pytorch快速入门
csdn快速入门
https://blog.csdn.net/PolarisRisingWar/article/details/116069338
- 工具箱dir() 、help() 或者 类名??、 ipython交互式操作
- pycharm 的好处就是可以看到实时变量的值
OS包
- os.path.join() 拼接路径
- os.listdir( ) 返回目录下的文件列表
PIL包
- from PIL import Image 导入
- Image.open(path) 读取图片,读出的图片类型是JepgImageFile类型
- img.show() 显示
Opencv包
- import cv2
- cv2.imread() 读出的图片类型是numpy
Dataset类
-
自定义的data类要继承Dataset类
-
self相当于一个全局变量,以便类中每个函数共享使用,否则就不需要写
eg 数据集url蚂蚁蜜蜂分类数据集和下载连接https://download.pytorch.org/tutorial/hymenoptera_data.zip
from torch.utils.data import Dataset from PIL import Image import os class MyData(Dataset): def __init__(self,root_dir,label_dir): self.root_dir = root_dir self.label_dir = label_dir self.path = os.path.join(self.root_dir,self.label_dir) self.img_path=os.listdir(self.path) #img_path='/Users/fanzhilin/Downloads/hymenoptera_data/train/ants/0013035.jpg' def __getitem__(self,idx): img_name = self.img_path[idx] img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) img =Image.open(img_item_path) label = self.label_dir return img,label def __len__(self): return len(self.img_path) ants_dataset =MyData('/Users/fanzhilin/Downloads/hymenoptera_data/train','ants') print(len(ants_dataset))#ants训练集长度
Tensorboard的使用
需要先转换成tensor类型才能显示
-
add_scalar()
eg 画出y=2x图
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")# 放在当前目录logs目录,可以自己改名字
# 画出 y =2x
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
打开logs文件,在终端运行 tensorboard --logdir=logs ,也可以指定端口–port 6007, 便可以通过网页访问
- add_image()、add_images()一次添加多个图片
查看def,需要传入 (torch.Tensor, numpy.array, or string/blobname)类型的y轴数据,需要把图片类型转换一下,从PIL到numpy arrary,需要传入参数dataformats=‘HWC’ 指定每一维的含义
eg
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
img_path="/Users/fanzhilin/Downloads/hymenoptera_data/train/ants/0013035.jpg"
img_PIL =Image.open(img_path)
img_arrary = np.array(img_PIL)
print(img_arrary.shape)
writer.add_image("ant",img_arrary,1,dataformats='HWC')#从PIL到numpy arrary,需要传入参数dataformats='HWC' 指定每一维的含义
# 画出 y =2x
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
torchvision.transforms 的使用
就是一个工具箱
使用注意点⚠️
-
ToTensor类 ,为什么需要转换?包含了一些dl的参数
-
Normalize类,归一化
-
Resize类
transforms.Resize(x)等比例缩放,将图片短边缩放至size,长宽比保持不变,i.e,如果高度>宽度,则图像将被重新缩放为(size*高度/宽度,size)将图片短边缩放至x,长宽比保持不变 transforms.Resize(x)
-
Compose 就是将函数进行组合,需要提供一个转换的列表,相对应合并执行
-
RandomCrop 随机裁剪 ,用于数据增强
from torchvision import transforms from PIL import Image from torch.utils.tensorboard import SummaryWriter img_path="/Users/fanzhilin/Downloads/hymenoptera_data/train/ants/0013035.jpg" img=Image.open(img_path) writer=SummaryWriter("logs") #ToTensor trans_tensor = transforms.ToTensor()# 创建对象 img_tensor=trans_tensor(img)#变为tensor writer.add_image("Totensor",img_tensor,0 ) #Normalize print(img_tensor[0][0][0]) trans_norm = transforms.Normalize([0.5,0.5,0.5],[2,1,1]) img_norm=trans_norm(img_tensor) print(img_norm[0][0][0]) writer.add_image("Normalize",img_norm,0 ) #Resize print(img.size) trans_resize=transforms.Resize((512,512)) img_resize = trans_resize(img)#PIL 类型 img_resize=trans_tensor(img_resize)#想要在tensorboard显示需要变成tensor类型 writer.add_image("Resize",img_resize,0) print(img_resize.size()) # Compose resize 结合 trans_resize2 = transforms.Resize(512) trans_compose = transforms.Compose([trans_resize2,trans_tensor]) img_resize2 = trans_compose(img) writer.add_image("Resize",img_resize2,1) #RandomCrop trans_random=transforms.RandomCrop(400) #(h,w)传入也可以 trans_compose2= transforms.Compose([trans_random,trans_tensor]) for i in range(10):#随机裁剪10个 img_crop = trans_compose2(img) writer.add_image("RandomCrop",img_crop,i) writer.close()
torchvision中数据集的使用
-
datasets
官网数据集https://pytorch.org/vision/stable/datasets.html
可以吧url拷贝,用迅雷下载

