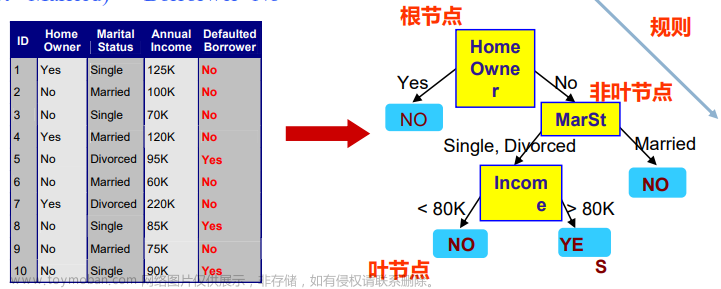
决策树之用信息增益选择最优特征
熵
熵的定义: 熵(shāng),热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。
在决策树中,信息增益是由熵构建而成,表示的是[随机变量的不确定性],不确定性越大,代表着熵越大。随机变量的取值等概率分布时,相应的熵最大,换句话说,特征的所有取值概率相同时,包含的信息是最多的,就是不确定性最大的情况。
熵和随机变量的分布相关,所以写成:
H
(
p
)
=
−
∑
i
=
1
n
p
i
log
p
i
H(p)=-\sum_{i=1}^{n} p_{i} \log p_{i}\\
H(p)=−i=1∑npilogpi
随机变量取值等概率分布时,相应的熵最大,熵的取值范围为:
0
≤
H
(
p
)
≤
log
n
0 \leq H(p) \leq \log n
0≤H(p)≤logn
例如:
X
=
{
0
,
概率
=
p
1
,
概率=
1
−
p
X= \begin{cases}0, & \text {概率}=p \\ 1, & \text { 概率= }1-p\end{cases}
X={0,1,概率=p 概率= 1−p
熵就是:
H
(
p
)
=
−
∑
i
=
1
n
p
i
log
p
i
=
−
p
log
2
p
−
(
1
−
p
)
log
2
(
1
−
p
)
H(p)=-\sum_{i=1}^{n} p_{i} \log p_{i}\\=-p \log _{2} p-(1-p) \log _{2}(1-p)
H(p)=−i=1∑npilogpi=−plog2p−(1−p)log2(1−p)
对p求导:
∂
H
(
p
)
∂
p
=
−
log
2
p
−
1
ln
2
+
log
2
(
1
−
p
)
+
1
ln
2
=
log
2
1
−
p
p
\begin{aligned} \frac{\partial H(p)}{\partial p} &=-\log _{2} p-\frac{1}{\ln 2}+\log _{2}(1-p)+\frac{1}{\ln 2} \\ &=\log _{2} \frac{1-p}{p} \end{aligned}
∂p∂H(p)=−log2p−ln21+log2(1−p)+ln21=log2p1−p
找到熵的极值点:
log
2
1
−
p
p
=
0
1
−
p
p
=
1
p
=
1
2
\log _{2} \frac{1-p}{p}=0\\ \frac{1-p}{p}=1\\ p=\frac{1}{2}
log2p1−p=0p1−p=1p=21
即当
p
=
1
2
p=\frac{1}{2}
p=21时,熵取最大值
信息增益
信息增益:得知特征X而使类Y的信息的不确定性减少的程度。
公式为: g(D,A)=H(D)-H(D A)
当熵和条件熵中的概率有数据估计得到时,则为经验熵和经验条件嫡。
计算信息增益步骤:
输入:训练数据集D和特征A
输出:特征A对D的信息增益g(D,A)
-
计算经验熵公式:
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log _{2} \frac{\left|C_{k}\right|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣ -
计算经验条件熵公式
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ log 2 ∣ D i k ∣ ∣ D i ∣ H(D \mid A)=\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} H\left(D_{i}\right)=-\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} \sum_{k=1}^{K} \frac{\left|D_{i k}\right|}{\left|D_{i}\right|} \log _{2} \frac{\left|D_{i k}\right|}{\left|D_{i}\right|} H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣H ( D ∣ A 1 ) = w 1 H ( D 1 ) + w 2 H ( D 2 ) + w 3 H ( D 3 ) H\left(D \mid A_{1}\right)=w_{1} H\left(D_{1}\right)+w_{2} H\left(D_{2}\right)+w_{3} H\left(D_{3}\right) H(D∣A1)=w1H(D1)+w2H(D2)+w3H(D3)
