前言
YOLOv5🚀出到第七个版本了( •̀ ω •́ )✧,同时支持图片分类、目标检测与实例分割;我们在跑通过模型训练与推理后,可以尝试改进模型😀,或者根据任务需求来修改网络结构与损失函数等等。
本文分享一下,在模型结构方面,如何快速理解源码。
https://github.com/search?q=yolov5
一、整体代码思路(模型结构)
工程代码中,模型结构是在models目录中,其中:
- common.py 存放各个模型组件
- yolo.py 构建模型结构的主代码
- xxx.yaml 存放不同大小的模型结构配置(包括:yolov5s.yaml 、yolov5m.yaml、yolov5l.yaml、yolov5x.yaml等
它们之间的关系是:yolo.py调用common.py中的模型组件,同时解析yolov5s.yaml中的模型配置,来构建模型(backbone + head)
下面首先分享xxx.yaml的模型配置文件,再讲common.py的模型组件,最后讲yolo.py结构的主代码。
二、模型配置文件xxx.yam
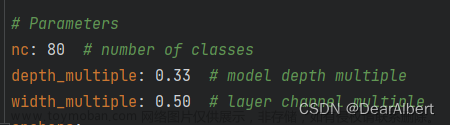
这里以yolov5s.yaml为示例,它首先定义了一些模型超参数,包括类别、模型深度系数、模型宽度系数、三组初始框(anchors)。
- nc 类别:这个根据实际修改;比如COCO是80分类,nc填写80;如果是2分类,nc填写2.
- depth_multiple 模型深度系数:这是对模型的深度(层数)进行缩放,比如A模型组件中,本来是有10层卷积组成的,在构建时需要乘以这个深度系数,即:10 * 0.33 = 3.3,四舍五入后,为3层。那么实际构建时,只使用3层卷积操作。
- width_multiple 模型宽度系数:这是对模型的宽度(通道数)进行缩放,比如B模型组件中,本来的通道数为90,在构建时需要乘以这个宽度系数,即:90 * 0.50 = 45,四舍五入后,为45。那么实际构建时,通道数为45进行的。
- anchors 初始框:有大中小三组框,每一组各有三个框,参数指定了框的宽高;
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# 定义一些模型超参数
nc: 80 # 类别
depth_multiple: 0.33 # 模型深度 系数
width_multiple: 0.50 # 模型宽度 系数
anchors:
- [10,13, 16,30, 33,23] # P3/8 用于检测小目标的三个初始框(anchors)
- [30,61, 62,45, 59,119] # P4/16 用于检测中目标的三个初始框(anchors)
- [116,90, 156,198, 373,326] # P5/32 用于检测大目标的三个初始框(anchors)
下面看看backbone 主干网络,from是指当前模块组件的输入来自那里,number是指模块重复数量,module是模块组件的名称,args是创建模型需要的参数
# YOLOv5 v6.0 backbone 主干网络
backbone:
# [from, number, module, args] # from是指输入来自那里,number是指模块重复数量,module是模块组件的名称,args是创建模型需要的参数
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 第0层,相对原图做了2倍下采样
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 第1层,相对原图做了4倍下采样
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 第3层,相对原图做了8倍下采样
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 第5层,相对原图做了16倍下采样
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 第7层,相对原图做了32倍下采样
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9 第9层
]
from中,通常都是-1的值,它是指来自上一层;
如果是[5, 3, C3, [128]],from的值是5,说明该模型的输入是5-P4/16。
number,是指模块重复数量,通常都是1的值,它是指该模块只重复1遍;
如果是[5, 3, C3, [128]],number的值是3,说明该模块,由C3组件连续重复3遍而组成。
module,是模块组件的名称;比如C3、Conv、SPPF等(具体定义在common.py找到)
args,是创建模型需要的参数,
比如在Conv中,对于的参数含义为:(输入通道数, 输出通道数, 卷积核大小kernel, 步长stride, 填充数padding, 分组数量groups, 扩张率dilation, 激活函数activation)
初始值:def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True)
比如 [-1, 1, Conv, [128, 3, 2]],输出通道数128,卷积核大小为3,步长为2。
下面看看head 检测头,它对backbone中提取出来的特征,进一步融合,最后输出到检测头中;检测头由三个分支组成。
# YOLOv5 v6.0 head 检测头
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small) 检测小目标 分支
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) 检测中目标 分支
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large) 检测大目标 分支
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) 三个检测分支
]
其中,解释一下 [[17, 20, 23], 1, Detect, [nc, anchors]]
[17, 20, 23] 是指Detect输入来自17层、20层、23层的特征图
1 是指 Detect模块只重复一次
Detect 是指模块的名称为Detect
[nc, anchors] 是只创建Detect模块所需的参数(类别数、三组初始框anchors)
三、模型组件common.py
common.py定义了各组模型组件,包括:
- Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,
- DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
- C3, C3TR, C3SPP, C3Ghost, DWConvTranspose2d, C3x
- TransformerBlock、Expand等等
通过这些组件来构建YOLO模型(backbone + head),比如看一下常用的Conv:
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))它的模块组件名称为Conv,它的结构,由卷积、归一化、激化函数组成的。
模块定义所需的参数:def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True)
这和xx.yaml配置文件中的 [-1, 1, Conv, [256, 1, 1]] 参数是对应的,输出通道数256,卷积核大小为1,步长为1
四、构建模型结构主代码yolo.py
YOLOv5🚀出到第七个版本了( •̀ ω •́ )✧,同时支持图片分类、目标检测与实例分割;其中yolo.py 这个代码是模型结构的重点!!!
