【前言】 本文版权属于GiantPandaCV,未经许可,请勿转账!
前几天疯狂刷屏的RT-DETR赚足了眼球,在精度和速度上体现的优势和性价比远远高于YOLO,而今年ChatGPT、Sam的出现,也让一些吃瓜群众知乎CNN没有未来了,今天的文章,我们简单聊一聊RT-DETR的骨干网络,HGNetv2。
一、RT-DETR横空出世
前几天被百度的RT-DETR刷屏,该提出的目标检测新范式对原始DETR的网络结构进行了调整和优化,以提高计算速度和减小模型大小。这包括使用更轻量级的基础网络和调整Transformer结构。并且,摒弃了nms处理的detr结构与传统的物体检测方法相比,不仅训练是端到端的,检测也能端到端,这意味着整个网络在训练过程中一起进行优化,推理过程不需要昂贵的后处理代价,这有助于提高模型的泛化能力和性能。
当然,人们对RT-DETR之所以产生浓厚的兴趣,我觉得大概率还是对YOLO系列审美疲劳了,就算是出到了YOLO10086,老子还是只想用YOLOv5和YOLOv7的框架来魔改做业务。。
二、初识HGNet
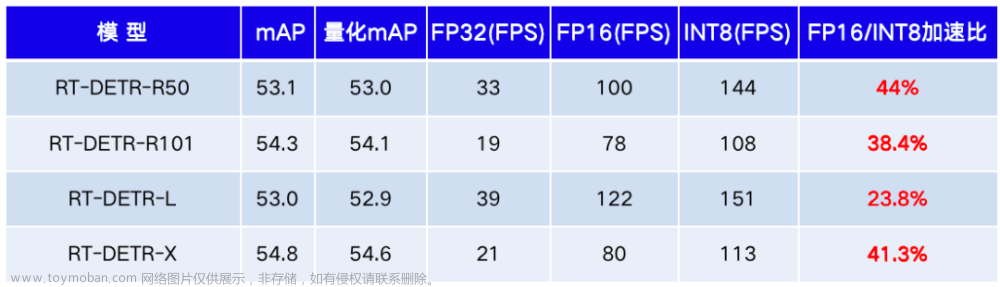
看到RT-DETR的性能指标,发现指标最好的两个模型backbone都是用的HGNetv2,毫无疑问,和当时的picodet一样,骨干都是使用百度自家的网络。
初识HGNet的时候,当时是参加了第四届百度网盘图像处理大赛,文档图像方向识别专题赛道,简单来说,就是使用分类网络对一些文档截图或者图片进行方向角度分类。
当时的方案并没有那么快定型,通常是打榜过程发现哪个网络性能好就使用哪个网络做魔改,而且木有显卡,只能蹭Ai Studio的平台,不过v100一天8小时的实验时间有点短,这也注定了大模型用不了。
流水的模型,铁打的炼丹人,最后发现HGNet-tiny各方面指标都很符合我们的预期,后面就一直围绕它魔改。
当然,比赛打榜是目的,学习才是享受过程,当时看到效果还可以,便开始折腾起了HGNet的网络架构,我们可以看到,PP-HGNet 针对 GPU 设备,对目前 GPU 友好的网络做了分析和归纳,尽可能多的使用 3x3 标准卷积(计算密度最高),PP-HGNet是由多个HG-Block组成,细节如下:
ConvBNAct是啥?简单聊一聊,就是Conv+BN+Act,CV Man应该最熟悉不过了:
class ConvBNAct(TheseusLayer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
groups=1,
use_act=True):
super().__init__()
self.use_act = use_act
self.conv = Conv2D(
in_channels,
out_channels,
kernel_size,
stride,
padding=(kernel_size - 1) // 2,
groups=groups,
bias_attr=False)
self.bn = BatchNorm2D(
out_channels,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
if self.use_act:
self.act = ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.use_act:
x = self.act(x)
return x
且标准卷积的数量随层数深度增加而增多,从而得到一个有利于 GPU 推理的骨干网络,同样速度下,精度也超越其他 CNN ,性价比也优于ViT-base模型。
另外,我们可以看到:
- PP-HGNet 的第一层由channel为96的Stem模块构成,目的是为了减少参数量和计算量。 PP-HGNet
- Tiny的整体结构由四个HG Stage构成,而每个HG Stage主要由包含大量标准卷积的HG Block构成。
- PP-HGNet的第三到第五层使用了使用了可学习的下采样层(LDS Layer),该层group为输入通道数,可达到降参降计算量的作用,且Tiny模型仅包含三个LDS Layer,并不会对GPU的利用率造成较大影响.
- PP-HGNet的激活函数为Relu,常数级操作可保证该模型在硬件上的推理速度。
三、再探HGNetv2
时隔半年,出世的RT-DETR又让我关注起了这个网络,而此时,HGNet已不叫HGNet,就像陈老师已经不是当年的陈老师,阿珍也不是当初那片星空下的阿珍,现在升级换代变成了Pro版本。
我们看看v2版本做了哪些变动?
最基本的组成单元还是ConvBNAct不变,但该结构添加了use_lab结构,啥是use_lab结构,简单来说就是类似于resnet的分支残差,但是use_lab是使用在了纯激活函数部分:
# refer to https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
class ConvBNAct(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
groups=1,
use_act=True,
use_lab=False,
lr_mult=1.0):
super().__init__()
self.use_act = use_act
self.use_lab = use_lab
self.conv = Conv2D(
in_channels,
out_channels,
kernel_size,
stride,
padding=padding
if isinstance(padding, str) else (kernel_size - 1) // 2,
groups=groups,
bias_attr=False)
self.bn = BatchNorm2D(
out_channels,
weight_attr=ParamAttr(
regularizer=L2Decay(0.0), learning_rate=lr_mult),
bias_attr=ParamAttr(
regularizer=L2Decay(0.0), learning_rate=lr_mult))
if self.use_act:
self.act = ReLU()
if self.use_lab:
self.lab = LearnableAffineBlock(lr_mult=lr_mult)
# 激活函数部分添加lab结构
同时,use_lab结构可以通过scale控制分流大小:
# refer to https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
class LearnableAffineBlock(nn.Layer):
def __init__(self,
scale_value=1.0,
# scale设置分流占比
bias_value=0.0,
lr_mult=1.0,
lab_lr=0.01):
super().__init__()
self.scale = self.create_parameter(
shape=[1, ],
default_initializer=Constant(value=scale_value),
attr=ParamAttr(learning_rate=lr_mult * lab_lr))
self.add_parameter("scale", self.scale)
self.bias = self.create_parameter(
shape=[1, ],
default_initializer=Constant(value=bias_value),
attr=ParamAttr(learning_rate=lr_mult * lab_lr))
self.add_parameter("bias", self.bias)
def forward(self, x):
return self.scale * x + self.bias
除此之外,相对于第一版,HGNetv2已摘除了ESE模块,但提供了LightConvBNAct模块,更加具体的内容可参见:
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py文章来源:https://www.toymoban.com/news/detail-426905.html
PP-HGNetv2的整体结构详见下图:
【结尾】 总体而言,HGNet还是一个比较低调的网络,官方也没有过多宣传,但是好不好用,依旧还是使用者说了算,后续如果DETR变体可以在国内常见的板端成熟落地,如瑞芯微,地平线,高通等芯片上适配,会给使用者带来更多的选择。文章来源地址https://www.toymoban.com/news/detail-426905.html
到了这里,关于简单聊聊目标检测新范式RT-DETR的骨干:HGNetv2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!