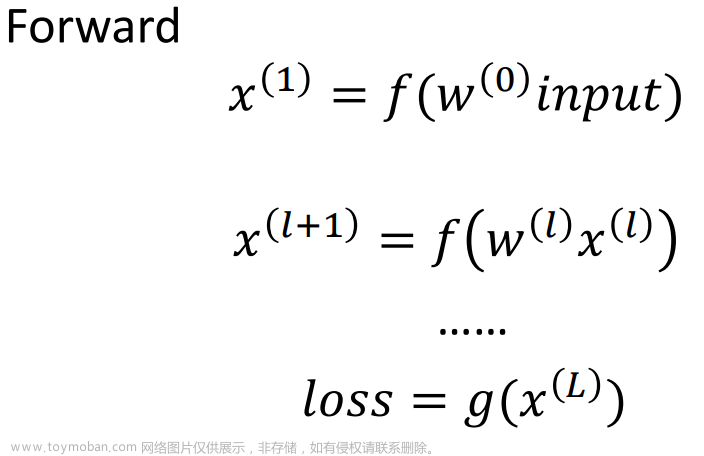常见的人工神经网络结构
人工神经网络是一类由人工神经元组成的网络,常见的神经网络结构包括:
前馈神经网络(Feedforward Neural Network,FNN):最简单的神经网络结构,由一个输入层、一个输出层和若干个隐藏层组成,信号只能从输入层流向输出层,不允许在网络中形成回路。
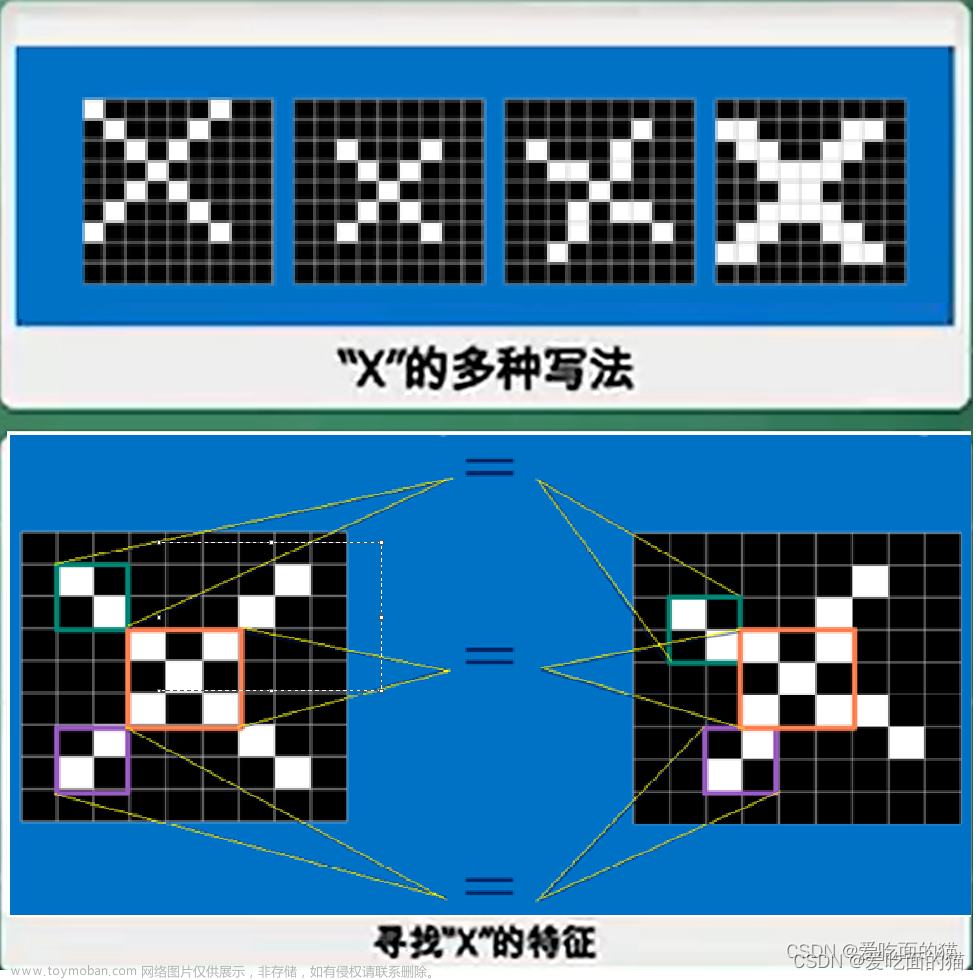
卷积神经网络(Convolutional Neural Network,CNN):适用于图像、语音和自然语言等数据的处理,通过卷积运算提取图像的局部特征,避免参数过多的问题。
循环神经网络(Recurrent Neural Network,RNN):适用于序列数据的处理,如自然语言、音频、视频等,可以在网络中形成时间循环的结构,便于处理变长的序列数据。
长短期记忆网络(Long Short-Term Memory,LSTM):是一种特殊的RNN结构,可以解决传统RNN中梯度消失的问题,对于长时间序列数据的建模有很好的效果。
自编码器(Autoencoder,AE):用于数据降维、特征提取和数据重建,通过训练网络使得输入数据和输出数据之间的误差最小。
生成对抗网络(Generative Adversarial Network,GAN):用于生成新的数据,由一个生成器和一个判别器组成,通过博弈的方式不断提高生成器生成数据的质量。
注意力机制网络(Attention Mechanism,AM):用于序列数据中的注意力权重计算,能够对输入的不同部分进行不同程度的关注,以提高模型的性能。
胶囊网络(Capsule Network,CapsNet):一种新型的神经网络结构,通过胶囊(Capsule)来表示目标的属性和姿态,具有较强的几何变换不变性。
神经网络模型
神经网络是一种基于生物神经系统的计算模型,它由大量的神经元(节点)组成,每个神经元可以接收多个输入信号,并将它们加权求和,再通过一个激活函数处理得到输出。神经网络通过输入数据和反馈机制,不断调整各个节点之间的权重,从而实现学习和预测功能。
在神经网络中,通常包括输入层、隐藏层和输出层。输入层负责接收数据,隐藏层进行特征提取和数据转换,输出层输出预测结果。神经网络模型的层数和节点数不同,可以设计出各种不同的网络结构。
神经网络模型的训练过程一般通过反向传播算法来实现,该算法利用误差反向传递的方式,计算出每个节点对误差的贡献,从而调整节点之间的权重,以使误差最小化。为了防止过拟合和提高模型的泛化能力,还可以通过正则化、dropout等技术进行优化。
神经网络模型在各种领域中得到了广泛应用,如图像识别、语音识别、自然语言处理、推荐系统等。
卷积神经网络
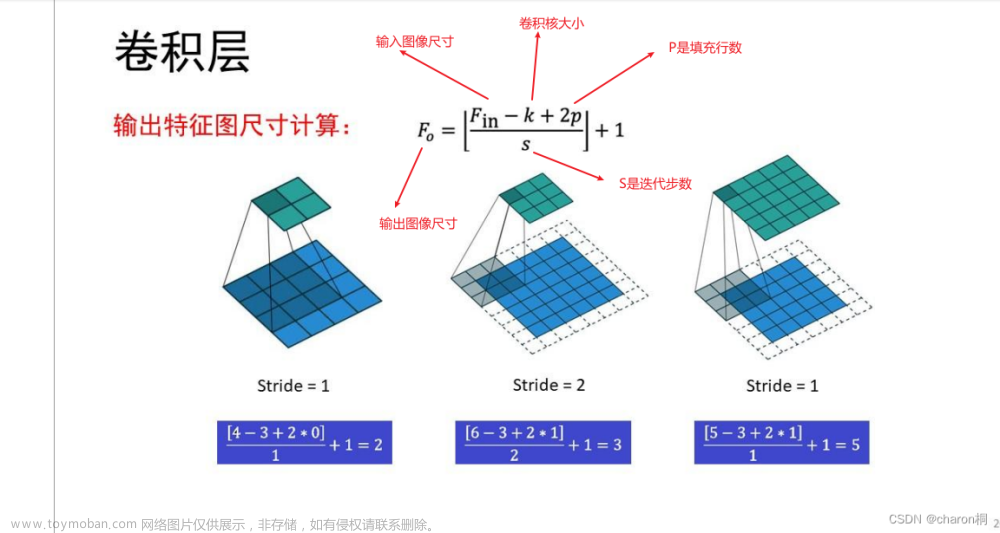
卷积是一种在信号处理和图像处理中常用的数学运算,它可以对两个函数进行加权积分,其中一个函数通常是输入数据,另一个函数则是卷积核(也称为过滤器),用于从输入数据中提取特征。
在CNN中,卷积操作是一种对输入数据进行特征提取的核心操作,它可以通过将卷积核与输入数据进行卷积操作,从而得到提取后的特征。在卷积操作中,卷积核在输入数据上进行滑动,对输入数据的每个位置进行加权求和,最终得到输出特征图。
import numpy as np
input_data = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
kernel = np.array([[0, 1],
[2, 3]])
output = np.zeros((2, 2))
for i in range(2):
for j in range(2):
output[i, j] = np.sum(input_data[i:i+2, j:j+2] * kernel)
print(output)
