一 linux 环境的搭建
由于笔者这里使用的是vmware 虚拟机 采用centos7 linux 操作系统进行搭建,所以一下示例均以centos7进行示例
1. 搭建vmware 虚拟机
(1)创建好虚拟机后采用linux ISO镜像文件启动安装centos7操作系统(其它方式也可以)
(2)完成之后设置网络模式,笔者采用桥接模式进行设置
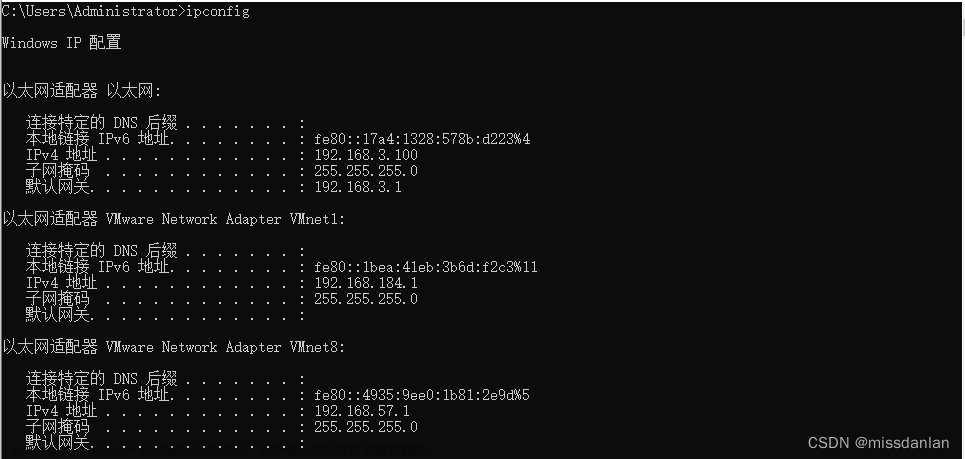
首先需要查看本机也就是宿主机的IP 地址以及网关,运行CMD命令进入DOS命令行窗口
输入ipconfig 记下宿主机的默认网关
打开vmware 网络适配器进行如下设置

设置网卡IP地址以及DNS
vi /etc/sysconfig/network-scripts/ifcfg-ens33进行如下配置

BOOTPROTO=static
ONBOOT=yes
IPADDR=你的IP地址
NETMASK=255.255.255.0
GETWAY=宿主机的网关地址
DNS1和DNS2
设置完成保存 进行重启网络服务

重启之后可以使用IPADDR 查看配置是否生效

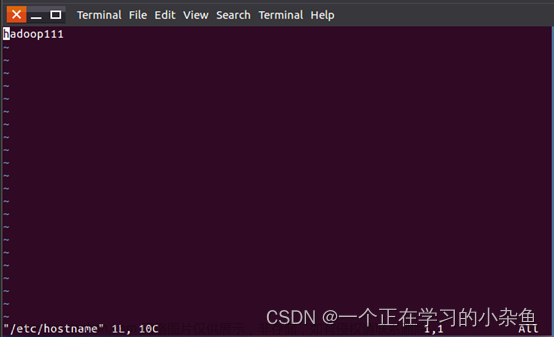
设置主机名
首先查看主机名

笔者这里已经设置过了,未设置 hostname 应该是localhost
设置主机名

设置完成之后进行检查查看

设置hosts ip地址与主机名映射
vi /etc/hosts

关闭防火墙

禁用防火墙服务

关闭之后可以查看防火墙状态进行检查

进行selinux 安全设置

vi /etc/selinux/config 命令进行编辑 设置SELINUX=disabled

设置完成之后 输入命令reboot 进行重启,那么初始设置就设置好了
二 安装JDK 运行环境
由于Hadoop 依赖于JDK运行环境,笔者这里采用的是hadoop3.3.4版本,支持JDK11,所以笔者安装的也是JDK11 版本
1. 上传JDK 安装包至虚拟机后进行解压缩

2. 进入解压缩后的JDK目录 pwd 进行复制安装目录

3. 进行环境变量设置

在文件末尾追加如下内容 后退出保存

source /etc/profile 使环境变量设置生效

4.使用java -version java javac 命令检查JDK 是否安装成功

二 安装Hadoop
1. 上传好Hdoop 安装包之后进行解压缩

2. 进入hadoop 安装目录pwd 复制安装目录地址

3. 设置环境变量

打开之后追加如下内容

保存关闭后使用命令 source /etc/profile 使环境变量配置生效
4. 进入/usr/local mkdir 创建目录hadoop (此目录用于存储namenode secondnamenode 快照文件)后面需要使用进行配置
至此为止hadoop 安装完成
三 配置hadoop 伪分布式集群
1. 设置Hadoop 核心配置文件
进入Hadoop文件设置目录

其中有如下文件需要进行配置
1. core-site.xml

(这里的属性hadoop.tmp.dir 就是你的hadoop namenode 快照存储位置)
2. mapred-site.xml

3. hdfs-site.xml

HDFS 会以128M为单位将上传的文件进行切分为若干个block 存储在不同的datanode中,由于为了在不可靠的机器上进行提供可靠的服务,所以采用多副本机制进行存储。 HDFS 副本数如果不进行设置则默认为3
(这里笔者关闭了hdfs的权限认证)
4.yarn-site.xml

5. hadoop-env.sh (运行环境配置)

添加安装好的JDK目录 进入hadoop 运行环境配置
6. 添加主机名至works 文件


2. 添加用户配置信息
1. 进入hadoop sbin目录

2. 编辑如下内容进入以下文件
(1) start-all.sh (2) stop-all.sh (3)start-dfs.sh (4) stop-dfs.sh (5) start-yarn.sh (6) stop-yarn.sh
在这里以start-all.sh 为例:

3. 初始化HDFS 文件系统
如果是第一次安装使用Hadoop那么在启动之前需要出示话HDFS文件系统

看到如下信息则初始化完成

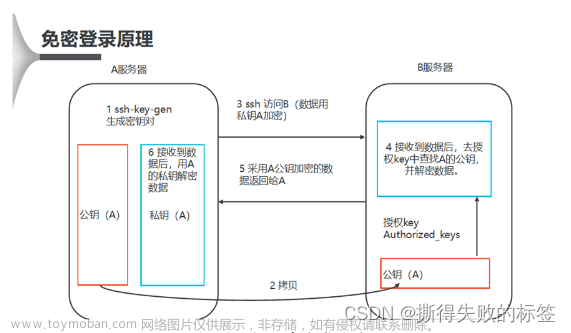
4. 设置SSH免密登录
由于Hdoop namenode 与datanode 内部通讯协议采用RPC协议,则需要进行设置SSH免密登录
这里笔者采用RSA 对称加密算法
1. 创建密钥

2. 添加密钥进本机

4. 启动hadoop

使用JPS 查看是否启动成功

至此为止hadoop 伪分布式集群搭建完成
由于笔者是第一次进行编写,如有什么地方写的有遗漏欢迎指出进行更新改进文章来源:https://www.toymoban.com/news/detail-428001.html
谢谢! 文章来源地址https://www.toymoban.com/news/detail-428001.html
到了这里,关于HADOOP 伪分布式集群搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!