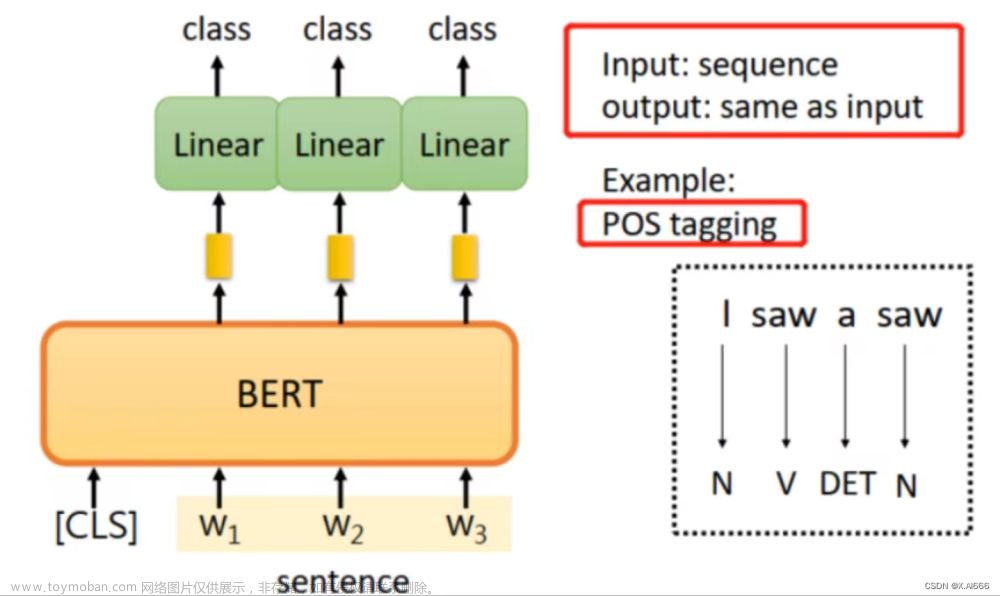
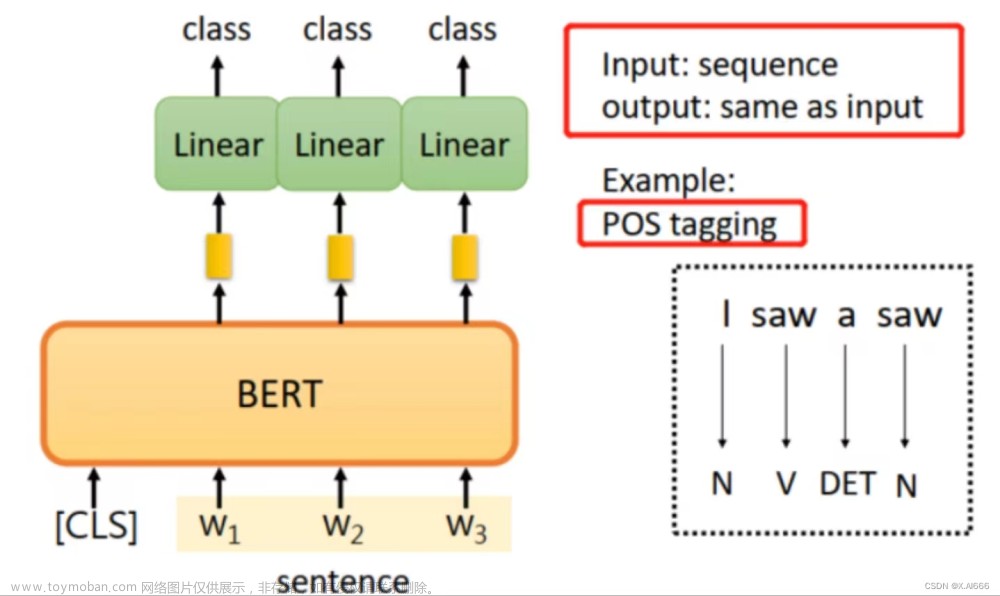
模型总结:
-
T5:基于Transformer,结合了多任务学习和无监督预训练,并使用大规模的英文维基百科语料库进行训练。
-
GPT-3:同样基于Transformer,使用了极其庞大的语料库,并使用Zero-shot学习实现了自然语言推理功能。
-
Chinchilla:一种新型自然语言生成模型,使用了自适应正则化和动态使用的注意力机制。
-
PaLM:结合了单向和双向模型的优势,并使用了双向训练和带有附加任务的预训练,取得了相当好的效果。
-
LLaMA:一种自然语言理解模型,将语言建模作为先验,利用目标任务的语言和概率建模优化网络参数。
-
Alpaca:一种基于元学习的多任务学习模型,能够快速应用于新的NLP任务中。
-
ELECTRA:一种新颖的预训练模型,使用“替代观察”方法学习语言表示,取得了较好的效果。
-
Roberta:使用更多的训练数据、更长的训练时间和更大的模型尺寸,结合了动态蒸馏和其他技术取得了很好的效果。
-
BART:结合了语音识别和机器翻译的技术,并使用了双向编码器-译码器结构,取得了很好的效果。
-
UniLM:利用纵向与横向预训练机制,融合了语言生成和语言理解,可适用于多种自然语言处理任务。
-
GShard:一种支持大规模分布式训练的Transformers框架,可在多台GPU上进行训练,性能非常好。
-
LSDSem:一个基于多层次探测的语义依存分析模型,同时考虑了句法和语义信息。
-
BertRank:一种用于对话式搜索的模型,基于BERT的双塔架构,使用了多任务学习和局部注意力机制,取得了较好的效果。
-
BERT-DP:一种基于BERT的依存句法分析模型,利用了神经网络的动态编程技术,实现了较高的精度。
-
NLR:一种基于生成对抗网络的自然语言推理模型,利用了无监督的数据增强技术,取得了相当好的效果。
-
MT-DNN:一种基于多任务学习的自然语言处理模型,通过联合训练多个任务来提高模型性能。
-
ERNIE:一种语言表示框架,结合了知识图谱和外部实体,支持跨语言和跨领域应用。
-
XLNet:使用了自回归网络和循环反向语言模型,使得模型在预训练阶段就可以处理双向上下文信息。
-
TAPAS:一种基于表格的自然语言推理模型,使用了Transformer编码器和解码器,并结合了解析树信息。
-
DeBERTa:一种新颖的多流模型,利用了单独的掩码网络和全局网络来赋予词汇不同的重要性。
-
FNet:将卷积层替换为自定义的逆时间傅里叶(IFFT)层,取得了和基于Transformer的模型相当的效果。
-
AdaBERT:一种基于自适应推断的自然语言处理模型,使用了两个模块来独立学习上下文表示和任务表示。
