1 概述
select count(*) from tb_user ;在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)。
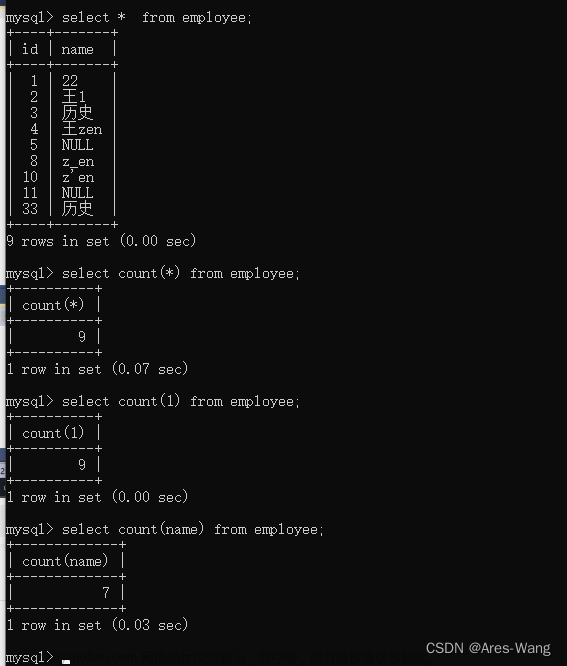
2 count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
| count用法 |
含义 |
| count(主键)文章来源:https://www.toymoban.com/news/detail-425362.html |
InnoDB文章来源地址https://www.toymoban.com/news/detail-425362.html |
到了这里,关于SQL优化(6):count优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!