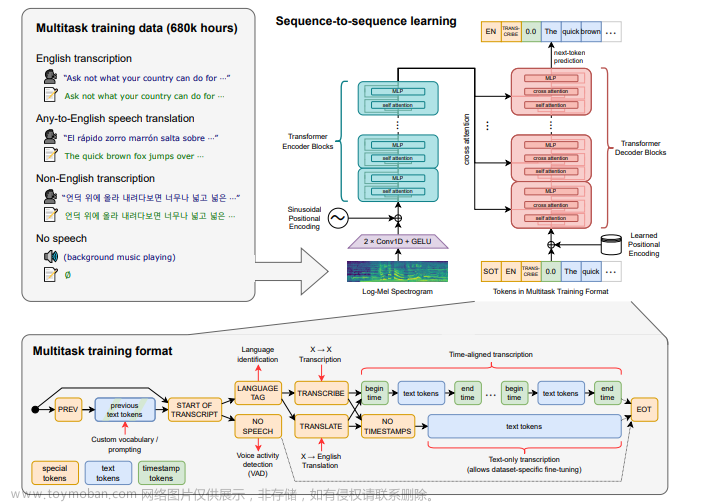
大家新年快乐,事业生活蒸蒸日上,解封的第一个年,想必大家都回家过年,好好陪陪家人了吧,这篇文章也是我在老家码的,还记得上篇我带大家基本了解了whisper,相信大家对whisper是什么,怎么安装whisper,以及使用都有了一个认识,这次作为新年第一篇文章,我将介绍一下自己开发的基于whisper+pyqt5做的一个字幕生成工具,还挺有意思的,中间也遇到各种问题,然后解决。每次尝试做什么,最爽莫过于遇到问题,然后一一解决,最后成功的实现自己想要的,就算是一个再简单的项目,相信大家只要有成长就会很满足开心吧。话不多说,直接进入今天的主题,让我们来看看这个工具。
- 外观
首先让我们来看看工具样子如下图所示,自我吐槽一下,界面挺丑的,不得不感叹自己没有界面审美,不过我已经尽力了,哈哈,不过自我感觉看这个界面还是挺直观的就能知道这个工具的作用,以及使用也很直接方便。主要有两个模块,如图,1为选择模块,2为运行结果显示模块。

文章来源地址https://www.toymoban.com/news/detail-428124.html
- 功能介绍
- 公共选择部分
文章来源:https://www.toymoban.com/news/detail-428124.html

如上图红色框所示,所有功能这几个选择框是公用的,文字应该写的也算清楚,简单介绍一下。
模型选择:必选项,选择一个whisper模型。
语言选择:必选项,选择一个要识别翻译成哪种语言。
计算引擎选择:非必选项,不选默认为cpu。
模型读取保存路径:非必选项,不选默认在应用目录下,如果事先下好模型,可以选择对应目录,避免应用第一次下载找不到模型从而下载模型。
输出文件保存路径:必选项,选择运行生成文件的保存路径。
结束按钮:需要停止正在执行的功能,可以点击此按钮。
- 功能部分
1.生成字幕文件:音频文件或者视频文件根据选择的语言生成一个对应语言的srt字幕文件,文件内容为音频文件或者视频文件说的内容,效果如图所示

2.视频添加字幕:视频文件根据选择的语言自动为视频添加srt字幕,效果如图所示

3.监听声音翻译:监听window的喇叭发出的声音并且识别生成srt字幕文件,不过这个功能因为没时间弄,暂时没弄,后面有时间会加上,界面暂时如下图所示

- 问题以及总结
软件已经介绍完了,在开发过程中其实遇到了很多坑,比如第一次使用pyqt5,跟主要功能模块的信息传递,以及使用pyinstaller打包成应用的时候会遇到很多坑,这里着重记录下。
使用pyinstaller -D 主程序文件打包的时候,运行会有一堆问题,然后仔细看打包过程会有很多警告,有些包没打进去,需要在打包的时候把这些包使用--copy-metadata添加指定包的元数据进来,最后打包成功后,发现python的whisper模块不在应用里,可以将python目录下的whisper复制到应用目录里,然后由于使用到了ffmpeg所以也需要把这个文件复制到应用目录中,才成功运行,本以为万事大吉,但是这个应用会自带cmd窗口,于是在打包命令中添加-w参数,但是又遇到到了挺多问题这里主要记录两个:
1.AttributeError: 'NoneType' object has no attribute 'flush'这个错误,根据提示找到对应python模块sitr-packages/transformers/utils/logging.py的如下代码段,修改如下图所示

2.最后运行应用的时候下载模型会一直卡住,这是由于关闭了窗口,有些代码使用了需要从cmd中获取打印消息或者显示到cmd的功能,所以这里排查到应该是whisper下载模型的时候使用了tqdm来显示进度条导致的,所以到whisper的__init__.py文件中找到这段代码将如下图所示两行代码注释掉即可。

最后再附上打包命令:
pyinstaller --upx-dir=C:\Users\xxx\Desktop\upx\upx-4.0.1-win64 -D -w pythoner_league_translate.py --copy-metadata tqdm --copy-metadata regex --copy-metadata tokenizers --copy-metadata numpy --copy-metadata regex --copy-metadata packaging --copy-metadata filelock --copy-metadata requests --copy-metadata whisper
其中upx地址,可以自己下载一个upx然后替换成你自己电脑路径即可
忘记说了whisper默认的中文是繁体字,这里本人已经把它转换成简体了。
如果大家有兴趣想玩玩,应用我已经帮大家打包好了,可以直接使用,代码也有,下面是各个下载地址:
应用模型下载地址(现在只打包了exe应用,如后续有需要可以打包mac应用):
链接:https://pan.baidu.com/s/1nj174s3tyHUAsazi4tHW0g
提取码:3ugi
代码gihub地址:https://github.com/PythonerLeague/PythonerLeague_translate
最后有问题可以留言或者关注PythonerLeague公众号进行沟通,这次分享就到这里了,最后再祝大家新年开开心心,有时间记得多陪陪家人。
到了这里,关于whisper实践--基于whisper+pyqt5开发的语音识别翻译生成字幕工具的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!