import torchvision
dataset_trans=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)#把数据集每一个全变成tensor,方便使用tensorboard显示
train_set = torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=dataset_trans,download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=dataset_trans,download=True)
#如果root没有目录会自动建立,建议设置download=true,如果没有回下载到本地,并且会自动解压
print(train_set[0])#第一条
print(train_set.classes)#label
img,traget=train_set[0]#打印查看格式,前一个是img,后一个是label
print(img)
print(traget)
print(test_set.classes[traget])
img.show()
DataLoader的使用(torch.utils.data)
类似抽牌
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#batch_size = 4 从dataset取4个数据,打包返回
#shuffle = True 每次抽取都是随机的
#drop_last=False,最后一次取如果不够取不舍去
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)#打包返回的数据torch.Size([4, 3, 32, 32]) 4数据 3通道rgb h w
# print(targets)#tensor([5, 9, 2, 4]) 是label
writer.add_images("Epoch :{}".format(epoch),imgs,step)
step=step+1
writer.close()
神经网络的搭建nn.Module
Eg 简单的nn
from torch import nn
import torch.nn.functional as F
import torch
class Model(nn.Module):
def __init__(self):
super().__init__()
#nn.module内的call方法里调用了forward,通过打断点也可以知道!
def forward(self,input):
return input+1
nn1=Model()
x= torch.tensor(1)
print(nn1(x))
卷积操作
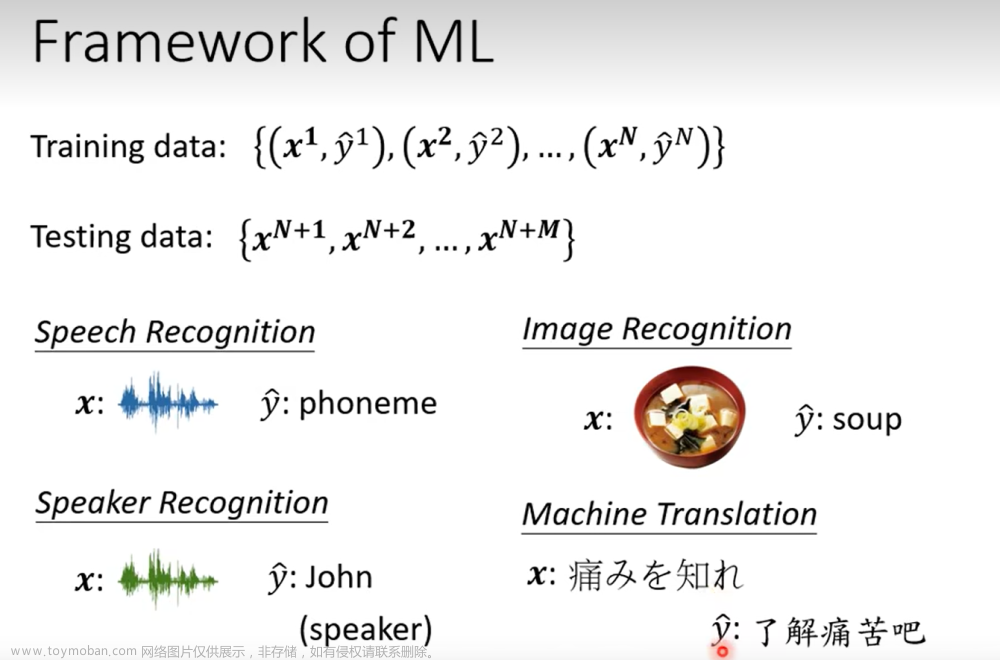
深度学习 李宏毅
2022太乱了,去youtube看2020了,妈的没弹幕看着难受
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML20.html
python 多环境管理pyenv
https://github.com/pyenv/pyenv
https://zhuanlan.zhihu.com/p/36402791
Chatgpt
1 研究方向
1如何精准提出需求
- 如何调教
2 如何更正错误
- chatgpt的预训练资料只有2021年9月之前的
- 如何让机器修改一个错误而不弄错别的地方?——Neural editing
3 判断是否ai生成的物件
4是否会泄漏隐私
- 但是可以绕着弯问他,当问到一定特定问题,让机器忘记Machine Unlearning
2 Chatgpt学习的步骤
由InstructGPT 推测
-
1学习文字接龙,学到的是几率分布,然后随机抽取一个词出来。但实际每次输出的结果都不同
GPT在网络上大量搜集网络数据,不需要人介入
-
2人类来引导接龙的方向,并提供正确答案,
-
3模仿人类的喜欢
-
4用增强式学习 强化学习学习 reward
3 Fine tune vs. Prompt
两个方向:成为通才 或 专才
-
所有自然语言处理的问题都是 问答QA的问题

