明这个位置是空的
// 要求这个数不在 -10^9 <= x <= 10^9 范围内即可
const int N = 200003, null = 0x3f3f3f3f;
int n;
int h[N];
int find(int x){
int k = (x % N + N) % N;
// 该位置有人且值不为x,就要向后看
while(h[k] != null && h[k] != x){
k++;
if(k == N) k = 0;
}
return k;
}
int main(){
scanf("%d", &n);
memset(h, 0x3f, sizeof h);
while(n--){
char op[2];
int x;
scanf("%s %d", op, &x);
if(*op == 'I') h[find(x)] = x;
else{
if(h[find(x)] == null) puts("No");
else puts("Yes");
}
}
return 0;
}memset函数解释
三:扩展
a.字符串哈希:
当key为字符串时,h(key)称为字符串哈希。
将字符串看成一个p进制的数,将它转化为十进制数再对Q取模,即可得到一个映射到0-Q范围内的数
-
不能将字符映射成0:例如将"A"映射成0,则"AA","AAA"的值均为零。所以应当从1开始。
-
经验值:p=131 || 13331,Q=2^64时几乎没有冲突 //利用 unsigned long long,它的大小就是2^64,这样我们就无需进行取模的操作了,因为它溢出后就相当于帮我们取模了。
我们可以通过求前缀哈希,通过某一个公式求出任意子串的哈希值:
string: _______|__________|__________
高位 L R 低位
现在已知h[R]和h[L - 1]
我们有:
h[R] = p^R-1 * "_" + p^R-2 * "_" + ... + p^0 * "_"
h[L - 1] = p^L-2 * "_" + p^L-3 * "_" + ... + p^0 * "_"
容易知道只需:h[R] - h[L - 1]*p^(R - L + 1)
就能求得L-R间子串的哈希值
同时由上面的字符串哈希的定义,有:
h[i] = h[i - 1]*p + str[i];
例题:
AcWing 841.字符串哈希
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2,请你判断[l1,r1]和[l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。
第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
int n, m;
char str[N];
ULL p[N], h[N];
ULL find(int l, int r){
return h[r] - h[l - 1] * p[r - l + 1];
}
int main(){
scanf("%d %d", &n, &m);
// str从str[1]开始填入数据,因为h[i] = h[i - 1]*p + str[i]、h[0] = 0
scanf("%s", str + 1);
p[0] = 1;
for(int i = 1; i <= n; i++){
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + str[i];
}
while(m--){
int l1, r1, l2, r2;
scanf("%d %d %d %d", &l1, &r1, &l2, &r2);
if(find(l1, r1) == find(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}
到了这里,关于【数据结构】哈希表(算法比赛向)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!