- DetectionModel 类,是定义目标检测的模型结构
- SegmentationModel 类,是定义实例分割的模型结构
- ClassificationModel 类,定义了图片分类的模型结构
首先重点讲一下目标检测 DetectionModel 类,后面有时间再补充实例分割、图片分类。
在yolo.py中,还能看到定义了Detect类(head 检测头)、BaseModel类(backbone 主干网络),和parse_model函数(解析xxx.yaml构建模型结构)
目标检测 DetectionModel = (BaseModel + Detect)
4.1 parse_model函数
下面解释一下parse_model函数
它用于解析一个 YOLOv5 模型配置文件(比如:yolov5s.yaml)。函数名为 parse_model,接受两个参数 d 和 ch,其中 d 是模型配置文件的字典表示,ch 是输入图像的通道数。
思路流程:
- 解析模型配置文件的各项参数,包括 anchors(锚框),nc(类别数目),gd(模型深度系数),gw(模型宽度系数),act(激活函数)等等。
- 分别遍历模型配置文件中的 backbone 和 head 部分。
- 根据配置文件中的参数,创建模型的各个层(如 Conv、Bottleneck、nn.BatchNorm2d 等)。
parse_model函数中的第一部分:
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # 如果配置文件指定了激活函数,会根据配置文件的函数去加载, 比如: Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}")
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # anchors数量
no = na * (nc + 5) # 输出通道数量 = anchors * (classes + 5)-
第一行代码:是打印日志,把yolov5s.yaml中的内容显示出来;
-
第二行代码:从模型配置文件的字典
d中(yolov5s.yaml)获取锚点(anchors)、类别数(nc)、模型深度系数(gd)、模型宽度系数(gw)、激活函数(act)等参数,并将其赋值给相应的变量anchors、nc、gd、gw、act。 -
第三行代码:如果配置文件中指定了激活函数(
act),则将其通过eval()函数重新定义为Conv.default_act,即重定义默认的激活函数为nn.SiLU(),并使用日志记录LOGGER.info()输出激活函数的信息。 -
第六行代码:计算出锚点的数量
na。如果锚点是一个列表,则取第一个锚点列表的长度的一半作为锚点的数量;如果锚点是一个数值,则直接使用该数值作为锚点的数量。 -
第七行代码:根据锚点数量、类别数等参数计算出模型输出层的通道数量
no,即anchors * (classes + 5),其中anchors是锚点的数量,classes是类别数,5 是包括目标置信度、边界框坐标等信息的预测数目。
parse_model函数中的第二部分:
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings这段代码主要是对一个包含多层网络模块的列表进行循环遍历,分别遍历backbone 和 head。
-
定义了三个变量
layers、save和c2,并分别初始化为空列表[],空列表[]和列表ch的最后一个元素ch[-1]。 -
使用
for循环遍历d['backbone'] + d['head']列表中的元素,每个元素都表示一个网络模块。其中f表示 "from"(该模块输入来自哪里),n表示 "number"(模块的重复次数),m表示 "module"(模块的名称),args表示 "arguments"(创建模块所需的参数)。 -
对于每个网络模块,将
m(模块的名称)通过eval()函数进行评估操作,如果m是字符串类型,则将其转换为相应的 Python 对象。这里使用eval()函数来将字符串类型的模块名转换为实际的模块对象,从而可以在后续的代码中使用。 -
对于
args列表中的每个元素a,同样使用eval()函数进行评估操作,将字符串类型的参数值转换为相应的 Python 对象。这里使用with contextlib.suppress(NameError)来捕获可能出现的NameError异常,以防止字符串参数无法成功评估的情况。
parse_model函数中的第三部分:
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
#主要讲下面的代码
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]这段代码是对模型的网络层进行解析和处理的部分。
- 首先对输入的深度参数 n 进行计算得到新的深度 n_,计算方式为将 n* gd(depth_multiple)并进行四舍五入,但至少为 1。
- 然后根据不同的模块类型 m 进行不同的处理:
- 如果 m 是 Conv、GhostConv、Bottleneck、GhostBottleneck、SPP、SPPF、DWConv、MixConv2d、Focus、CrossConv、BottleneckCSP、C3、C3TR、C3SPP、C3Ghost、nn.ConvTranspose2d、DWConvTranspose2d、C3x 中的一种,需要更新参数 args,并进行一些处理。