https://arxiv.org/abs/1806.08730
-
让chatgpt自己说说如何针对特定任务产生prompt

期待一 |成为专才, 加外挂 or fine tune or Adapter
BERT,类似文字填空的模型

对预训练模型进行改造
-
加外挂Head

-
微调参数 fine tune
…
微调Adapter 的参数( efficient finetune)
语言模型本身不动,只finetune微调adapter参数

期待二|成为通才
in-context learning 范例学习
- 可能范例学习只对大型模型有明显效果
题目叙述学习Instruct learning、 instruction tuning
-
T0模型

-
FLAN paper

chain of thought (COT )Promptting
-
在给机器范例同时,顺便给出推论过程,给出答案

-
zero - shot COT 甚至直接可以一句话:Lets think step by step
有的时候人也不知道解答的过程是什么

-
Self—consistency 解决每次结果都不一样

-
Leat - to - most promptting
把复杂的问题拆解,把难的问题简化,看到数学问题,让机器做in context learing
让机器找prompt
-
soft prompt 我们给机器的prompt 是向量,可以train,类似于adapter
-
用reinforcement learning
-
直接用大型LM 去自己找prompt
把输入 输出 给他 ,让LM去给出prompt ,自己催眠自己😵💫
一、 Regression回归
Overfitting and Regularization
-
loss function 加上正则化项,不需要考虑bias b的大小
我们要找一个比较平滑的f,而调整b的大小与f的平滑没关系,只是上下移动
-
lamda越大,train 损失越大,在test 可能越小
lamda越大,说明越偏向考虑w本来的数值,而减少考虑error;
我们喜欢较为smooth的function,但不能太平滑
-
正则化在loss func再加上一个item, 会希望你的参数越小越好,希望曲线越平滑越好,w权重代表希望有多平滑
误差error是哪里来的?——寻找调整方法
来源于一个bias 一个variance
类似于射击,f*是预估的func 、f bar— 是期望、 f hat 是真实值

跟据bias和varience大小关系,有underfitting 、overfitting,

-
如果undercutting ,则bias大
- 添加更多的feature
- 设计更复杂的model
-
如果overfitting,则variance大
- 收集更多的data、数据增强
- 正则化Regularization
注意不要这样做!——数据集的划分

