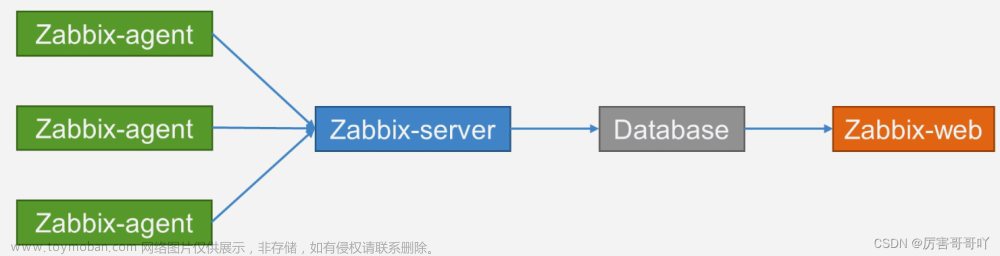
1.设置三台Linux虚拟机的主机名和固定IP
忘了记录,原视频链接在这:2023新版黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战项目全套一网打尽
2.在Linux系统以及本机系统中配置了主机名映射
配置大数据集群主机映射时:vim /etc/hosts
回车后按shift+A开始键入模式
192.168.88.130 node1
192.168.88.102 node2
192.168.88.103 node3
然后Esc,输入 :wq保存。
配置ssh免密登录:
每台都执行:ssh-keygen -t rsa -b 4096,一路回车;
每台都执行ssh-copy-id node1 -> yes 密码
,node2,node3同理
3.配置了三台服务器之间root用户的SSH免密互通
创建hadoop用户并设置免密登录:useradd hadooppasswd hadoop
切换到hadoop: su - hadoop
创建私钥系统:ssh-keygen -t rsa -b 4096ssh-copy-id node1
同上三个node都配
4.配置jdk环境
su - rootmkdir -p /export/server
传jdk的压缩包输入:rz -bey,选择jdk包等待上传,解压缩tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server/
配置jdk软链接 ln -s /export/server/jdk1.8.0_361 jdk
配置环境变量:vim /etc/profile
文件中加上:
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
:wq保存退出
让环境变量生效:source /etc/profile
配置java执行程序的软链接:
先删除系统自带的java: rm -f /usr/bin/java 【是usr】
软链接到自己安装的java: ln -s /export/server/jdk/bin/java /usr/bin/java
执行验证:java -version 或javac -version
现在复制jdk到node2,node3,
su - root
cd /export/server
scp -r jdk1.8.0_361 node2:`pwd`/
scp -r jdk1.8.0_361 node3:`pwd`/
可以回到node2查看cd /export/serverll
然后从jdk软链接那步开始对node2 ,node3重复操作
若要查看node1之前的环境变量:cat /etc/profile
5.关闭防火墙和SELinux
集群化软件之间需要通过端口互相通讯,避免网络不通,需要集群内部关闭防火墙。
每一台都执行:
systemctl stop firewalld
systemctl disable firewalld
Linux有安全模块SELinux限制用户和程序的相关权限,用来确保系统的安全稳定。需要关闭
vim /etc/sysconfig/selinux
将第7行SELINUX=enforcing改为:SELINUX=disabled
保存退出后重启虚拟机。重启init 6 关机 init 0
6.修改时区并配置自动时间同步
yum install -y ntp
rm -f /etc/localtime;sub ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate -u ntp.aliyun.com
systemctl start ntpd
systemctl enable ntpd
执行完后systemctl status ntpd看是否正在运行中,每隔一段时间会自动校准系统当前时间
7.设置快照保存状态
对当前状态进行快照保存,以便后续辉恢复。
关机,右键拍摄快照,做好备注,例如:安装集群前置准备完成文章来源:https://www.toymoban.com/news/detail-426886.html
8.下一篇 HDFS集群部署
黑马2023大数据实战教程】VMWare虚拟机部署HDFS集群详细过程文章来源地址https://www.toymoban.com/news/detail-426886.html
到了这里,关于【黑马2023大数据实战教程】使用3台虚拟机搭建大数据集群详细步骤的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!