这里的嫡和条件熵中的概率由数据估计得到的,为经验熵和经验条件熵。在特征A 下每个子集所占的权重为 w i = ∣ D i ∣ ∣ D ∣ w_{i}=\frac{\left|D_{i}\right|}{|D|} wi=∣D∣∣Di∣
-
计算信息增益公式:
g ( D , A ) = H ( D ) − H ( D A ) g(D,A)=H(D)-H(D A) g(D,A)=H(D)−H(DA)信息增益例题:

-
计算经验熵公式
-
样本15个,按是否贷款分为两类,同意贷款个数=9,不同意贷款个数=6
代入计算:
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ = − 6 15 log 2 6 15 − 9 15 log 2 9 15 = 0.971 \begin{aligned} H(D) &=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log _{2} \frac{\left|C_{k}\right|}{|D|} \\ &=-\frac{6}{15} \log _{2} \frac{6}{15}-\frac{9}{15} \log _{2} \frac{9}{15} \\ &=0.971 \end{aligned} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣=−156log2156−159log2159=0.971
-
-
计算经验条件熵公式
- A 1 、 A 2 、 A 3 、 A 4 A_1、A_2、A_3、A_4 A1、A2、A3、A4表示年龄、工作、房子、信贷情况4个特征

特征:年龄 A 1 A_1 A1:取 i i i=1青年、 i i i=2中年、 i i i=3老年 青年:
w 1 = ∣ D 1 ∣ ∣ D ∣ = 5 15 H ( D 1 ) = − ∑ k = 1 2 ∣ D 1 k ∣ ∣ D 1 ∣ log 2 ∣ D 1 k ∣ ∣ D 1 ∣ = − 3 5 log 2 3 5 − 2 5 log 2 2 5 = 0.972 \begin{aligned} &w_{1}=\frac{\left|D_{1}\right|}{|D|}=\frac{5}{15} \\ &H\left(D_{1}\right)=-\sum_{k=1}^{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|} \log _{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|}=-\frac{3}{5} \log _{2} \frac{3}{5}-\frac{2}{5} \log _{2} \frac{2}{5}=0.972 \end{aligned} w1=∣D∣∣D1∣=155H(D1)=−k=1∑2∣D1∣∣D1k∣log2∣D1∣∣D1k∣=−53log253−52log252=0.972
中年:
w 2 = ∣ D 2 ∣ ∣ D ∣ = 5 15 H ( D 2 ) = − ∑ k = 1 2 ∣ D 2 k ∣ ∣ D 2 ∣ log 2 ∣ D 2 k ∣ ∣ D 2 ∣ = − 2 5 log 2 2 5 − 3 5 log 2 3 5 = 0.972 \begin{aligned} &w_{2}=\frac{\left|D_{2}\right|}{|D|}=\frac{5}{15} \\ &H\left(D_{2}\right)=-\sum_{k=1}^{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|} \log _{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|}=-\frac{2}{5} \log _{2} \frac{2}{5}-\frac{3}{5} \log _{2} \frac{3}{5}=0.972 \end{aligned} w2=∣D∣∣D2∣=155H(D2)=−k=1∑2∣D2∣∣D2k∣log2∣D2∣∣D2k∣=−52log252−53log253=0.972
老年:
