·S·QL技巧总结
- 表连接
- 要展示的最终结果放在前面的select语句里面
- 小表提取在前面,大表在后面连接

表连接实例
- 连接查询的时候,注意 on 后面跟的 and 条件是连接条件 ,如果要连接后查询 where 可以用
select
er.exam_id,
count(distinct er.uid) as uv,
round(avg(score),1) as avg_score
from exam_record as er
left join examination_info as ei
on ei.exam_id = er.exam_id
left join user_info as ui
on er.uid = ui.uid
where level > 5
and tag="SQL"
and date(release_time) = date(submit_time)
group by exam_id
order by uv DESC ,avg_score ASC ;
//等效的嵌套查询:
SELECT
exam_id,
count( DISTINCT uid ) AS uv,
ROUND(avg( score ), 1) AS avg_score
FROM exam_record
WHERE (exam_id, DATE(start_time)) // 查询条件一
IN (
SELECT exam_id, DATE(release_time)
FROM examination_info WHERE tag = "SQL"
)
AND uid IN ( // 查询条件二
SELECT uid FROM user_info WHERE `level` > 5
)
GROUP BY exam_id
ORDER BY uv DESC, avg_score ASC;
# SQL类别的试卷得分大于过80的人的用户等级分布,按数量降序排序(保证数量都不同)
select
level,
count(level) as level_cnt
from exam_record as er
left join examination_info as ei
on er.exam_id = ei.exam_id
left join user_info as ui
on er.uid = ui.uid
where score > 80 and tag = "SQL" and date(release_time) = date(start_time)
group by level
order by level_cnt DESC ;
//等效嵌套查询
select
level,
count(uid) level_cnt
from user_info
where
uid in
(select uid from exam_record where exam_id in --第二步
(select exam_id from examination_info where tag='SQL') and score>80) --第一步
group by level
order by level_cnt desc --第三步
//嵌套查询
select
device_id,
question_id,
result
from question_practice_detail
where device_id in (
select device_id from user_profile
where university='浙江大学'
)
order by question_id
//表连接
select
qpd.device_id,
qpd.question_id,
qpd.result
from question_practice_detail as qpd
inner join user_profile as up
on up.device_id=qpd.device_id and up.university='浙江大学'
order by question_id
select
university,
count(question_id) / count(distinct qpd.device_id)
from question_practice_detail as qpd
inner join user_profile as up
on up.device_id = qpd.device_id
group by up.university ;
- 多表连接技巧:
- 小表在前原则
- 选择一个主表,其他的表来来连接主表
- 连接的时候,在on后面可以跟条件,用and连接
# 用户信息表:user_profile(device_id)
# 题库练习明细表:question_practice_detail(id device_id question_id result)
# 难度表:question_detail (id question_id difficult_level)
select
university,
round(count(qpd.question_id) / count(distinct qpd.device_id),4),
difficult_level
from question_practice_detail as qpd
left join user_profile as up
on up.device_id = qpd.device_id
left join question_detail as qd
on qd.question_id = qpd.question_id
group by university, difficult_level;
select
university,
difficult_level,
round(count(qpd.question_id)/count(distinct qpd.device_id),4)
from question_practice_detail as qpd
inner join question_detail as qd
on qd.question_id = qpd.question_id
inner join user_profile as up
on up.device_id = qpd.device_id and university = "山东大学"
group by difficult_level;
- 注意
分别查看不去重,直接用where + or 或者 union是不行的 ,要用union all
条件选择函数
select ...,
case
when condition then value
when ...
else value
end as return
...