- 如果 m 是 nn.BatchNorm2d,只需要更新参数 args。
- 如果 m 是 Concat,需要计算并更新参数 c2。
- 如果 m 是 Detect 或 Segment,需要更新参数 args,并进行一些处理。
- 如果 m 是 Contract,需要根据 args[0] 计算并更新参数 c2。
- 如果 m 是 Expand,需要根据 args[0] 计算并更新参数 c2。
- 对于其他的模块类型,直接更新参数 c2。
比如,A模型组件中,本来是有10层卷积组成的(n = 10),在构建时需要乘以这个深度系数0.33(gd = 0.33),即:10 * 0.33 = 3.3,四舍五入后,为3层。那么实际构建时,只使用3层卷积操作。
parse_model函数中的第四部分:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)这段代码主要涉及对模型的不同类型的处理,并将处理后的模型添加到layers列表中,并更新一些变量
-
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args):根据n的值判断是否需要将m模型包装在nn.Sequential中,然后将m模型与args参数传递给m的构造函数,生成一个新的模型m_。 -
t = str(m)[8:-2].replace('__main__.', ''):将模型m的类型转换成字符串,并进行字符串处理,提取模型类型信息,将模型类型保存在变量t中。 -
np = sum(x.numel() for x in m_.parameters()):计算模型m_的参数总数,将结果保存在变量np中。 -
m_.i, m_.f, m_.type, m_.np = i, f, t, np:将模型的索引i、'from'索引f、类型t和参数数量np保存在模型m_的属性中。 -
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}'):打印模型的信息,包括索引i、'from'索引f、重复次数n_、参数数量np、类型t和参数args。 -
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1):将f中不为-1的值加入到savelist中,其中如果f是整数,则将其作为列表处理。 -
layers.append(m_):将处理后的模型m_添加到layers列表中。 -
if i == 0: ch = []:如果当前模型的索引i为0,则将ch列表清空。 -
ch.append(c2):将变量c2添加到ch列表中。
4.2 BaseModel 类
BaseModel 类是用来构建backbone的,定义了一些方法:
- 用于前向推理计算(forward、_forward_once),用于单尺度推理和训练时的前向传播计算。
- 单层性能分析(_profile_one_layer),用于分析每个层的性能。
- 模型融合(fuse),用于融合模型中的 Conv2d() 和 BatchNorm2d() 层,以减少计算量。
- 模型信息打印(info),用于打印模型的信息,包括层的类型、输入输出维度、运算时间、浮点运算次数等。
- 张量转换(_apply),用于对模型中的张量应用转换,如 to()、cpu()、cuda()、half() 等操作。
在前向推理计算中,forward函数会调用_forward_once和_profile_one_layer进行前向推理的模型构建。
- 在前向计算方法
_forward_once中,模型中的每个层被遍历并执行运算。如果一个层的输入不是来自于前一层,则输入是来自于模型中之前的某一层。 - 其中使用
self.model列表存储了模型中的所有层,_forward_once函数则遍历所有层,按照顺序逐层计算并将每层的输出保存到列表y中。 - 如果设置了
profile,则会调用_profile_one_layer方法来对当前层进行性能分析,记录时间和浮点运算次数。在每一层的输出被保存后,如果设置了可视化,则会将当前层的特征图保存到指定路径下。
class BaseModel(nn.Module):
# YOLOv5 base model
def forward(self, x, profile=False, visualize=False):
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
单层性能分析(_profile_one_layer),用于分析每个层的性能。该函数使用thop库计算每层的FLOPs,使用time_sync函数计算每层的时间消耗,并输出每层的时间、FLOPs和参数信息。
def _profile_one_layer(self, m, x, dt):
c = m == self.model[-1] # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
下面是模型融合(fuse)、模型信息打印(info)、张量转换(_apply)
# 用于融合模型中的 Conv2d() 和 BatchNorm2d() 层,以减少计算量
def fuse(self):