w 3 = ∣ D 3 ∣ ∣ D ∣ = 5 15 H ( D 3 ) = − ∑ k = 1 2 ∣ D 3 k ∣ ∣ D 3 ∣ log 2 ∣ D 3 k ∣ ∣ D 3 ∣ = − 1 5 log 2 1 5 − 4 5 log 2 4 5 = 0.720 \begin{aligned} &w_{3}=\frac{\left|D_{3}\right|}{|D|}=\frac{5}{15} \\ &H\left(D_{3}\right)=-\sum_{k=1}^{2} \frac{\left|D_{3 k}\right|}{\left|D_{3}\right|} \log _{2} \frac{\left|D_{3 k}\right|}{\left|D_{3}\right|}=-\frac{1}{5} \log _{2} \frac{1}{5}-\frac{4}{5} \log _{2} \frac{4}{5}=0.720 \end{aligned} w3=∣D∣∣D3∣=155H(D3)=−k=1∑2∣D3∣∣D3k∣log2∣D3∣∣D3k∣=−51log251−54log254=0.720
综合计算经验条件熵 H ( D ∣ A 1 ) H\left(D \mid A_{1}\right) H(D∣A1):
H ( D ∣ A 1 ) = w 1 H ( D 1 ) + w 2 H ( D 2 ) + w 3 H ( D 3 ) = 0.324 + 0.324 + 0.24 = 0.888 \begin{aligned} H\left(D \mid A_{1}\right) &=w_{1} H\left(D_{1}\right)+w_{2} H\left(D_{2}\right)+w_{3} H\left(D_{3}\right) \\ &=0.324+0.324+0.24 \\ &=0.888 \end{aligned} H(D∣A1)=w1H(D1)+w2H(D2)+w3H(D3)=0.324+0.324+0.24=0.888 -
计算信息增益公式
g ( D , A 1 ) = H ( D ) − H ( D ∣ A 1 ) = 0.971 − 0.888 = 0.083 \begin{aligned} g\left(D, A_{1}\right) &=H(D)-H\left(D \mid A_{1}\right) \\ &=0.971-0.888=0.083 \end{aligned} g(D,A1)=H(D)−H(D∣A1)=0.971−0.888=0.083
同理
特征:房子

有工作:
w
1
=
∣
D
1
∣
∣
D
∣
=
5
15
H
(
D
1
)
=
−
∑
k
=
1
2
∣
D
1
k
∣
∣
D
1
∣
log
2
∣
D
1
k
∣
∣
D
1
∣
=
−
0
5
log
2
0
5
−
5
5
log
2
5
5
=
0
\begin{aligned} &w_{1}=\frac{\left|D_{1}\right|}{|D|}=\frac{5}{15} \\ &H\left(D_{1}\right)=-\sum_{k=1}^{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|} \log _{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|}=-\frac{0}{5} \log _{2} \frac{0}{5}-\frac{5}{5} \log _{2} \frac{5}{5}=0 \end{aligned}
w1=∣D∣∣D1∣=155H(D1)=−k=1∑2∣D1∣∣D1k∣log2∣D1∣∣D1k∣=−50log250−55log255=0
没有工作:
w
2
=
∣
D
2
∣
∣
D
∣
=
10
15
H
(
D
2
)
=
−
∑
k
=
1
2
∣
D
2
k
∣
∣
D
2
∣
log
2
∣
D
2
k
∣
∣
D
2
∣
=
−
6
10
log
2
6
10
−
4
10
log
2
4
10
\begin{aligned} &w_{2}=\frac{\left|D_{2}\right|}{|D|}=\frac{10}{15} \\ &H\left(D_{2}\right)=-\sum_{k=1}^{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|} \log _{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|}=-\frac{6}{10} \log _{2} \frac{6}{10}-\frac{4}{10} \log _{2} \frac{4}{10} \end{aligned}