group by return;
子表连接查询
- 这个嵌套子查询啊,一般是大表在前面
- 表连接一般是小表在前面
select
a.device_id,
a.university,
a.gpa
from user_profile a
right join(
select university,min(gpa) as gpa
from user_profile
group by university
) as b
on a.university = b.university and a.gpa = b.gpa
order by a.university
# select device_id, university, gpa
# from (
# select *,
# row_number() over (partition by university order by gpa) as rn
# from user_profile
# ) as univ_min
# where rn=1
# order by university
- 包含关系,嵌套查询
select device_id,university,gpa
from user_profile
where (university,gpa) in (
select university,min(gpa) from user_profile group by university
)
order by university
- 如果想从当前表提取出新的列再加回来:用select子查询获得新表,然后join回来
# 8月份练习的总题目数和回答正确的题目数
select
up.device_id,
university,
count(question_id) as question_cnt,
sum(
if(qpd.result="right",1,0)
) as right_question_cnt
from user_profile as up
left join question_practice_detail as qpd
on qpd.device_id = up.device_id and month(qpd.date)=8
where university="复旦大学"
group by up.device_id;
这道题的left join还是 inner join
如果难度值里面有None的情况,只能用inner join
select
difficult_level,
sum(
if(qpd.result="right",1,0)
) / count(qpd.question_id) as correct_rate
from question_practice_detail as qpd
left join question_detail as qd
on qd.question_id = qpd.question_id
left join user_profile as up
on up.device_id = qpd.device_id
where university = "浙江大学"
group by difficult_level
order by correct_rate ;
如果要统计多个量的时候,两个量之间没有关联关系,记得用union
- 写两个select,分别统计这两个量,然后 union / union all
窗口函数
select device_id, university, gpa
from (
select *,
row_number() over (partition by university order by gpa) as rn
from user_profile
) as univ_min
where rn=1
order by university
简单来说,窗口函数有以下功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
<窗口函数> over (
partition by <用于分组的列名>
order by <用于排序的列名>)
as 别名
专用窗口函数:
rank, dense_rank, row_number
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
区别如下:
-
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
-
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
-
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
聚合函数作为窗口函数
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
日期