-
UniSkip:利用句子中的跨度信息来控制信息的流动,达到对输入语句的重要信息更加关注的效果。
-
Transformer-XH:通过测试来确定隐藏层的大小和数量,实现了自动化的模型选择,并在多个任务上取得了较好的效果。
-
Embedding Propagation:自动学习每个单词的嵌入向量,并且借助于流形空间技术,实现了更加丰富的语义表示。
-
EAT:一种基于Transformer的实体-关系表示模型,引入了自注意机制和全局特征注意力,取得了很好的效果。
-
GPT-2:一种基于Transformer的预训练语言表示模型,使用了无监督学习和多层次结构,取得了很好的效果。
-
ULMFiT:利用CycleGAN实现了数据集增强,通过序列到序列的方法做了fine-tuning,取得了较好的结果。
-
BERT-MRC:一种基于BERT的阅读理解模型,扩展了二元分类的形式为span extraction,并提高了准确率。文章来源:https://www.toymoban.com/news/detail-426512.html
-
ERNIE-Gram:一种基于ERNIE的自然语言生成模型,使用了大规模弱监督数据和无监督预训练技术,取得了很好的效果。文章来源地址https://www.toymoban.com/news/detail-426512.html
优劣势一览表:
| 模型名称 | 优势 | 劣势 |
|---|---|---|
| T5 | 多任务学习和无监督预训练结合;使用大规模语料库进行训练 | 训练时间较长 |
| GPT-3 | 庞大的语料库;实现了Zero-shot学习实现自然语言推理功能 | 目前尚未完全开放 |
| Chinchilla | 使用自适应正则化和动态使用的注意力机制 | 并不是所有应用场景都适用 |
| PaLM | 结合了单向和双向模型的优势;使用了双向训练和带有附加任务的预训练 | 可能需要较大的算力和数据量 |
| LLaMA | 可以将语言建模作为先验优化网络参数 | 效果可能受模型中的数据偏差影响 |
| Alpaca | 基于元学习的多任务学习模型;能够快速应用于新的NLP任务中 | 很少有开源实现 |
| ELECTRA | 使用“替代观察”方法学习语言表示,取得了较好的效果 | 尚未在所有NLP任务中经过全面测试 |
| Roberta | 使用更多的训练数据、更长的训练时间和更大的模型尺寸;结合了动态蒸馏和其他技术 | 可能需要更多的计算资源来训练 |
| BART | 结合了语音识别和机器翻译的技术;使用了双向编码器-译码器结构 | 部分应用需要更高的精度 |
| UniLM | 融合了语言生成和语言理解;适用于多种自然语言处理任务 | 处理大规模数据和训练时间可能较长 |