前馈神经网络
前馈神经网络是一种最常用的深度学习神经网络,也称为多层感知机。它的主要作用是通过从输入层到输出层的多个隐藏层来学习从输入到输出之间的映射关系。它不具备反馈机制
import numpy as np
class NeuralNetwork:
def __init__(self, layers):
self.weights = []
self.biases = []
self.num_layers = len(layers)
self.activation = sigmoid
# 初始化权重和偏置
for i in range(1, self.num_layers):
self.weights.append(np.random.randn(layers[i], layers[i-1]))
self.biases.append(np.random.randn(layers[i], 1))
def feedforward(self, x):
a = np.array(x).reshape(-1, 1)
for w, b in zip(self.weights, self.biases):
z = np.dot(w, a) + b
a = self.activation(z)
return a
def train(self, X, y, epochs, alpha):
for i in range(epochs):
for j in range(len(X)):
x = X[j]
y_true = y[j]
# 前向传播
a = np.array(x).reshape(-1, 1)
activations = [a]
zs = []
for w, b in zip(self.weights, self.biases):
z = np.dot(w, a) + b
zs.append(z)
a = self.activation(z)
activations.append(a)
# 反向传播
delta = (activations[-1] - y_true) * sigmoid_derivative(zs[-1])
for l in range(2, self.num_layers):
delta = np.dot(self.weights[-l+1].T, delta) * sigmoid_derivative(zs[-l])
# 更新权重和偏置
for l in range(self.num_layers - 1):
self.weights[-l-1] -= alpha * np.dot(delta, activations[-l-2].T)
self.biases[-l-1] -= alpha * delta
def predict(self, X):
pred = []
for x in X:
pred.append(self.feedforward(x))
return np.array(pred)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
这个实现中,我们使用sigmoid激活函数,并且使用随机初始化权重和偏置。 feedforward 方法用于前向传播, train 方法用于训练,并且使用反向传播算法来更新权重和偏置, predict 方法用于预测。
当然可以,以下是对代码逐行的解析:
import numpy as np
导入必要的库,包括numpy。
class NeuralNetwork:
def __init__(self, layers):
self.weights = []
self.biases = []
self.num_layers = len(layers)
self.activation = sigmoid
# 初始化权重和偏置
for i in range(1, self.num_layers):