- date 是日期列 ,提取出年月日 year/month/day(data) , 或者 data_format(data, “%Y-%m”) = “202108”
参数类型
-
数据类型:int,bit(位) :整数 decimal:小数 varchar(可变字符串)char:字符串
date,time,datetime:日期时间 enum:枚举类型
-
约束参数:primay key :主键约束(区分数据) not null 非空约束(数据不能为空) unique:唯一约束
SQL语句(结构化查询):
数据库操作: 所有语句以分号结尾!!!!!
- 创建数据库:CREATE DATEBASE db1;
- 查看数据库:SHOW DATEBASES; SHOW CREATE DATEBASES db1;
- 创建数据库并指定字符集:CREATE DATEBASE 数据库名 CHARACTER SET 字符集(gbk,utf8mb4);
- 修改数据库:ALTER DATABASE db1 DEFAULT CHARACTER SET 字符集;
- 删除数据库:DROP DATABASE 数据库名;
- 查看正在使用的数据库:SELECT DATABASE();
- 使用/切换数据库:USE 数据库名;
session
在Presto中,session(会话)是指用户与Presto服务器之间的交互会话。当用户连接到Presto服务器时,会话被创建,并在用户执行查询和操作时持续存在。会话跟踪用户的状态和上下文信息,包括查询历史、会话变量、权限等。
- 每个会话都有一个唯一的会话ID,用于标识该会话。会话ID可以用于在多个查询之间保持状态,例如在一个会话中定义的变量可以在后续查询中使用。
- 会话还可以设置会话级别的参数和选项,以控制查询的行为和性能。例如,可以设置会话级别的并发度、内存限制、超时时间等。
- Presto的会话是无状态的,这意味着服务器不会保留会话的状态信息。如果会话被中断或终止,所有的会话状态和上下文信息都会丢失。因此,如果需要保留会话状态,可以使用会话变量或其他外部存储来保存和恢复状态信息。
总之,Presto中的会话是用户与服务器之间的交互会话,用于跟踪用户的状态和上下文信息,并控制查询的行为和性能。
会话变量:
这个语句是在Presto中设置会话变量"jobname"的值为’ESALE-MODEL-VARIABLES_PRO_1DAY_DATAZ_call_task__7day_cash_info’。会话变量是在会话级别上定义的变量,可以在会话中的多个查询中使用。
通过设置会话变量,可以在查询中引用该变量的值。在这种情况下,"jobname"变量的值被设置为’ESALE-MODEL-VARIABLES_PRO_1DAY_DATAZ_call_task__7day_cash_info’,可以在后续的查询中使用该变量的值。
这个语句的作用是为当前会话设置一个特定的作业名称,以便在后续的查询中可以引用该作业名称。这对于跟踪和识别查询作业非常有用,特别是在处理大量查询时。
mysql中表的操作(DDL):
-
关键字说明:CREATE TABLE 表名(字段名 字段类型1,字段名2 字段类型2…)
mysql中的数据类型:int,float,double,char,varchar,data
-
查看表:SHOW TABLES; 查看表结构:DESC 表名
-
快速创建一个表结构相同的表: CREATE TABLE 新表名 LIKE 旧表名;
-
删除表:DROP TABLE 表名;
-
修改表结构:ALTER TABLE 表名 ADD 列名 类型
-
修改列类型:ALTER TABLE 表名 MODIFY 列名 新的类型;
-
修改列名:ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
-
删除列:ALTER TABLE 表名 DROP 列名;
-
约束:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GCU1zMZ1-1682519840614)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1633960139731.png)]
设置约束的方式:CREATE TABLE table_name( 字段名 字段类型 约束 );
添加约束:alter table table_name add constraint 约束名 约束类型(字段名);
删除约束:删除主键约束:alter table table_name drop primary key;
删除外键约束:alter table table_name drop foreign key 外键约束名;
删除唯一性约束:alter table table_name drop index 唯一索引名;
DML语句(DDL):
-
