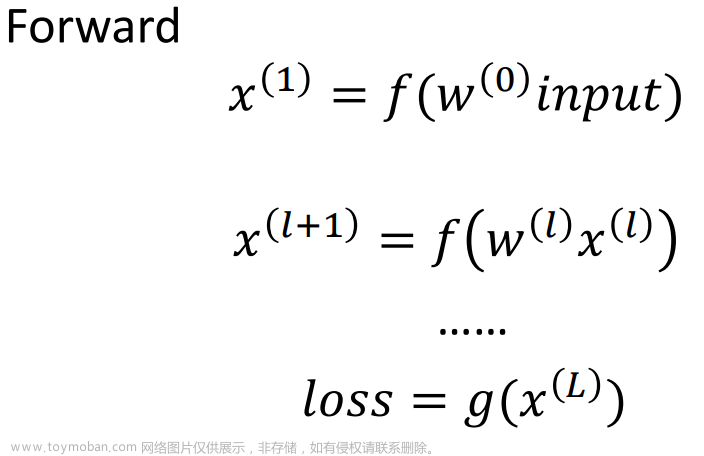backword是不是就是梯度下降
“Backward”(反向传播)和"梯度下降"(gradient descent)是深度学习中的两个不同的概念。
反向传播是一种用于计算神经网络中每个参数的梯度的算法,它通过链式法则将输出误差逐层反向传播,计算每个参数对误差的贡献,并更新参数以最小化误差。因此,反向传播是一种用于计算梯度的方法,但它并不直接执行参数更新。
梯度下降是一种优化算法,它用于最小化损失函数或误差函数。梯度下降通过计算损失函数关于参数的梯度来确定更新方向,并在每个时间步更新参数值。因此,梯度下降是一种用于更新参数的方法,但它并不涉及计算梯度的具体实现。
因此,可以说反向传播是计算梯度的方法之一,而梯度下降是更新参数的方法之一。在深度学习中,通常将这两种方法结合使用,使用反向传播计算梯度,并使用梯度下降更新参数。
反向传播和梯度下降是如何结合使用的?
在深度学习中,反向传播和梯度下降通常是结合使用的。具体来说,反向传播用于计算神经网络中每个参数的梯度,而梯度下降用于使用这些梯度更新参数。
以下是反向传播和梯度下降的结合使用的一般流程:
- 前向传播:将输入数据通过神经网络进行正向传递,计算输出结果。
- 计算损失函数:将输出结果与真实值进行比较,计算损失函数。
- 反向传播:通过链式法则,计算每个参数对损失函数的梯度。
- 参数更新:使用梯度下降算法,根据梯度的负方向更新每个参数的值。
- 重复步骤1-4,直到达到设定的停止条件,例如达到最大迭代次数或损失函数收敛。
在实际应用中,可以使用不同的变体来实现反向传播和梯度下降。例如,在梯度下降中,可以使用不同的学习率、批量大小和动量等超参数,以影响参数更新的速度和稳定性。反向传播中还有其他技巧,例如权重衰减(weight decay)和dropout,可以用于减少过拟合等问题。
总之,反向传播和梯度下降是深度学习中两个重要的概念,它们在训练神经网络时密切相关,并且是实现深度学习的关键算法之一。
反向传播是最小化损失函数吗
反向传播(backpropagation)算法的主要目的是计算神经网络中每个参数的梯度,以便使用梯度下降或其他优化算法对这些参数进行更新。尽管反向传播经常与最小化损失函数联系在一起,但它本身并不是用于最小化损失函数的算法。
最小化损失函数是深度学习的一个重要目标,可以通过梯度下降等优化算法实现。反向传播是计算损失函数关于神经网络中每个参数的梯度的一种方法,它利用链式法则将误差逐层反向传播,计算每个参数对误差的贡献。这些梯度可以用于更新参数,使得损失函数逐渐减小,从而最小化预测误差。文章来源:https://www.toymoban.com/news/detail-427973.html
因此,可以说反向传播是训练神经网络的必要步骤,而最小化损失函数是训练的主要目标。反向传播算法计算的梯度用于更新神经网络中的参数,使得损失函数最小化。文章来源地址https://www.toymoban.com/news/detail-427973.html
到了这里,关于反向传播与梯度下降的疑问的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!