真正的测试数据集是没见过的,你在test set的loss不能真实反映
引入validation验证集,解决方法如下
Cross Validation

N-fold Cross Validation

Gradient Descent
复习


1. learning rate 的调整
-
1 普通的调整方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V3ibQGTU-1680872290781)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230328164435356.png)]
一个learning rate ,越来越小,才能收敛
-
2 Adagrad —adaptive learning rate
不同参数的learning rate不一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i3qu9gz4-1680872290781)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230328180147015.png)]
每一个参数都有一个learning rate
-
η \eta η 是学习率,是constant 常量
-
g 是偏微分的值,是gradient 梯度 斜率
-
σ \sigma σ 是w过去所有 偏微分值的均方根(先取平均值,然后开根号 root mean square)
-
t 代表第t次更新
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vo8sJ7Vv-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401201113476.png)]
-
简化adagrad
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o00TpdKc-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401201227539.png)]
解释为什么要除以g?应该是g越大step要越大,应该是成正比啊?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eTI1S6t4-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401201601336.png)]
直观解释,除是为了看看反差有多大
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lb7r6niD-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401201538408.png)]
详细解释:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3jnD3Xdy-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401230936384.png)]
-
2 SGD 随机梯度下降(Stochastic Gradient Descent
随机梯度下降(Stochastic Gradient Descent,SGD)是一种优化算法,用于训练机器学习模型。与传统的梯度下降算法不同,SGD在每次更新模型参数时,只使用一小部分随机样本来计算梯度,而不是使用所有训练样本。这使得SGD比传统梯度下降更快速地收敛,特别是在大规模数据集上。
具体地说,SGD的算法流程如下:
- 从训练数据中随机选择一小批样本(通常称为minibatch);
- 计算这个minibatch中样本的梯度;
- 使用梯度来更新模型参数;
- 重复1-3步骤,直到满足停止条件(例如达到最大迭代次数或梯度变化很小)。
SGD通常具有更好的泛化性能,因为在每次迭代中,它都会使用不同的训练样本进行更新。此外,SGD通常可以处理更大的数据集,因为它不需要在每次迭代中使用所有的训练数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xJOP8Pfv-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401231714549.png)]
3 Feature Scaling 特征缩放
让不同的feature 的scale 一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9browA1K-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401231914179.png)]
-
为什么要这样做?
w1对y的影响比较小,对loss影响小,有比较小的微分,w1方向比较平滑!!
GD时没有向着圆心,效率不高
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bN1uHpwL-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401232239402.png)]
-
如何做feature scaling
涉及到均值和方差
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EszppKNz-1680872290782)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401232356938.png)]有两种常见的特征缩放方法:
-
归一化(Normalization):归一化通常是将特征值调整到 [0, 1] 范围内。公式如下:
x_normalized = (x - min(x)) / (max(x) - min(x))
其中 x 是待归一化的特征值,min(x) 和 max(x) 分别表示特征值的最小值和最大值。
-
标准化(Standardization):标准化是将特征值调整为均值为 0,标准差为 1 的分布。这样处理后的特征值服从标准正态分布。公式如下:
x_standardized = (x - mean(x)) / std(x)
其中 x 是待标准化的特征值,mean(x) 表示特征值的平均值,std(x) 表示特征值的标准差。
4 数学原理
https://www.youtube.com/watch?v=yKKNr-QKz2Q 50分处
5 GD的一些限制limitation
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tVmqOigs-1680872290783)(/Users/fanzhilin/Library/Application Support/typora-user-images/image-20230401234026897.png)]
二、Classification 分类
2.1 生成式模型(generative model)
https://www.bilibili.com/video/BV1Wv411h7kN?p=16&spm_id_from=pageDriver&vd_source=1fef0ac13db9fd03e4b2ae788361b5c4 神奇宝贝预测
高斯分布
朴素贝叶斯法(Naive Bayes model)
2.1.1协方差矩阵(Covariance Matrix)
协方差矩阵(Covariance Matrix),用于描述多个随机变量之间的协方差关系。协方差是一个衡量两个随机变量线性相关程度和它们各自变化程度的指标。具体来说,如果两个变量的协方差为正值,说明它们随着各自的增加而同增或同减;如果协方差为负值,则表示一个变量的增加对应另一个变量的减小,反之亦然;如果协方差接近于零,说明两个变量之间没有显著的线性关系。
对于 n 个随机变量(X₁,X₂,…,Xₙ),它们的协方差矩阵是一个 n×n 的矩阵,其中第 i 行第 j 列的元素表示随机变量 Xᵢ 和 Xⱼ 之间的协方差,记作 Cov(Xᵢ, Xⱼ)。协方差矩阵可以表示为:
Cov(X) = [Cov(X₁, X₁) Cov(X₁, X₂) ... Cov(X₁, Xₙ)]
[Cov(X₂, X₁) Cov(X₂, X₂) ... Cov(X₂, Xₙ)]
[ ... ... ... ... ]
[Cov(Xₙ, X₁) Cov(Xₙ, X₂) ... Cov(Xₙ, Xₙ)]
协方差矩阵的对角线上的元素表示每个随机变量的方差(即该变量与自身的协方差),而其他元素表示不同随机变量之间的协方差。协方差矩阵是对称的,即 Cov(Xᵢ, Xⱼ) = Cov(Xⱼ, Xᵢ)。
在多元统计分析、信号处理、金融风险管理等领域,协方差矩阵常用于分析多个随机变量之间的线性关系。此外,在机器学习和数据挖掘中,协方差矩阵也用于特征选择、降维(如主成分分析,PCA)和判别分析等任务。
2.2 逻辑回归 判别式模型(discriminative model)
2.2.1 function set
前面讲了概率问题,简化直接找wb
posterior probability:后验概率