查询表:SELECT * FROM 表名; 除了数值要用单引号引起!!!
-
插入表:INSERT INTO 表名 (字段1,字段2,…)values(值1,值2,…);全部插入可不写字段
-
更改表:UPDATE 文件名 SET 变量名=更改值 … WHERE 条件(判断是改哪一个);
-
删除表:DELETE FROM 文件名 WHERE 判断条件;
-
蠕虫复制:将原来的数据复制,插入到新的表中
INSERT INTO 新表名 SELETE * FROM 旧表名
如果只想复制旧表中的某一列的数据到新表中:例:复制student表中name和age到student2表中
INSERT INTO student2(name,age)SELETE name,age FROM student;
-
别名查询(优化显示):SELETE name AS 别名,age AS 别名; AS可以省略不写
-
清除重复值(列不出现重复值):SELETE DISTINCT 字段名(可多个字段) FROM 表名
-
查询结果参与运算:
某列数据和固定值运算:SELETE 列名 +固定值 FROM 表名;
某列数据和其他列的数据参与运算:SELETE 列名1 +列名2 FROM 表名 参与运算的一定是数值类型
例:SELETE name 姓名, age+10 年龄 FROM student
函数操作:
条件查询:
-
比较运算符:正常编程运算符 和 and /or / not 用于WHERE条件语句来进行判断
SELETE * FROM hero WHERE age>10
-
模糊运算符:
通配符:%:表示任意个字符 _:表示一个字符
LIKE运算符:
例:SELETE * FROM hero WHERE name like ‘孙%’;查询孙姓的人 ‘%孙%’包含孙字的人 ‘孙__’ 查孙xx
between and还有or、and(区间查询): WHERE id between 100 and 120;
逻辑语句在WHERE条件句后使用
IN:WHERE id in(字段名,字段名…)
IS NULL(判断条件): WHERE benifits IS NULL;
安全等于:<=> (判断是否等于) WHERE salary <=> 12000;
-
ORDER BY :可以将查询出的结果进行排序(只是显示方式,不改变数据库的顺序)
语法:
SELETE 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名 [ASC|DESC] ;ASC:升序,默认是升序
DESC:降序
组合排序:SELETE 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段1 [ASC|DESC],字段2[ASC|DESC] ;
-
聚合函数:
count:计算指定列的数值和,如果不是数值类型,那么计算结果为0
sum:计算指定列的和
max:计算指定列的最大值
min:计算指定列的最小值
avg:计算平均值
如何使用呢?写在SQL语句 SELETE 后 字段名的地方 SELETE COUNT(字段名) FROM 表名;
round:四舍五入
ceil :向上取整
floor:向下取整
mod:取余
-
日期函数:
NOW():返回当前日期+时间
curdate:返回日期不包含时间
curtime:返回时间不包含日期
-
字符函数:
length(‘字符串’):统计字符串长度 SELETE LENGTH(‘john’)=4
concat:拼接字符串 SELETE CONCAT (字段1,连接符,字段2) 姓名 FROM 表名
upper、lower():大小写变化 例:SELETE CONCAT(UPPER(name),LOWER(lastname)) 姓名 FROM 表名
substr:截取字符串 SELETE SUBSTR(‘字符串’,开始位置索引,结束位置索引(也就是从第几个开始截取));索引从1开始
instr(字符串,字符串1):字符串1在字符串中第一次出现的索引
trim(字符串):去除字符串前后空格
SELETE TRIM(‘a’ FROM,’aaaaazyhaaaaa‘);去除a
lpad:指定字符左填充指定长度 rpad:右填充 SELETE LPAD(‘字符串’,总长度,‘填充字符串’)
replace(‘原字符串’,‘要替换的字符串’,‘替换的字符串’);
-
流程控制函数:
IF函数: SELETE IF(判断式,表达式1,表达式2); 判断式为真执行表达式1,为假执行表达式2
CASE函数:
CASE 表达式 WHEN 值1 THEN 结果1 WHEN 值2 THEN 结构2 ELSE 结果n END 值是表达式的结果
CASE 字段名 WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 ELSE ‘D’ END
就类似多重if-else嵌套结构
