简介
网上冲浪时发现的这两个国产模型,重点是对硬件的要求并不高,有2GB内存就可以跑,觉得有趣就弄来玩了下。
https://github.com/Jittor/JittorLLMs
https://github.com/THUDM/ChatGLM-6B
简单介绍下用到的仓库
ChatGLM-6B
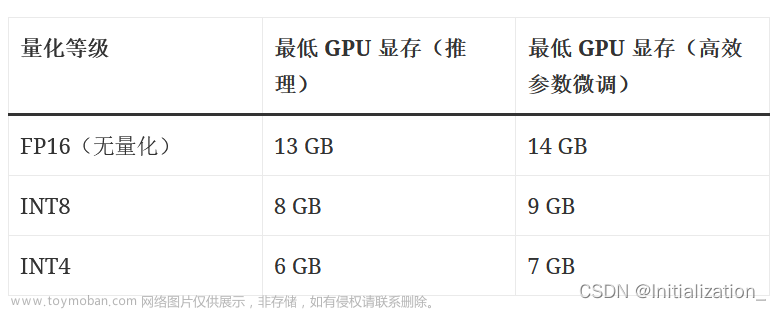
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
JittorLLMS
JittorLLMS是基于ChatGLM-6B开发的开源项目。
成本低:相比同类框架,本库可大幅降低硬件配置要求(减少80%),没有显卡,2G内存就能跑大模型,人人皆可在普通机器上,实现大模型本地部署;是目前已知的部署成本最低的大模型库。
效果
系统:win10
环境:python 3.9.10
cpu:i7-8750H
显卡:GTX-1050Ti
内存:16GB 2666 MHz
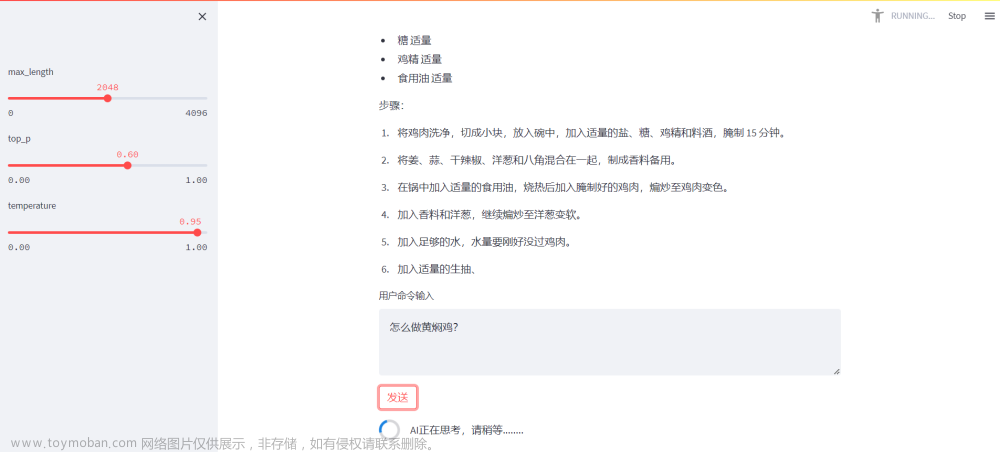
如下图所示,可以发现就凭我这5年前的笔电都可以运行起来,还是挺不错的,就是回答的效果不太好 一个回答需要好几分钟才能说完。

开始安装
安装Python
这里不做赘述,版本要求至少3.8。版本不够的小伙伴需要做下版本的升级
下载安装依赖
可以通过环境变量JITTOR_HOME指定缓存存放路径,默认存放在C盘的user下
# 国内使用 gitlink clone
git clone https://gitlink.org.cn/jittor/JittorLLMs.git --depth 1
# github: git clone https://github.com/Jittor/JittorLLMs.git --depth 1
cd JittorLLMs
# -i 指定用jittor的源, -I 强制重装Jittor版torch
pip install -r requirements.txt -i https://pypi.jittor.org/simple -I
如果出现找不到jittor版本的错误,请更新版本:
pip install jittor -U -i https://pypi.org/simple
安装中若有其他错误,安装python对应的提示信息完成就可以。
如果遇到 transformers 下载失败,尝试使用VPN 将节点放到新加坡 再重新下载,我之前的节点在香港 导致一直下载失败。
部署启动
部署只需一行命令即可:
python cli_demo.py [chatglm|pangualpha|llama|chatrwkv]
运行上面的命令会下载模型文件到本地根目录(C盘)
JittorLLMs 支持4个语言模型的运行
等待模型下载完成后,没有出现红色字体报错,且出现了生成进度 并出现了用户输入: 这几个字,那么恭喜 你的模型运行成功,可以愉快的训练了
若输入指令后 没几秒模型崩了,就是出现如下那种错误了 或内存警告之类的
原因是JittorLLM需要使用的显存和内存超过了我们电脑配置的极限,设置下JittorLLM的环境变量,节省内存:
export JT_SAVE_MEM=1
# 限制cpu最多使用16G 就是内存
export cpu_mem_limit=16000000000
# 限制device内存(如gpu、tpu等)最多使用8G
export device_mem_limit=8000000000
# windows 用户,请使用powershell
# $env:JT_SAVE_MEM="1"
# $env:cpu_mem_limit="16000000000"
# $env:device_mem_limit="8000000000"
内存设置小技巧
为了更好的发挥性能并使JittorLLM不被回收,我们设置内存与GPU显存可用量 可用按如下的公式来:
内存:总内存-当前已用内存-500MB预留的内存
GPU显存:总显存-当前已用显存-500MB预留显存
以上并不一定是最优,至少可用保证运行后被系统给回收掉
用户可以自由设定cpu和设备内存的使用量,如果不希望对内存进行限制,可以设置为-1
# 限制cpu最多使用16G
export cpu_mem_limit=-1
# 限制device内存(如gpu、tpu等)最多使用8G
export device_mem_limit=-1
# windows 用户,请使用powershell
# $env:JT_SAVE_MEM="1"
# $env:cpu_mem_limit="-1"
# $env:device_mem_limit="-1"
JittorLLM 文档已经写的很清楚了,可以在仓库看到更多的操作文章来源:https://www.toymoban.com/news/detail-427986.html
简单记录,回忆不迷路文章来源地址https://www.toymoban.com/news/detail-427986.html
到了这里,关于本地部署ChatGLM-6B模型(使用JittorLLMs大模型推理库)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!