逻辑回归其实就是一种神经网络

2.2.2 Goodness of function 好坏
-
最大似然估计MLE 找到一组w b 以最大化Lwb 即机率
注意这里的L不是损失函数而是似然函数,是让这个training data 在现有概率下找到一组参数,最能拟合这种现有情况

做一个数学转换,找最大转为找最小,让计算容易

-
二分类交叉熵你Cross entropy
代表的是这两个distribution 有多接近

-
总结对比

为什么逻辑回归的损失函数不用均方误差MSE?
——左边的推导基础是最大似然函数,而最大似然函数最大化的对象就是概率的乘积,为什么是乘积呢?多个独立事件同时发生的概率就是乘积。所以,左边的loss function求最大值的基础是最大似然函数的求解
从loss图像理解

用cross entropy 可以让train更顺,更新参数更快些,因为离目标远的话微分大、跨的步子也大
2.2.3 find the best function 寻找参数
很奇妙,更新参数的式子与线性回归是一样的
总结:

只不过逻辑回归的 y ^ \hat{y} y^ 是1 或者0
2.3 辨别模型VS生成模型
logistic=discriminative,gaussian=generative,逻辑回归是特殊的Gaussian

-
判别式模型和生成式模型,一个根据与目标函数的损失函数来直接找最合适的w和b,一个根据w和b的生成方式先计算相关参数间接的计算出合适的w和b
-
虽然是来自同一个function set ,两种模型找到的不是同一组wb
右侧等于直接给定了一个从概率上考量的最佳的w,b。而左侧是随便给你个w,b初值,然后用梯度下降找最优解
-
discriminative model 的performance 一般会更好一些,但不一定所有情况
解释:
比如朴素贝叶斯naive bayes,他会先脑补
逻辑回归可直接建模预测P(c|x), 概率模型先假定满足某种分布,然后建模,用先验概率(prior probability)求其后验概率
=》可以理解为,逻辑回归自动学习特征之间的关系。概率模型假定特征之间符合某种关系
生成式模型基于假设分布不断修正,在data少的时候performance好一些

2.4 Multi-class Classification
归一化函数softmax =》max指的是对最大值进行强化!

- 多分类流程总结如下:

交叉熵:用于计算两个模型之间的相似度,完全相同的熵为0
y ^ \hat{y} y^ :这样编码的好处就不像123 这样有距离远近问题
2.5Limitation of Logistic Regression
-
有的时候逻辑回归有限制

因为逻辑回归在二分类问题找的是一个直线的boundary,

2.5.1 f eature transformation
-
解决方法:
1 feature transformation特征转换

但我们人工不好去做这件, 能不能自动做?
2 .cascading logistics regression models 级联逻辑回归模型

eg 3个逻辑回归接在一起,可以模拟边界


这就是引入神经网络了,多层感知器。svm就是利用核技巧。两种方式都可以解决这个问题
三、DL 深度学习简介
3.1 DL的步骤

3.1.1 Fully Connected Feedforward Network 全连接前向传播神经网络、前馈神经网络
-
一个神经元就可以看做一个function

如果没有固定的参数叫做function set ,就是我们要找的
当每一层有好多神经元时候

-
整个神经网络的运算过程—矩阵运算

矩阵运算可以用GPU运算加速
hidden 层对feature进行了提取,最后经过softmax:归一化函数输出分类结果

3.1.2 定义一个function goodness 好坏— cross entropy 交叉熵
-
对于手写1 -10 识别

我们去计算 y y y 和 y ^ \hat{y} y^的cross entropy C n C^n Cn ,调整网络参数,让total loss最小
这是一个居中的独立公式:
E = m c 2 E = mc^2 E=mc2
-
用GD 梯度下降找参数
下面的 μ \mu μ 是学习率