-
分组函数:GROUP BY
语法:SELETE 字段1,字段2… FROM GROUP BY 分组字段 HAVING 条件 ;分组字段结果相同的为一组
配合聚合函数一起使用: HAVINGH后面的条件是分组以后执行的条件
SELETE sum(score) FROM hero WHERE age<30 GROUP BY sex
SELETE count(*),sex(统计性别) FROM hero WHERE age<30 GROUP BY sex HAVING count *>2
-
limit限制语句:LIMIT offset ,length;或者 limit length
offset是指偏移量,就是跳过的记录数量,默认为0;length是指需要显示的总记录
例:SELETE * FROM student LIMIT 2,6 查询student表中的数据,跳过前面两条,显示6条
-
数据库约束:
主键约束:主键必须包含唯一的值 ,主键列不能包含NULL值 PRIMARY KEY
CREATE TABLE hero(id int PRIMARY KEY, name varchar(20));
主键自增:AUTO_INCREMENT表示自动增长
例:CREATE TABLE hero2 (id int PRIMARY KEY AUTO_INCREMENT[=初始值],name varchar)
唯一约束:在这张表中这个字段中值不能重复 格式:字段名 字段类型 UNIQUE
CREATE TABLE hero(id int PRIMARY KEY, name varchar(20)UNIQUE);
非空约束:字段名 字段类型 NOT NULL
CREATE TABLE hero(id int NOT NULL, name varchar(20)UNIQUE);
- 添加默认值:字段名 字段类型 DEFAULT 默认值
CREATE TABLE hero2(id int ,name varchar) DEFAULT ‘射手’; 这个以后添加的英雄默认是射手,要想改变默认值,可以覆盖默认值
-
内连接:
等值连接:SELETE 查询列表 from 表名1(别名),表名2(别名)… where 等值连接条件
SELETE name,boyname FROM beautys,boys WHERE beauty_id=boy_id;
或者这样:**SELETE 查询列表 FROM 表名1 别名 JOIN 表名2 别名 ON 连接条件 **
WHERE 筛选条件
GROUP 筛选条件 GROUP BY 分组条件 HAVING 分组后筛选 ORDER BY 排序列表
例子:查询部门中员工个数>10的部门名称,并按员工个数降序
SELETE COUNT(*) 员工个数 ,department_name FROM employee e JOIN department d
ON e.‘department_id’=d.‘department_id’ GROUP BY d.‘department_id’
HAVING 员工个数>10 ORDER BY 员工个数 DESC;
注意事项:
- 为了解决多表中的字段命名重名问题,往往为表起别名,提高语义性
- 内连接就是输出两表相等匹配的,外连接匹配成功和不成功(NULL)都输出
-
外连接(左连接,右连接):
语法:SELETE 查询列表 from 表1 别名 left/right join 表2 别名
ON 连接条件 WHERE 筛选条件;
-
子查询:
子查询必须放在条件中,且在条件的右侧;子查询一般放在小括号中;子查询执行优先于主查询
例1:查询和ZK相同部门的员工姓名和工资
SELETE last_name ,salary FROM employees WHERE department _id=(
SELETE department_id FROM employees WHERE last_name =‘ZK’ );
例2:查询工资比公司平均工资高的员工的编号,姓名和工资
SELETE AVG(salary) FROM employees
SELETE employee_id ,last_name,salary FROM employee
WHERE salary>( SELETE AVG(salary) FROM employees);
例3:查询各部门最低工资,筛选看哪个部门的工资大于第50号部门的工资
SELETE MIN(salary) ,department_id FROM employees GROUP BY department_id
HAVING MIN(salary) > ( SELETE MIN(salary)
FROM employees WHERE d epartment_id=50 );
-
多行子查询:
in:判断某字段是否在指定列表内 x in(10,20,30)
any/some:判断某字段的值是否满足其中的任意一个 x>(10,20,30)