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn)
delattr(m, 'bn')
m.forward = m.forward_fuse
self.info()
return self
# 用于打印模型的信息,包括层的类型、输入输出维度、运算时间、浮点运算次数等。
def info(self, verbose=False, img_size=640):
model_info(self, verbose, img_size)
# 用于对模型中的张量应用转换,如 to()、cpu()、cuda()、half() 等操作
def _apply(self, fn):
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
4.3 Detect类
用于构建YOLOv5目标检测模型中的检测头部,负责生成检测结果。其中类中有以下三个函数:
-
__init__(self, nc=80, anchors=(), ch=(), inplace=True): 初始化函数,用于构建Detect类的对象。nc表示类别数量,anchors表示锚框的坐标,ch表示输入特征图的通道数,inplace表示是否使用原地(inplace)操作。该方法会初始化模型的各个属性,并构建模型的卷积层。 -
forward(self, x): 前向传播函数,用于生成检测结果。输入参数x是一个包含多个特征图的列表。在前向传播过程中,模型会对输入的每个特征图进行卷积操作,然后根据检测结果的格式,生成相应的输出。如果处于训练模式,返回卷积层的输出;如果处于推理模式,返回生成的检测结果。 -
_make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')): 用于生成网格坐标和锚框在特征图上的坐标。nx和ny分别表示特征图的宽度和高度,i表示当前特征图的索引,torch_1_10是一个用于检查 torch 版本的函数,用于选择不同的方式生成网格坐标,以保持兼容性。该方法会返回网格坐标和锚框在特征图上的坐标。
看一下__init__中的变量含义:
class Detect(nn.Module):
stride = None # 检测层的步长
dynamic = False # 表示是否强制进行网格重构
export = False # 表示是否处于导出模式
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # 类别数
self.no = nc + 5 # 每个锚框的输出通道数,等于类别数加上5(x、y、w、h、confidence)
self.nl = len(anchors) # 检测层的数量
self.na = len(anchors[0]) // 2 # 每个检测层的锚框数量
self.grid = [torch.empty(0) for _ in range(self.nl)] # 用于存储生成的网格,初始值为空tensor
self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # 用于存储生成的锚框,初始值为空tensor
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # 用于输出检测结果的卷积操作
self.inplace = inplace # 是否使用inplace操作
Detect类的前向传播函数forward接收一个输入x,其中x是一个列表,包含了多个尺度的特征图(3个分支)。在前向传播过程中,对每个特征图进行处理(检测头部分):
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
if isinstance(self, Segment): # (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
else: # Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, self.na * nx * ny, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)代码解析:
- 初始化一个空列表
z,用于保存推断(inference)输出。 - 进行一个循环,循环次数为
self.nl,self.nl是模型中的层数。 - 对每一层进行前向传播计算:
- 调用
self.m[i](x[i])对输入x[i]进行卷积计算,其中self.m[i]是第 i 层的卷积层。 - 将
x[i]的形状从(bs,255,20,20)转换为(bs,3,20,20,85),其中bs是 batch size,255是特定的通道数,20是特定的高度和宽度,85是特定的预测目标数量和属性数。 - 使用
view函数将x[i]进行形状变换,变换为(bs, self.na, self.no, ny, nx),其中self.na是 anchor boxes 的数量,self.no是预测的目标属性数量,ny和nx是特定的高度和宽度。 - 使用
permute函数对维度进行重排列,变换为(bs, 1, ny, nx, self.no),其中第二个维度 1 对应于 anchor boxes 的数量self.na。 - 使用