w2=∣D∣∣D2∣=1510H(D2)=−k=1∑2∣D2∣∣D2k∣log2∣D2∣∣D2k∣=−106log2106−104log2104
综合计算经验条件熵
H
(
D
∣
A
2
)
H\left(D \mid A_{2}\right)
H(D∣A2):
H
(
D
∣
A
2
)
=
w
1
H
(
D
1
)
+
w
2
H
(
D
2
)
)
=
0.647
\begin{aligned} H\left(D \mid A_{2}\right) &=w_{1} H\left(D_{1}\right)+w_{2} H\left(D_{2}\right)) =0.647 \end{aligned}
H(D∣A2)=w1H(D1)+w2H(D2))=0.647
计算信息增益公式
g
(
D
,
A
2
)
=
H
(
D
)
−
H
(
D
∣
A
1
)
=
0.971
−
0.647
=
0.324
\begin{aligned} g\left(D, A_{2}\right) &=H(D)-H\left(D \mid A_{1}\right) \\ &=0.971-0.647=0.324 \end{aligned}
g(D,A2)=H(D)−H(D∣A1)=0.971−0.647=0.324
特征:房子

有房子:
w
1
=
∣
D
1
∣
∣
D
∣
=
6
15
H
(
D
1
)
=
−
∑
k
=
1
2
∣
D
1
k
∣
∣
D
1
∣
log
2
∣
D
1
k
∣
∣
D
1
∣
=
−
0
6
log
2
0
6
−
6
6
log
2
6
6
=
0
\begin{aligned} &w_{1}=\frac{\left|D_{1}\right|}{|D|}=\frac{6}{15} \\ &H\left(D_{1}\right)=-\sum_{k=1}^{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|} \log _{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|}=-\frac{0}{6} \log _{2} \frac{0}{6}-\frac{6}{6} \log _{2} \frac{6}{6}=0 \end{aligned}
w1=∣D∣∣D1∣=156H(D1)=−k=1∑2∣D1∣∣D1k∣log2∣D1∣∣D1k∣=−60log260−66log266=0
没有房子:
w
2
=
∣
D
2
∣
∣
D
∣
=
9
15
H
(
D
2
)
=
−
∑
k
=
1
2
∣
D
2
k
∣
∣
D
2
∣
log
2
∣
D
2
k
∣
∣
D
2
∣
=
−
3
9
log
2
3
9
−
6
9
log
2
6
9
\begin{aligned} &w_{2}=\frac{\left|D_{2}\right|}{|D|}=\frac{9}{15} \\ &H\left(D_{2}\right)=-\sum_{k=1}^{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|} \log _{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|}=-\frac{3}{9} \log _{2} \frac{3}{9}-\frac{6}{9} \log _{2} \frac{6}{9} \end{aligned}
w2=∣D∣∣D2∣=159H(D2)=−k=1∑2∣D2∣∣D2k∣log2∣D2∣∣D2k∣=−93log293−96log296
综合计算经验条件熵
H
(
D
∣
A
3
)
H\left(D \mid A_{3}\right)
H(D∣A3):
H
(
D
∣
A
3
)
=
w
1
H
(
D
1
)
+
w
2
H
(
D
2
)
)
=
0.551
\begin{aligned} H\left(D \mid A_{3}\right) &=w_{1} H\left(D_{1}\right)+w_{2} H\left(D_{2}\right)) =0.551 \end{aligned}
H(D∣A3)=w1H(D1)+w2H(D2))=0.551
计算信息增益公式
g
(
D
,
A
3
)
=
H
(
D
)
−
H
(
D
∣
A
1
)
=
0.971
−
0.551
=
0.420