编程
舞会配对问题:
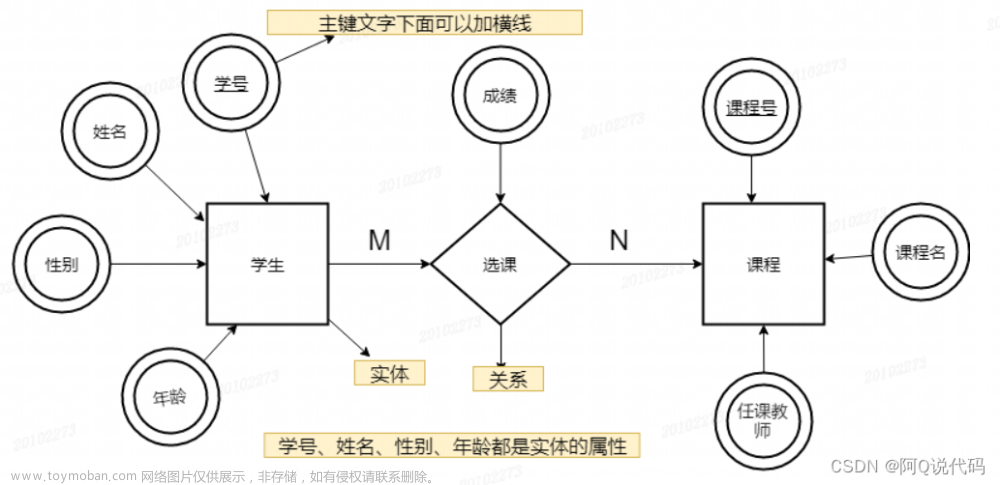
此题并非计算每个人心仪对象数量的最大值,而是每个人心仪对象加被心仪对象数量(不重复计算)的最大值
- 基本思想就是构建二维数组存储男女配对情况。
- 有配对为1,无配对为0,然后找出最大值。
- 评论区有人说不需要存储,我觉得是他们没有考虑到一个男士除了有他自己心仪的女性对象外,还有可能是其他女士的心仪对象,并且这两者之间可能会有重复,所以我觉得还是要全部配对完毕后,再统计最大值。
//男 女
int m, n;
//构建二维数组存储男女配对情况,无配对为0,有配对为1
//读取男士心仪对象 -- 男生心仪矩阵
for 循环
记录男士配堆情况
//读取女士心仪对象 -- 女生心仪矩阵
for 循环
记录女士配堆情况
for 循环
男生心仪矩阵和女生心仪矩阵计算列和,先取每行中的最大值,再取该最大值列的最大值
数据思维
跳失率: 访问了某个项目一次就退出的次数和这个项目总访问的次数的比率
渠道转换比:
费效比: 投入费用/产出效益,用来衡量营销活动的效果
RFM:
RFM模型是衡量客户价值和客户创造利益能力的重要工具和手段
最近一次消费、消费频率、消费金额
CTR 点击率: 点击数(click)/被用户看到的次数,一般用来考核广告投放的引流效果
CR转化率: 指用户完成设定的转化环节的次数和总会话人数的百分比,通常用来评价一个转化环节的好坏
BR跳出率: 跳出率,跳出率=在这个页面跳出的用户数/PV,跳出率一般用来评估网站的某个页面。
概率统计
题型:
排列组合、全概率公式、贝叶斯公式
1.给定数字1-9,组成完全平方数的组合,一个数字只能用一次 :
尾数规律,平方数的个位只能是014569;
因此,14569作为个位数、2378作为十位或者百位
1,9,25,36,784 或者 4,9,25,81,36
2.扔骰子组成等差数列的可能
公差为0,-1,1,2,-2 共18种
3.摸球 放回不放回
- 不放回抽样可归纳为超几何分布问题,超几何分布的典型形式是
P = C M k C N − M n − k / C N m P = {C_M^k}C_{N-M}^{n-k}/C_N^m P=CMkCN−Mn−k/CNm
,表示N件产品中有M件次品,从中不放回地取n件,取得k件次品的概率。
- 有放回抽样可归类为二项分布,二项分布的典型形式为
C n k ( M / N ) k ( 1 − M / N ) n − k C_n^k(M/N)^k(1-M/N)^{n-k} Cnk(M/N)k(1−M/N)n−k
,表示N件产品中有M件次品,从中有放回地取n件,取得k件次品的概率。
一个池子里有无穷尽的水,需要用两个容器,一个5升,另一个6升,取3升的水。
题解:两壶做差得1,来回互倒凑出来
先将6升的容器装满水然后倒入5升的容器中,这样6升的容器中还剩一升水。
将5升的容器中的水全部倒掉,然后将6升的容器中剩余的一升水倒入5升的容器中,这样5升容器中有一升水。
再将6升的容器装满水然后倒入5升的容器中,这样6升的容器中还剩2升水。
将5升的容器中的水全部倒掉,然后将6升的容器中剩余的2升水倒入5升的容器中,这样5升容器中有2升水。
再将6升的容器装满水然后倒入5升的容器中,这样6升的容器中还剩3升水。
爸,妈妈,妹妹,小强, 至少两个人同一生肖的概率是多少?
至少两个人一个生肖则用1-互不相同概率得到
1 - 12/12 * 11/12 * 10/12 * 9/12 = 41/96
假设今天是周二,100 天后将是周几?
(100%7+2)%7
计算星期几的算法中,最著名的是蔡勒(Zeller)公式。
-
即w=y+[y/4]+[c/4]-2c+[26(m+1)/10]+d-1
w:星期;c:世纪-1;y:年(两位数);m:月(m大于等于3,小于等于14,即在蔡勒公式中,某年的1、2月要看作上一年的13、14月来计算,比如2003年1月1日要看作2002年的13月1日来计算);d:日;[ ]代表取整,即只要整数部分。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bLPdFWZ1-1682519840615)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1682473172363.png)]
时钟问题:
分针每分钟转360/60度,即6°,时针每分钟转360/12*60度,即0.5度,故分针和时针的角速度差为 5.5°/分钟。
问: 上班时间下午2点多,时针分针垂直,下班晚上5点多,时针分针重合,过了多久 ?
角度差了90°,90/5.5 = 180/11 = 16 + 4/11分钟 后重合
方法:差多少时间,把时间换成角度 然后除以5.5得到分钟数
一个国家重男轻女,只要生了女孩就继续生,直到生出男孩为止,问这个国家的男女比例?
