参考
| 项目 | 描述 |
|---|---|
| 维基百科 | ZIP 格式 |
| Python 官方文档 | zipfile - 使用ZIP存档 |
| 搜索引擎 | Google、Bing |
| Zip 文件格式规范 | APPNOTE.TXT |
| 维基百科 | 首页 |
| 百度百科 | 首页 |
描述
| 项目 | 描述 |
|---|---|
| Python | 3.10.6 |
| 操作系统 | Windows 10 专业版(x86-64) |
| 压缩软件 | 360压缩(4.0.0.1460) |
铺垫
本部分内容为铺垫内容,除 “乱码现象” 为必看内容外,其余均为选看内容。如本部分内容已观看完毕,请移步至 “溯源” 部分继续观看。
乱码现象
在使用国内主流的 Zip 压缩软件将文件进行压缩后,若使用 Python 模块 ZipFile 对 Zip 文件中被存储文件的名称进行提取,往往会产生乱码现象。对此,请参考如下示例:
import zipfile
# 月亮与六便士.zip 文件是使用 360压缩将
# 月亮与六便士.txt 文件 进行压缩后得到的产物。
ZIPPATH = r'C:\Users\RedHeart\PycharmProjects\pythonProject\月亮与六便士.zip'
# 以只读方式打开 Zip 文件
with zipfile.ZipFile(ZIPPATH) as fz:
# 迭代名称列表,输出 Zip 文件中所有文件的名称
for name in fz.namelist():
print(name)
执行效果
╘┬┴┴╙δ┴∙▒π╩┐.txt
编码与解码
编码
编码通常是为了将文本进行存储、传输或处理,因为 计算机只能处理数字。常见的编码方式包括 ASCII、Unicode、UTF-8 等。
解码
解码是指将已经被编码的数字或数字序列转换回原始的字符或文本的过程。解码的过程是编码的逆过程,通常需要使用与编码方式相同的规则和算法来进行解码。
字符集
在计算机中,字符集(Character Set)是由一系列字符组成的集合,每个字符都对应一个唯一的编码。常见的字符集包括 ASCII、Unicode 等。
Unicode 字符集
Unicode 字符集中的一种,它包含了全球所有语言中的字符,并且可以进行扩展,支持更多的字符。 Unicode 字符集目前已经超过了 100,000 个字符,其中包括了各种字母、数字、标点符号、符号、表情符号等。
Unicode 的编码方式有多种,其中比较常见的是 UTF-8、UTF-16 和 UTF-32。不同的编码方式使用不同的位数来表示一个字符,UTF-8 使用 1 到 4 个字节来表示一个字符,UTF-16 使用 2 或 4 个字节来表示一个字符,UTF-32 使用 4 个字节来表示一个字符。
Unicode 字符集的出现解决了多语言字符集的混乱问题,使得各个语言之间的交流和互动更加方便和自然。 在计算机领域,Unicode 的广泛使用也使得字符编码的处理更加便捷和标准化。
UTF-8
UTF-8(Unicode Transformation Format-8) 是一种 可变长度 的字符编码方式,它是 Unicode 字符集 中的一种。