\begin{aligned} g\left(D, A_{3}\right) &=H(D)-H\left(D \mid A_{1}\right) \\ &=0.971-0.551=0.420 \end{aligned}
g(D,A3)=H(D)−H(D∣A1)=0.971−0.551=0.420
特征:信贷情况

-
非常好:
w 1 = ∣ D 1 ∣ ∣ D ∣ = 4 15 H ( D 1 ) = − ∑ k = 1 2 ∣ D 1 k ∣ ∣ D 1 ∣ log 2 ∣ D 1 k ∣ ∣ D 1 ∣ = − 0 4 log 2 0 4 − 4 4 log 2 4 4 = 0 \begin{aligned} &w_{1}=\frac{\left|D_{1}\right|}{|D|}=\frac{4}{15} \\ &H\left(D_{1}\right)=-\sum_{k=1}^{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|} \log _{2} \frac{\left|D_{1 k}\right|}{\left|D_{1}\right|}=-\frac{0}{4} \log _{2} \frac{0}{4}-\frac{4}{4} \log _{2} \frac{4}{4}=0 \end{aligned} w1=∣D∣∣D1∣=154H(D1)=−k=1∑2∣D1∣∣D1k∣log2∣D1∣∣D1k∣=−40log240−44log244=0
好:
w 2 = ∣ D 2 ∣ ∣ D ∣ = 6 15 H ( D 2 ) = − ∑ k = 1 2 ∣ D 2 k ∣ ∣ D 2 ∣ log 2 ∣ D 2 k ∣ ∣ D 2 ∣ = − 2 6 log 2 2 6 − 4 6 log 2 4 6 \begin{aligned} &w_{2}=\frac{\left|D_{2}\right|}{|D|}=\frac{6}{15} \\ &H\left(D_{2}\right)=-\sum_{k=1}^{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|} \log _{2} \frac{\left|D_{2 k}\right|}{\left|D_{2}\right|}=-\frac{2}{6} \log _{2} \frac{2}{6}-\frac{4}{6} \log _{2} \frac{4}{6} \end{aligned} w2=∣D∣∣D2∣=156H(D2)=−k=1∑2∣D2∣∣D2k∣log2∣D2∣∣D2k∣=−62log262−64log264
一般:
w 3 = ∣ D 3 ∣ ∣ D ∣ = 5 15 H ( D 3 ) = − ∑ k = 1 2 ∣ D 3 k ∣ ∣ D 3 ∣ log 2 ∣ D 3 k ∣ ∣ D 3 ∣ = − 4 5 log 2 4 5 − 1 5 log 2 1 5 \begin{aligned} &w_{3}=\frac{\left|D_{3}\right|}{|D|}=\frac{5}{15} \\ &H\left(D_{3}\right)=-\sum_{k=1}^{2} \frac{\left|D_{3 k}\right|}{\left|D_{3}\right|} \log _{2} \frac{\left|D_{3 k}\right|}{\left|D_{3}\right|}=-\frac{4}{5} \log _{2} \frac{4}{5}-\frac{1}{5} \log _{2} \frac{1}{5} \end{aligned} w3=∣D∣∣D3∣=155H(D3)=−k=1∑2∣D3∣∣D3k∣log2∣D3∣∣D3k∣=−54log254−51log251
综合计算经验条件熵 H ( D ∣ A 4 ) H\left(D \mid A_{4}\right) H(D∣A4):
H ( D ∣ A 1 ) = w 1 H ( D 1 ) + w 2 H ( D 2 ) + w 3 H ( D 3 ) = 0.608 \begin{aligned} H\left(D \mid A_{1}\right) &=w_{1} H\left(D_{1}\right)+w_{2} H\left(D_{2}\right)+w_{3} H\left(D_{3}\right)=0.608 \end{aligned} H(D∣A1)=w1H(D1)+w2H(D2)+w3H(D3)=0.608
计算信息增益公式