- 答案是1:1,思路是等比数列求极限
SQL题型:
join 、case、 when、 with
编程伪代码题
风控挖掘
实例分析:
维度、指标
账单交易的分析指标、简述、和结论
-
按月收入和支出分析
-
收支情况,贷款能力判断
-
进行淡旺季的判断 , 收付款的淡旺季与行业淡旺季是否一致
-
分析客户淡季和旺季分别的现金流水平,结合其负债情况判断在淡季时的偿债能力。
-
-
按交易对象分析
- 按交易对象分析就是分别进行收入支出统计,并将入账和出账的交易对象进行汇总分析
- 按交易对象汇总分解客户在期间内的全部支出金额,并按金额大小倒序排列,判断主要的支出对象与客户主营业务的相关度
- 通过支出统计看到与客户主营业务无关的支出情况,这些信息透露出客户与主业无关的资金流向
-
大额整数交易分析
- 这些交易通常是非正常交易,对于交易频率及交易对象需要格外地关注,虚假交易、关联公司、隐性负债通常藏匿其中
- 在进行各种汇总统计计算时,应将所有大额整数交易扣除在外,以提高计算的准确性
-
找出可疑交易:
-
是值得深入检索的,其中会包含大量关于借款、贷款等信息 ;
-
有一些在交易金额、发生日期上存在明显规律性的交易
-
-
日余额变动习惯
- 信贷审批评估 , 日均存款余额标志着客户稳定现金结余的水平
- 日常资金流向规律,以及流向谁
-
同名划转分析
- 判断目前分析的银行账户在客户整体的账户体系中所处的位置,是主要的收款账户还是主要的付款账户
贷款风险预测问题:现金周转、银行给谁贷款?
风控指标:
KS是风险评分领域常用的评估指标,反应模型对正负样本的辨识能力,KS越高表明能力越强 ,两个分布最大间隔距离
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UOoWq7V2-1682519840616)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1682476450636.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iSXOxuvA-1682519840617)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1682476514032.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fDawQy1I-1682519840617)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1682476180575.png)]
挖掘流程:文章来源:https://www.toymoban.com/news/detail-426836.html
- 主要是选择了用户、司机、行程三个大维度下的各种特征(具体就不展开了);
- feature优化(交叉特征/欠采样与score矫正/贝叶斯平滑/引入新特征…);
- label优化(投诉nlp/引入安全类问题…);
- 模型优化(lr/xgb/dnn…);
- 模型评估指标(总AUC/各问题AUC/LogLoss/弹出问题分布…);
- 业务评估指标(订单差评率/坏司机召回率/cpo…);
- 上线验证(流量分配/ABtesting…);
,这些信息透露出客户与主业无关的资金流向
-
大额整数交易分析
- 这些交易通常是非正常交易,对于交易频率及交易对象需要格外地关注,虚假交易、关联公司、隐性负债通常藏匿其中
- 在进行各种汇总统计计算时,应将所有大额整数交易扣除在外,以提高计算的准确性
-
找出可疑交易:
-
是值得深入检索的,其中会包含大量关于借款、贷款等信息 ;
-
有一些在交易金额、发生日期上存在明显规律性的交易
-
-
日余额变动习惯
- 信贷审批评估 , 日均存款余额标志着客户稳定现金结余的水平
- 日常资金流向规律,以及流向谁
-
同名划转分析
- 判断目前分析的银行账户在客户整体的账户体系中所处的位置,是主要的收款账户还是主要的付款账户
贷款风险预测问题:现金周转、银行给谁贷款?
风控指标:
KS是风险评分领域常用的评估指标,反应模型对正负样本的辨识能力,KS越高表明能力越强 ,两个分布最大间隔距离
[外链图片转存中…(img-UOoWq7V2-1682519840616)]
[外链图片转存中…(img-iSXOxuvA-1682519840617)]
[外链图片转存中…(img-fDawQy1I-1682519840617)]
挖掘流程:
- 主要是选择了用户、司机、行程三个大维度下的各种特征(具体就不展开了);
- feature优化(交叉特征/欠采样与score矫正/贝叶斯平滑/引入新特征…);
- label优化(投诉nlp/引入安全类问题…);
- 模型优化(lr/xgb/dnn…);
- 模型评估指标(总AUC/各问题AUC/LogLoss/弹出问题分布…);
- 业务评估指标(订单差评率/坏司机召回率/cpo…);
- 上线验证(流量分配/ABtesting…);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kuKl9fup-1682519840618)(C:%5CUsers%5C%E9%93%B6%E6%99%97%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5C1682476003410.png)]文章来源地址https://www.toymoban.com/news/detail-426836.html
到了这里,关于MySQL的学习小结的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!