UTF-8 是一种可变长度的编码方式,可以用来表示 Unicode 中的任何字符。UTF-8 编码方式使用 1 到 4 个字节来表示一个字符,较少使用的字符使用数量较多的字节,而常用的字符则使用数量较少的字节,以便节约存储空间。
除了 UTF-8 之外,Unicode 还存在其他的编码方式,如 UTF-16 和 UTF-32,但是在实际应用中,UTF-8 是最为广泛使用的编码方式之一。
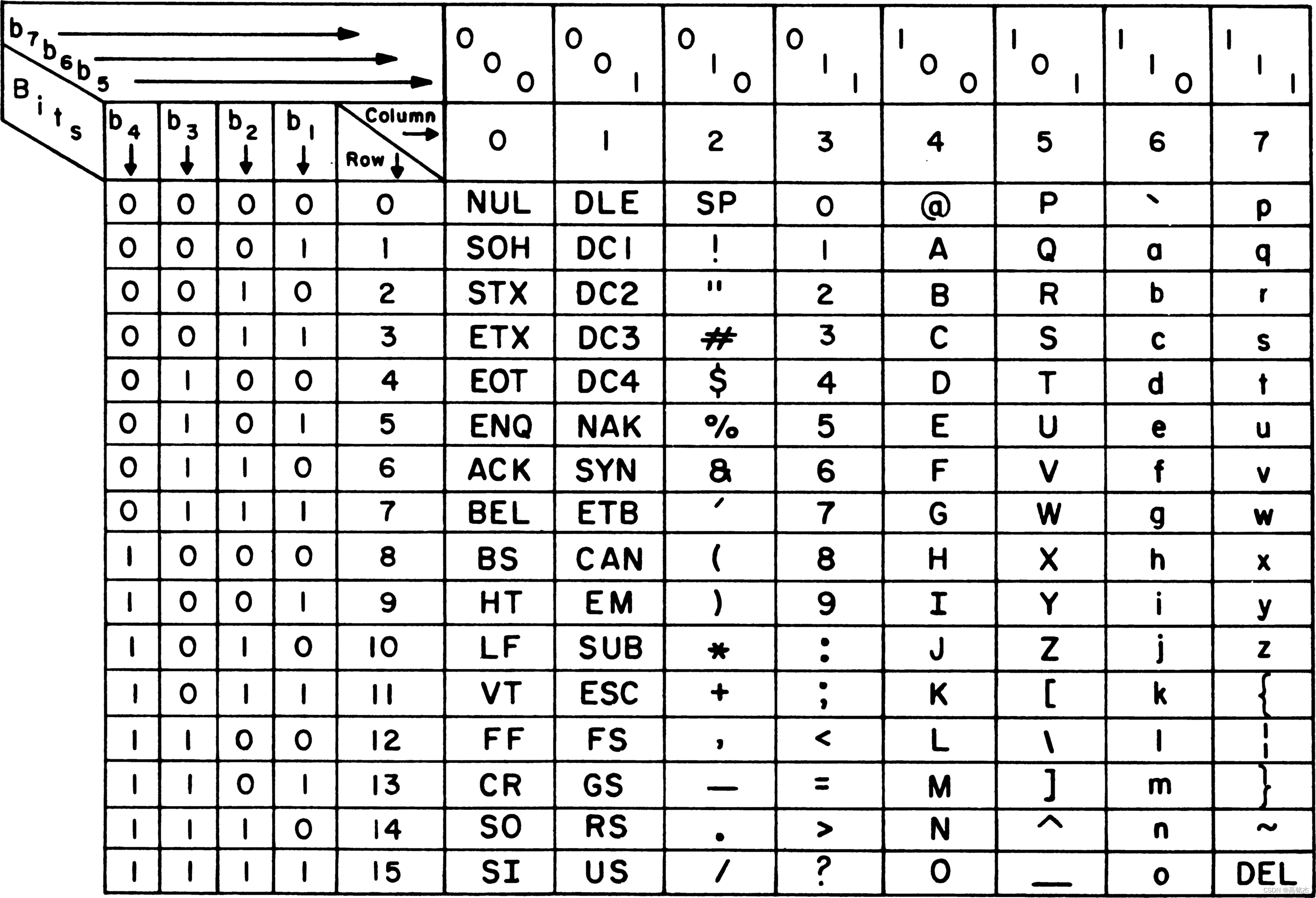
CP437
CP437 是字符集中的一种,也称为 IBM PC 字符集 或 DOS 字符集。它最初是为 IBM PC 设计的,用于在早期的个人计算机上显示字符和符号。CP437 包含了 256 个字符,包括了字母、数字、标点符号、符号以及各种特殊符号等。
CP437 的编码方式是一个字节表示一个字符,它使用了 ASCII 编码中未被使用的 128 个字符位置来表示新的字符和符号。因此,CP437 可以被认为是 ASCII 字符集的扩展版本。
CP437 主要用于早期的个人计算机系统,例如 IBM PC 和 DOS 系统。虽然它已经被现代的 Unicode 字符集所取代,但是在一些旧的系统和应用中,仍然会使用 CP437 编码方式。
Zip 文件与 CP437 编码
ZIP 文件在历史上并没有指定元数据信息的编码方式,但强烈推荐使用 CP437 编码(原始的 IBM PC 编码)以实现互操作性。这是因为 CP437 编码是一个非常基础的编码方式,几乎所有计算机系统都能够识别它。
当然,现代的 ZIP 实现已经支持使用 UTF-8 编码来存储文件名和注释信息。但是,由于历史原因和兼容性问题,一些旧的 ZIP 工具可能仍然只支持使用 CP437 编码。因此,为了确保 ZIP 文件的兼容性,强烈建议在创建 ZIP 文件时使用 CP437 进行编码。如果需要使用其他编码方式进行解码,则应将其转换为 CP437 编码再对其进行解码操作。
GB2312
GB2312 是中国国家标准中的一种字符集编码方式,它最初于 1980 年发布,是为了在计算机系统中表示汉字而开发的。GB2312 字符集中包含了大约 7,000 个常用汉字和约 700 个非汉字字符,例如数字、字母和符号等。
GB2312 使用双字节编码方式,每个汉字使用两个字节来表示,而每个非汉字字符(如数字、字母和符号)使用一个字节来表示。使用 GB2312 编码方式的文件可以在大多数中文操作系统和应用程序中正确显示汉字和其他字符。
GB2012
GB2012(GB/T 2312-2017)是 GB2312 字符集的升级版,与 GBK 有一些类似之处,它也使用双字节编码,每个汉字使用 2 个字节来表示,而每个非汉字字符使用一个字节表示。GB2012 扩展了 GB2312 中的字符集,增加了一些生僻汉字和其他字符。与 GBK 不同的是,GB2012 中新增的字符主要来自于香港和台湾地区的繁体中文字符集,因此在某些情况下,GB2012 可能比 GBK 更适合表示繁体中文。
GBK