g ( D , A 4 ) = H ( D ) − H ( D ∣ A 4 ) = 0.971 − 0.608 = 0.363 \begin{aligned} g\left(D, A_{4}\right) &=H(D)-H\left(D \mid A_{4}\right) \\ &=0.971-0.608=0.363 \end{aligned} g(D,A4)=H(D)−H(D∣A4)=0.971−0.608=0.363
汇总如下:
特征:房子对应的经验熵最小0.551,信息增益 0.420最大,选择这个特征的话,对应的不确定性最小,分类选择最为明确,可以设为最优特征。
注意:不同特征内的分类个数不同,有的是3个,比如年龄(青年、中年、老年),有的是2个,比如工作(有工作、无工作),取值个数较多时,可能计算出的信息增益会更大,从图中可以看出信息增益会更倾向于取值较多的特征。
信息增益更倾向于具有更多选择的那个特征 会造成信息增益比更少选择的特征大
例如: 信贷情况信息增益0.363大于有工作的信息增益0.324,有可能是因为信贷取值较多而带来的影响。怎么将这个影响降下去,引入信息增益比(在信息增益的情况下,增加一个惩罚项,训练数据集D关于特征A的熵的倒数)。特征A单位取值个数下的信息收益
特
征
A
单
位
取
值
个
数
下
的
信
息
收
益
g
(
D
,
A
)
/
H
A
(
D
)
特征A单位取值个数下的信息收益g(D,A)/H_A(D)
特征A单位取值个数下的信息收益g(D,A)/HA(D)
选择信息增益比最大值为最优特征
怎么计算
H
A
(
D
)
H_A(D)
HA(D): 只要找到每个特征对应的子集的样本个数个数;
年 龄 所 对 应 的 熵 : H A 1 ( D ) = − 5 15 l o g 2 5 15 − 5 15 l o g 2 5 15 − 5 15 l o g 2 5 15 = 1.585 年龄所对应的熵:H_{A1}(D)=-\frac{5}{15}log_2\frac{5}{15}-\frac{5}{15}log_2\frac{5}{15}-\frac{5}{15}log_2\frac{5}{15}=1.585 年龄所对应的熵:HA1(D)=−155log2155−155log2155−155log2155=1.585
工 作 所 对 应 的 熵 : H A 2 ( D ) = − 5 15 l o g 2 5 15 − 10 15 l o g 2 10 15 = 0.918 工作所对应的熵:H_{A2}(D)=-\frac{5}{15}log_2\frac{5}{15}-\frac{10}{15}log_2\frac{10}{15}=0.918 工作所对应的熵:HA2(D)=−155log2155−1510log21510=0.918
房 子 的 熵 : H A 3 ( D ) = − 6 15 l o g 2 6 15 − 9 15 l o g 2 9 15 = 0.971 房子的熵:H_{A3}(D)=-\frac{6}{15}log_2\frac{6}{15}-\frac{9}{15}log_2\frac{9}{15}=0.971 房子的熵:HA3(D)=−156log2156−159log2159=0.971
信 贷 的 熵 : H A 4 ( D ) = − 4 15 l o g 2 4 15 − 6 15 l o g 2 6 15 − 5 15 l o g 2 5 15 = 1.566 信贷的熵:H_{A4}(D)=-\frac{4}{15}log_2\frac{4}{15}-\frac{6}{15}log_2\frac{6}{15}-\frac{5}{15}log_2\frac{5}{15}=1.566 信贷的熵:HA4(D)=−154log2154−156log2156−155log2155=1.566

选了有自己的房子特征之后,怎么选下一个特征?
如果按信息增益选择特征: 有工作0.324小于信贷情况0.363 ,应该选择信贷情况,因为信息增益的值大代表着更多的确定性。
如果消除特征个数所带来的影响的话,通过信息增益比来选择特征,则得到相反的结果,此时的0.353大于0.232.文章来源:https://www.toymoban.com/news/detail-427768.html
信息增益倾向于取值较多的特征,信息增益比倾向于选择取值较少的特征。选择哪一个,根据具体情况选择。文章来源地址https://www.toymoban.com/news/detail-427768.html
到了这里,关于决策树之用信息增益选择最优特征的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!