如何算微分?因为参数很多,利用toolkit 如pytorch ——backpropagation 是一种有效的方式
为什么要用deep neural network?
3.2 Backpropagation 反向传播
-
为什么需要bp?
方便计算神经网络参数的微分
3.2.1 Chain Rule 链式求导
3.2.2 BP过程推导
-
对于total loss 我们只要算出一笔data的C对w微分,然后sum 起来就行全部的

我们先分析一个神经元的情况,对w求偏微分,b同理,根据chain rule

先看第一部分forward pass :z对w求偏导,得出的值就是上一个神经元的输出的值,秒算

第二部分backward pass :
C是cost 总的代价函数、 σ \sigma σ 是activation function 激活函数

假设上面?已经算出来,可以写作

想象一下,有这样一个类似于神经元的东西

如何计算这两项?
- 如果后面紧接着就是输出层 显然好算

- 如果后面还有很多层,继续往后走 ,得算出后面的才能知道当前的

为了有效率,我们从后往前算,先把后面的算出来
-
Bp总结

3.3 机器学习任务攻略
3.3.1 在training data 上loss 过大? 过小?
- Genral Guide

-
在training 上loss 大
不一定是overfitting啊!
model bias:指的是一层神经网络上的神经元个数不够,不能拟合出适合的函数。
training loss 大,判断到底是model bias 还是optimization 的问题?

下面一些情况是Optimization 的问题

-
在training data的 loss 小
在testing data loss大 ,是过拟合overfiting,机器并没有学到真正的function

如何解决overfitting?
-
-
搜集更多资料,但是不建议
-
data augmentation 数据增强
-
constrained model 限制模型、更少神经元、共享参数、半失活神经元来减少过拟合
-
正则化 regularization
-
更少的feature
-
dropout

-
-
3.3.2 N-fold Cross Validation
在做HW时,遵循下面的方法,引入验证集
测试集参与参数选择,导致结果有偏,不具有参考价值。所以引入验证集。

不要根据测试集调模型,永远不要让测试集参与模型训练,不然会overfit到testing set上,不用管public testing set 结果,用validation set 上loss最小的model就行
Nfold Cross Validation N折交叉验证

交叉验证是为了降低验证集随机取的,正好是都不够靠近描述函数的值的可能性
3.4 神经网络训练不起来怎么办?
3.4.1 local minima 局部最小值和 saddle point 鞍点
-
training loss 不下降的原因

-
梯度为0只能说明是critical point!如何判断是哪一种情况?
泰勒展开式逼近
H海塞矩阵 hessian Hij 代表 θ i \theta~i θ i 对L做微分 , θ j \theta~j θ j 对L做微分 ,做两次微分就可以得到

如何判断到底是哪种?

我们只要算出H矩阵,看他的eigen value 特征值情况
矩阵的特征值 λ \lambda λ 的正负!
-
例子

-
遇到了鞍点,不要害怕!
一种解决方法:H告诉了我们参数更新的方向,找到负的特征值对应的一个特征向量u,来更新theta,就可以让loss变小

例子:

但是的确实不用看,计算量实在是太大
-
一般我们训练都是卡在了saddlepoint
下面的例子说明最终在loss不动了时候,特征值也不是全是正的

3.4.2 批次batch
-
什么是batch、epoch

-
为什么要用batch
-
从技能冷却角度想象
大大batch并不一定慢,GPU有并行运算文章来源:https://www.toymoban.com/news/detail-426392.html
 文章来源地址https://www.toymoban.com/news/detail-426392.html
文章来源地址https://www.toymoban.com/news/detail-426392.html
-
到了这里,关于李宏毅 深度学习【持续更新】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[PyTorch][chapter 9][李宏毅深度学习][Why Deep]](https://imgs.yssmx.com/Uploads/2024/01/822871-1.png)