GBK 是在 GB2312 字符集的基础上进行扩展的编码方式,它包含了 GB2312 中的所有汉字,并扩展了更多的汉字和其他字符,使得它能够表示包括繁体中文在内的大部分东亚语言中的字符。GBK 使用双字节编码,每个汉字使用 2 个字节来表示,而每个非汉字字符(如英文、数字和符号)使用一个字节表示。GBK 是在中国大陆广泛使用的字符集编码方式,也是 Windows 操作系统中默认的中文字符集编码方式之一。
单字节编码与多字节编码
单字节编码是一种字符编码方式,其中 每个字符使用一个固定的字节表示。例如,在 ASCII 编码中,每个字符都用一个字节表示,字节的值对应于该字符在 ASCII 表中的位置。
多字节编码是另一种字符编码方式,其中每个字符使用多个字节来表示。 例如,在 UTF-8 编码中,一个字符可以由 1 到 4 个字节组成,具体的字节数量取决于字符所在的 Unicode 编码范围。
单字节编码在存储和传输文本数据时通常比多字节编码更简单、更高效,因为每个字符只需要一个固定大小的字节。然而,由于单字节编码只能表示有限的字符集,不能满足全球化和多语言支持的需求,因此多字节编码在现代计算机系统中得到了广泛的应用。
溯源
通用标志位与语言编码标志
通用位标志 (General Purpose Bit Flag) 是一组用于 ZIP 文件头部的二进制位标记,大小为两个字节(即 16 bits),用于指示 ZIP 文件中的各种信息,例如文件是否使用了压缩算法,是否加密等。EFS (Language encoding flag) 是其中的一位标记,即第 11 位,用于指示 ZIP 文件中的文件名和注释信息采用的字符编码方式是否为 UTF-8。
当 ZIP 文件中的文件名和注释信息 都 采用 UTF-8 编码时,可以设置 EFS 标志来表示这一信息(据说,可以提高与早期 Zip 文件的兼容性)。这样,在读取 ZIP 文件时,程序就能够正确地解析文件名和注释信息的编码方式,从而正常地显示这些信息 (在 ZipFile 中,获取文件注释信息d的结果为一个字节串,你需要自己对它们进行解码来获取注释信息)。
ZipFile 所支持的两种编码方式
ZipFile 模块仅使用 CP437 及 UTF-8 编码对文件路径及注释进行解码。ZipFile 模块首先将判断 Zip 内存储的文件路径是否是使用 UTF-8 进行编码的。若是,则使用 UTF-8 对其进行解码;若不是,则使用 CP437 对其进行解码。关于这点,我们可以从 ZipFile 模块的源码中窥见一斑。
if flags & 0x800:
# UTF-8 file names extension
filename = filename.decode('utf-8')
else:
# Historical ZIP filename encoding
filename = filename.decode('cp437')
其中:
flags 代表Zip文件中某个文件的通用标志位。在这个 if-else 语句 中,程序会首先检查该文件的通用标志位的 第 11 位 是否为 1(通过将 flags 与 0x800 进行按位与操作来达成此目标),如果为 1 则表示该文件的文件名使用了 UTF-8 编码,需要使用 UTF-8 进行解码;否则表示该文件的文件名使用了历史的 ZIP 文件名编码(即CP437),需要使用 CP437 进行解码。
