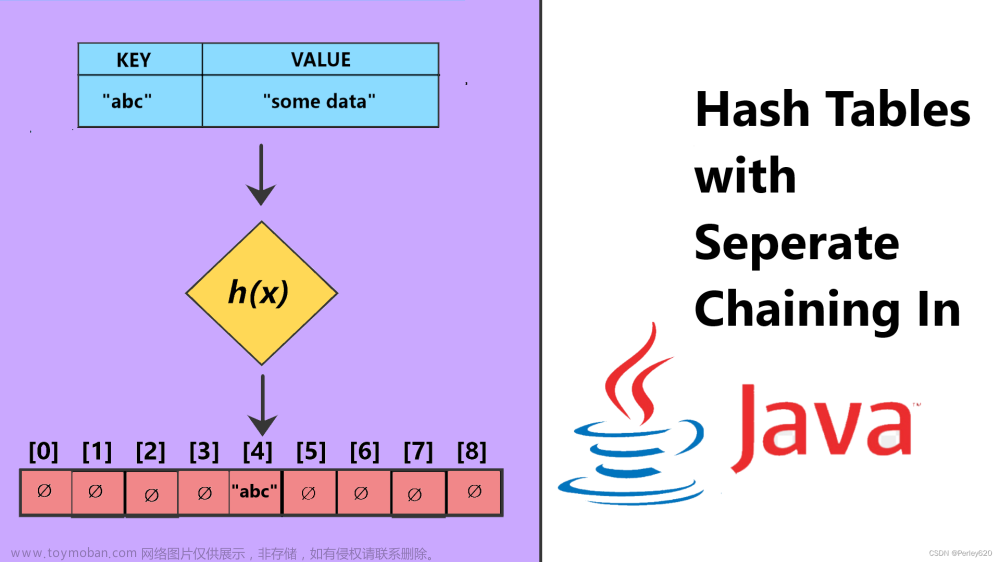
哈希表是什么
哈希表(hash table)又叫散列表。
和二叉树、链表这一类一样。它是一种数据结构,设计出来用于存放数据。
百科解释:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
需要的基础知识
指针和数组
链表
模运算
哈希表的构建方法
- 创建一个固定大小的数组(哈希表),其中每个位置都有一个关联值为null或空链表。
- 对需要存储的数据应用哈希函数(核心)---- 使用取模运算符将数据转换为数组的下标(即关键字 x -- f(x)(哈希函数)--> 下标)
- 将数据存储在该下标位置处(便于查找)。
如下:
| 数组 |
指针 |
指针 |
指针 |
指针 |
指针 |
|||||
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
... |
哈希函数是根据关键字设计的,有很多种函数,主要的原理就是根据数组的大小求模运算。
(关键字) % (数组大小)
例如:20048157 % 17 (结果在0-16)
数组的大小一般设计为质数 -- ?--> 保证均匀分布(即:将输入数据随机(均匀)散布到哈希表的各个位置,避免出现过多冲突)。
遇到冲突怎么办
1、链表式解决(Separate Chaining)
写结构体的时候加入next指针(和链表一样)
数据 Next->数据 Next
遇到冲突的时候,把数据写到next的位置.
例如:
| 数据关键字 |
15 22 24 16 |
| 数组大小 |
7 |
| 哈希函数 |
下标 = 关键字 mod 7 |

↓↓结果
| 下标 |
数据 |
||
| 0 |
|||
| 1 |
15 |
-> |
22 |
| 2 |
16 |
||
| 3 |
24 |
||
| 4 |
|||
| 5 |
|||
| 6 |
产生冲突时,往后面放指针(15->22->...)
2、开放地址(Open Addressing)
不用next指针,把其他下标的位置都对外开放。
开放地址的方法:
a. 线性探测法
如果遇到冲突,就往下一个地址寻找空位。
如果遇到冲突,新位置=原始位置+ i(i是冲突的次数)
例如:
| 数据关键字 |
28 4 12 |
| 数组大小 |
13 |
| 哈希函数 |
下标=关键字 mod 13 |

↓↓结果
| 数组 |
12 |
15 |
2 |
28 |
4 |
38 |
|||||||
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
缺点:容易产生“二次聚集”---- 不同基地址的元素争夺同一个单元的现象叫作“二次聚集”。(也即扎堆)
b. 平方探测法(二次方探测)
如果遇到冲突,就往(原始位置 + i方 )的位置
寻找空位(i 代表冲突的次数)
如果遇到冲突,新位置 = 原始位置 + i方
例如:
| 数据关键字 |
15 2 28 19 10 |
| 数组大小 |
13 |
| 哈希函数 |
下标 = 关键字 mod 13 |

↓↓结果
| 数组 |
15 |
2 |
19 |
28 |
10 |
||||||||
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
c.双哈希
要设置第二个哈希的函数,例如: hash2(key)=R-(key mod R)
R要取比数组尺寸小的质数。
例如R=7: hash2(关键字)= 7- (关键字% 7 )
也就是说,二次哈希的结果在1-7之间,不会等于0;
如果遇到冲突,新位置=原始位置+ i . hash 2(关键字)
例如:
| 数据关键字 |
15 2 18 28 |
| 数组大小 |
13 |
| 哈希函数 |
下标=关键字 mod 13 |
| 哈希函数2 |
7-(关键字 mod 7) |
如果遇到冲突,新位置=原始位置+i.hash 2(关键字)

↓↓结果
| 数组 |
15 |
18 |
2 |
28 |
|||||||||
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
哈希表满了怎办?
再次哈希(Rehashing)
当哈希表数据存储量超过70%,那么就自动新建一个新的哈希表
新表的尺寸是旧表的2倍以上,选择-一个质数
把之前的数据再次通过哈希计算搬到新表里
如果往旧表里再插入-一个数据,那么旧表的存储量将会超过70%
旧表:
| 6 |
15 |
2 |
24 |
13 |
||
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
旧表:下标=关键字mod 7
新表:下标=关键字mod 17
新表:
| 2 |
24 |
6 |
13 |
15 |
||||||||||||
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
为什么设计哈希表
因为哈希表查找的性能快,它比搜索叉树的速度还快。
搜索二叉树的查找速度是0(log2 N),而哈希表发挥稳定的话
可以达到0(1)。文章来源:https://www.toymoban.com/news/detail-428438.html
哈希表的缺点
表越满,性能越差文章来源地址https://www.toymoban.com/news/detail-428438.html
到了这里,关于快速理解哈希(Hash)表的运作原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!