| GShard | 支持大规模分布式训练;性能非常好 | 使用成本较高 |
| LSDSem | 同时考虑了句法和语义信息 | 目前不适用于所有NLP任务 |
| BertRank | 使用了多任务学习和局部注意力机制 | 在某些应用场景中可能存在过拟合的风险 |
| BERT-DP | 利用了神经网络的动态编程技术,实现了较高的精度 | 对输入数据的噪音或误差较为敏感 |
| NLR | 利用了无监督的数据增强技术;取得了相当好的效果 | 同BERT-DP一样,对输入数据的噪音或误差较为敏感 |
| MT-DNN | 联合训练多个任务来提高模型性能 | 训练时间和计算资源需求较高 |
| ERNIE | 结合了知识图谱和外部实体;支持跨语言和跨领域应用 | 有些应用场景中效果不尽如人意 |
| XLNet | 使用自回归网络和循环反向语言模型,处理双向上下文信息 | 训练与调优需要更多的时间和计算资源 |
| TAPAS | 使用了Transformer编码器和解码器,并结合了解析树信息 | 部分应用场景中效果不尽如人意 |
| DeBERTa | 利用了单独的掩码网络和全局网络来赋予词汇不同的重要性 | 训练与调优需要更多的时间和计算资源 |
| FNet | 取得了和基于Transformer的模型相当的效果;计算效率更高 | 目前还在研究阶段 |
| AdaBERT | 使用了两个模块来独立学习上下文表示和任务表示 | 需要更多的训练资源和调优时间 |
| UniSkip | 对输入语句的重要信息更加关注 | 处理大规模数据和训练时间可能较长 |
| Transformer-XH | 实现了自动化的模型选择;在多个任务上取得了较好的效果 | 原理较为复杂 |
| Embedding Propagation | 学习每个单词的嵌入向量,并且实现了更加丰富的语义表示 | 部分应用场景中效果不尽如人意 |
| EAT | 使用了自注意机制和全局特征注意力,取得了很好的效果 | 训练和调优对计算资源的需求较高 |
| GPT-2 | 使用了无监督学习和多层次结构,取得了很好的效果 | 不适用于所有NLP任务 |
| ULMFiT | 使用了CycleGAN实现了数据集增强;借助序列到序列的方法做了fine-tuning | 需要更多的计算资源和时间 |
| BERT-MRC | 扩展了二元分类的形式为span extraction,并提高了准确率 | 不适用于所有阅读理解任务 |
| ERNIE-Gram | 使用了大规模弱监督数据和无监督预训练技术,取得了很好的效果 | 部分应用场景中效果不尽如人意 |
到了这里,关于30个最新的自然语言处理模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!