GBK 编码与 Zip 应用
ZIP 文件格式本身并没有规定文件路径与注释信息必须使用哪种编码方式进行存储。如果压缩软件开发者不进行特别的处理,可能会采用默认的编码方式,例如在中国地区,许多压缩软件默认使用 GBK 编码方式来处理文件名。
在国内,一些压缩软件将文件路径及注释使用GBK编码进行处理,以下是一些常见的压缩软件:
-
360压缩
-
傲游压缩
-
金山压缩
乱码现象产生的原因
在使用国内主流的压缩软件将文件压缩为 Zip 文件时,会使用 GBK 对文件路径及 Zip 文件的注释信息进行编码。而 ZipFile 模块在检测出该 Zip 文件未设置 语言编码标志 后,使用 CP437 对文件路径进行解码,于是就得到了我们所看到的乱码现象。
对 “乱码现象” 中存在的编码与解码操作进行模拟
filename = '月亮与六便士.txt'
# 将 filename 进行 GBK 编码
gbk_filename = filename.encode('GBK')
print(gbk_filename)
# 使用 CP437 对使用 GBK 编码后的结果进行解码操作
result = gbk_filename.decode('CP437')
print(result)
执行效果
使用 CP437 解码使用 GBK 编码的字符串得到的结果与本文开头所介绍的乱码现象中出现的乱码完全一致。
b'\xd4\xc2\xc1\xc1\xd3\xeb\xc1\xf9\xb1\xe3\xca\xbf.txt'
╘┬┴┴╙δ┴∙▒π╩┐.txt
解决
我们得到的乱码文字是由于将 GBK 编码的字节串使用 CP437 对其进行解码后得到的,那么我们仅需要将乱码文字再次编码为 CP437 并对其进行 GBK 解码操作就能够得到正确的文件名称了。对此,我们对代码进行如下改造:文章来源:https://www.toymoban.com/news/detail-427351.html
import zipfile
# 月亮与六便士.zip 文件是使用 360压缩将
# 月亮与六便士.txt 文件 进行压缩后得到的产物。
ZIPPATH = r'C:\Users\RedHeart\PycharmProjects\pythonProject\月亮与六便士.zip'
# 以只读方式打开 Zip 文件
with zipfile.ZipFile(ZIPPATH) as fz:
# 迭代名称列表,输出 Zip 文件中所有文件的名称
for name in fz.namelist():
# 对文件名称进行编码和解码操作
result = name.encode('CP437').decode('GBK')
print(result)
执行效果文章来源地址https://www.toymoban.com/news/detail-427351.html
月亮与六便士.txt
到了这里,关于Python ZIpFile 解惑:GBK 编码与乱码现象的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!