contiguous函数使数据在内存中连续存储,以便进行后续计算。 - 根据是否处于训练模式(
self.training),进行不同的推断处理:- 如果处于推断模式(
self.training为 False):- 检查是否需要动态调整 anchor boxes 的网格大小或者 anchor boxes 是否需要重新生成,如果需要,则调用
_make_grid函数进行生成。 - 根据模型是否属于
Segment类进行不同的处理:- 如果是
Segment类,则将x[i]进行分割,分别得到xy、wh、conf和mask,分别表示预测的目标的中心坐标、宽高、置信度和掩码(分割结果)。 - 如果不是
Segment类,那些是Detect,则将x[i]进行目标检测,分别得到xy、wh和conf,分别表示预测的目标的中心坐标、宽高和置信度。 - 对
xy进行 sigmoid 函数计算,然后乘以 2 并加上网格坐标,再乘以self.stride[i]进行缩放,得到预测的目标的中心坐标xy。 - 对
wh进行 sigmoid 函数计算,然后将结果平方并乘以self.anchor_grid[i]进行缩放,得到预测的目标的宽高wh。 - 使用
torch.cat函数将xy、wh、conf.sigmoid()和mask拼接在一起,形成预测的目标信息y。 - 将
y进行形状变换,变换为(bs, self.na * nx * ny, self.no),其中bs是 batch size,self.na是 anchor boxes
- 如果是
- 检查是否需要动态调整 anchor boxes 的网格大小或者 anchor boxes 是否需要重新生成,如果需要,则调用
- 如果处于推断模式(
- 调用
解析代码1: Segment: (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
这段代码使用了 PyTorch 中的
split函数,用于将张量x[i]沿着指定的维度(在这里是第4维,通道维度)进行切分,并将切分后的子张量赋值给变量xy,wh,conf, 和mask。
x[i]是一个形状为(bs, na, ny, nx, no)的张量,其中:
bs表示 batch size,即批次大小;na表示每个位置的 anchor 数量;(每个网格默认3个)ny表示特征图的高度;nx表示特征图的宽度;no表示每个 anchor 预测的输出通道维度数量。
split函数接受一个元组作为参数,其中包含了要切分的张量x[i]在第4维上(通道维度)的切分位置,以及切分后的子张量的数量。在这里,切分位置是(2, 2, self.nc + 1, self.no - self.nc - 5),表示从第4维的索引0开始,切分长度分别为2、2、self.nc + 1、self.no - self.nc - 5,总共切分为4个子张量。切分后的子张量分别赋值给
xy,wh,conf, 和mask,其中:
xy是包含了预测的边界框在特征图上的中心坐标的张量;wh是包含了预测的边界框在特征图上的宽度和高度的张量;conf是包含了预测的边界框的置信度的张量;mask是包含了预测的边界框的分割掩码信息的张量。这段代码的作用是从输入张量
x[i]中将预测的边界框的中心坐标、宽度和高度、置信度以及掩码信息分别提取出来,并赋值给相应的变量,以便后续处理和使用。
解析代码2:
为什么是self.no - self.nc - 5?
self.no表示每个 anchor 预测的输出的通道维度数量,而self.nc则表示每个 anchor 预测的类别数量。在这段代码中,使用了
self.no - self.nc - 5作为切分的长度,是因为在 YOLO 模型中,每个 anchor 预测的输出包括了边界框的位置信息(中心坐标、宽度和高度)、是否包含物体的置信度以及类别概率。其中,边界框位置信息需要4个维度来表示(2个维度表示中心坐标,2个维度表示宽度和高度),置信度需要1个维度来表示,而类别概率根据类别数量self.nc而定。所以,
self.no - self.nc - 5表示在剩余的维度中,预测的边界框掩码信息的长度,用于将输入张量x[i]切分成xy,wh,conf, 和mask这四个子张量。这个长度的计算是基于 YOLO 模型的设计和输出维度的特点,可能在不同的模型中会有不同的值。
解析代码3:Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
这段代码使用了 PyTorch 中的
split函数,用于将张量x[i]沿着指定的维度(在这里是第4维,通道维度)进行切分,并将切分后的子张量赋值给变量xy,wh,conf。
x[i]是一个形状为(bs, na, ny, nx, no)的张量,其中:
bs表示 batch size,即批次大小;na表示每个位置的 anchor 数量;(每个网格默认3个)ny表示特征图的高度;nx表示特征图的宽度;no表示每个 anchor 预测的输出通道维度数量。xy = (xy * 2 + self.grid[i]) * self.stride[i]
这段代码是对目标框的中心坐标进行计算和转换的操作。