self.weights.append(np.random.randn(layers[i], layers[i-1]))
self.biases.append(np.random.randn(layers[i], 1))
定义一个 NeuralNetwork 类,它有一个构造方法 init 。 layers 参数是一个表示神经网络每一层神经元数量的列表, num_layers 表示神经网络的层数, weights 和 biases 分别表示权重和偏置。在这个构造方法中,我们使用随机初始化权重和偏置。
def feedforward(self, x):
a = np.array(x).reshape(-1, 1)
for w, b in zip(self.weights, self.biases):
z = np.dot(w, a) + b
a = self.activation(z)
return a
定义 feedforward 方法来进行前向传播。 x 表示输入, a 表示在每一层中的激活值。在这个方法中,我们对每一层的权重和偏置进行矩阵乘法和加法运算,并使用激活函数将结果传递到下一层。最终返回输出值 a 。
def train(self, X, y, epochs, alpha):
for i in range(epochs):
for j in range(len(X)):
x = X[j]
y_true = y[j]
# 前向传播
a = np.array(x).reshape(-1, 1)
activations = [a]
zs = []
for w, b in zip(self.weights, self.biases):
z = np.dot(w, a) + b
zs.append(z)
a = self.activation(z)
activations.append(a)
# 反向传播
delta = (activations[-1] - y_true) * sigmoid_derivative(zs[-1])
for l in range(2, self.num_layers):
delta = np.dot(self.weights[-l+1].T, delta) * sigmoid_derivative(zs[-l])
# 更新权重和偏置
for l in range(self.num_layers - 1):
self.weights[-l-1] -= alpha * np.dot(delta, activations[-l-2].T)
self.biases[-l-1] -= alpha * delta
定义 train 方法来进行训练。 X 和 y 分别表示输入和目标输出, epochs 表示训练轮数, alpha 表示学习率。在每个轮次中,我们使用前向传播计算每一层的输出,并在每层记录激活值和加权输入值。然后,我们使用反向传播算法计算权重和偏置的更新量,并使用学习率更新权重和偏置。
def predict(self, X):
pred = []
for x in X:
pred.append(self.feedforward(x))
return np.array(pred)
定义 predict 方法来进行预测。 X 表示输入, pred 表示预测输出。文章来源:https://www.toymoban.com/news/detail-425569.html
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
定义sigmoid激活函数和sigmoid的导数。文章来源地址https://www.toymoban.com/news/detail-425569.html
到了这里,关于卷积神经网络与前馈神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!