xy是通过x[i]中的前两个通道进行切片得到的目标框的中心坐标预测值,其形状为(bs, ny, nx, 2),其中bs是 batch size,ny和nx分别是输入特征图的高度和宽度,2 表示中心坐标的 x 和 y 分量。self.grid[i]是预先计算的网格坐标偏移值,其形状与xy相同,用于将目标框的中心坐标从特征图空间映射到输入图像空间。self.stride[i]是预先定义的特征图相对于输入图像的步长,用于将目标框的中心坐标进行缩放。这段代码的计算过程为:
- 将
xy乘以 2,然后加上self.grid[i],实现从特征图空间到输入图像空间的映射。- 将结果乘以
self.stride[i],实现对目标框中心坐标的缩放。最终,
xy存储了转换后的目标框中心坐标值。wh = (wh * 2) ** 2 * self.anchor_grid[i]
这段代码计算了预测框的宽高信息。
- 首先,
wh乘以2,再将其平方,最后乘以self.anchor_grid[i]。self.anchor_grid[i]是一个锚框(anchor box)的尺寸,用于调整预测框的宽高。- 在目标检测算法中,锚框是一些预定义的框,用于在不同尺度和长宽比下对图像进行采样和预测。通常情况下,锚框的尺寸和比例是根据数据集和任务需求进行设置的。
这段代码的目的是对预测框的宽高信息进行调整和缩放,以便与图像实际尺寸相匹配。最终的
wh张量将包含经过缩放后的预测框的宽高信息,用于后续的目标检测任务。y = torch.cat((xy, wh, conf), 4)
这段代码使用
torch.cat()函数将xy、wh和conf三个张量在第4维度(即通道维度)上进行拼接,生成一个新的张量y。这三个张量在这段代码中按顺序进行拼接,生成一个新的张量
y,其中包含了预测框的信息,包括预测框的中心点坐标、宽高和置信度。
在forward函数中会调用_make_grid函数,它用于生成 anchor boxes 在输入图像上的网格。
def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibility
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid函数的参数含义:
-
nx和ny分别表示在 x 和 y 方向上的网格数量,默认值为 20。 -
i表示当前 anchor boxes 的索引,默认值为 0。 -
torch_1_10是一个布尔值,用于检查 torch 版本是否大于等于 1.10.0,这是通过调用check_version()函数来实现的。
函数思路流程:
- 首先,函数根据
self.anchors[i]的设备和数据类型创建了y和x张量,分别表示 y 和 x 方向上的网格索引。 - 接着,通过调用
torch.meshgrid()函数生成了网格张量yv和xv,其中ij索引方式在 torch 版本大于等于 1.10.0 时生效,否则使用默认的索引方式。这里生成了一个二维的网格,其中yv表示 y 方向上的网格索引,xv表示 x 方向上的网格索引。 - 然后,通过调用
torch.stack()函数将xv和yv沿着第三个维度(索引从 0 开始)堆叠在一起,得到一个形状为(ny, nx, 2)的网格张量。 - 接着,网格张量
grid被扩展为与 anchor boxes 数量和维度相同的形状(1, self.na, ny, nx, 2),并且每个网格点都减去了 0.5 的偏移量,即grid = torch.stack((xv, yv), 2).expand(shape) - 0.5。 - 最后,anchor boxes 张量
self.anchors[i]被乘以对应的步长self.stride[i],并且形状被调整为(1, self.na, 1, 1, 2),然后扩展为与网格张量相同的形状(1, self.na, ny, nx, 2),得到了 anchor boxes 在输入图像上的坐标。 - 函数返回了两个张量,分别是
grid和anchor_grid,它们分别表示 anchor boxes 在输入图像上的网格坐标和相对于输入图像的坐标。
其中,x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
思路流程:
使用
.view(bs, self.na, self.no, ny, nx)对x[i]进行形状变换,将其变为5维张量,其中bs是batch size,self.na是每个grid cell中anchor的数量,self.no是每个anchor预测的输出通道数,ny和nx分别是grid的高度和宽度。使用
.permute(0, 1, 3, 4, 2)对5维张量进行维度置换,将最后一个维度(2)移到第五个维度位置,从而变为(bs, self.na, ny, nx, self.no)的形状。使用
.contiguous()将维度连续化,以确保后续操作的正确性。最终,
x[i]的形状被变换为(bs, self.na, ny, nx, self.no),在这个形状下,可以方便地对anchor的预测信息进行处理和解析。文章来源:https://www.toymoban.com/news/detail-425916.html
4.4 DetectionModel类
还没写完,待完善更新~文章来源地址https://www.toymoban.com/news/detail-425916.html
到了这里,关于YOLOv5代码解析——模型结构篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!