目录
1.项目相关背景
2.搜索引擎的相关宏观原理
3.搜索引擎技术栈和项目环境
4.正排索引 && 倒排索引--搜索引擎原理
5.编写数据去标签与数据清洗的模块 -- parser.hpp
去标签
编写parser(将文件去标签)
编写EnumFile函数
编写ParseFile函数
解析三大部分:
编写SaveFile函数
6.建立索引--编写index.hpp模块
构建正排索引
构建倒排索引
jieba分词
编写倒排索引
7.编写搜索searcher
8.编写http_server模块
测试
引入cpp-httplib库
利用scl源升级gcc
安装cpp-httplib
基本使用测试
正式编写httplib对应的调用
9.编写前端模块
vscode环境配置
编码
编写html
编写css
编写js
1.项目相关背景
- boost的官网是没有站内搜索的,需要我们自己做一个
现在市面上已经有很多搜索引擎,比如百度,搜狗360等等这些公司已经做好的搜索引擎。事实上这些公司写出来的项目都是非常大型的项目,其中的技术门槛非常高。我们自己实现一个完整的搜索引擎是不可能的。但是我们可以写一个简单的搜索引擎,也就是站内搜索,也就是我们今天要写的项目内容。
像百度这种全网型搜索是非常大型的,它需要将全网的信息搜集起来,并将它们保存起来建立相关的索引模块,并且还要根据优先度对他们进行排序,这是一个非常大的工作。
那么站内搜索:它的搜索方式是更垂直的,站内的各个信息相关性更强。
2.搜索引擎的相关宏观原理
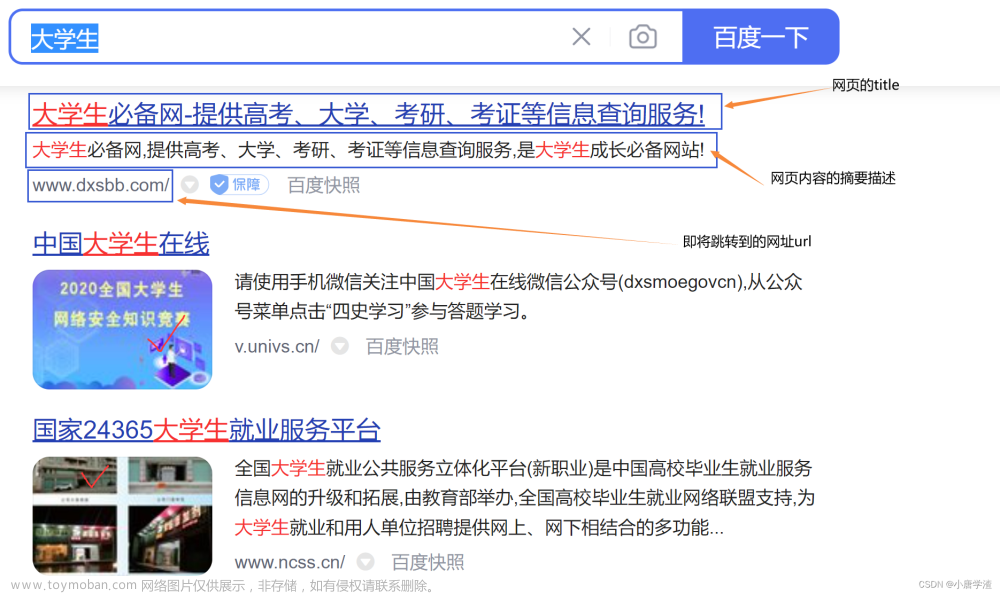
前端通过客户端浏览器通过GET方法向后端服务器进行http请求,通过输入关键词/短语分词来进行查找。后端模块首先将官网html文档导入到磁盘中,方便我们进行去标签的清晰标签工作,里面只保存我们需要让用户看到的标题,摘要以及url;然后将清洗好的数据建立正派索引和倒排索引。再其次进行搜索功能建立,对输入的关键词进行分词,然后查找倒排找到文档 id,然后通过他们不同的权重进行从高到低的排列,最后通过httplib将后端代码和前端交互。

3.搜索引擎技术栈和项目环境
技术栈:C/C++,C++11,STL库,标准库Boost(主要处理一些文件),jsoncpp(序列化反序列化),cppjieba(搜索内容分词)cpphttp-lib(帮我们写http),html5,css,js,jQuery,Ajax.
项目环境:Centos7云服务器,vim/gcc(g++),vs2013/vscode(前端)
4.正排索引 && 倒排索引--搜索引擎原理
假设这里有两个文档:
- 文档1:雷军买了四斤小米
- 文档2:雷军发布了小米手机
正排索引:就是从文档ID找到文档内容(找到文档关键字)
| 文档ID | 文档内容 |
| 1 | 雷军买了四斤小米 |
| 2 | 雷军发布了小米手机 |
我们再来看一个概念:
分词:对目标文档进行分词(为了方便建立倒排索引和查找)
- 对文档1进行分词:雷军买了四斤小米:雷军/买/四斤/小米/四斤小米(四斤小米可以作为一个分词整体)
- 对文档2进行分词:雷军发布了小米手机:雷军/发布/小米/手机/小米手机
停止词:了,的,吗,a,the,一般我们再分词的时候可以不考虑。
倒排索引:根据文档内容,分词,整理不重复的各个关键字,找到对应联系文档ID的方案(也就是根据分词找到文档ID)
| 关键字 (具有唯一性:两个文档都出现,但是我们只保留一份) |
文档ID,weight() |
| 雷军 | 文档1,文档2 |
| 买 | 文档1 |
| 四斤 | 文档1 |
| 小米 | 文档1,文档2 |
| 四斤小米 | 文档1 |
| 发布 | 文档2 |
| 手机 | 文档2 |
| 小米手机 | 文档2 |
注意:文档ID中可以包括weight权重,这样就形成了竞价排名,对权重高的排名在前面,显示在前面。
就比如说你要搜索小米,那么那个文档搜索出来的小米权重高呢,哪个就排在前面
模拟一次查找的过程:
用户输入:小米->倒排索引中查找->提取处文档ID(1,2)->根据正排索引->找到文档的内容->将title标题+conent(desc)文档描述+url网址信息=文档结果进行摘要->构建相应结果
5.编写数据去标签与数据清洗的模块 -- parser.hpp
boost官网:Boost C++ Libraries

因为boost网站没有站内搜索引擎,所以我们要写一个。boost官网中已经给我们提供了字典排序,我们将它下载下来,下载最新的即可。下载好后我们在云服务器上创建一个目录boost_searcher,并将我们刚刚下载好的文件导入进去,通过rz -E +文件即可导入。
上传好之后通过tar xzf boost_1_78_0.tar.gz解压,在boost_searcher中形成了一个目录,这个目录中保存了所有boost内容。

实际上我们用到的boost库中的文件内容,大部分来自于doc下的html文件,html目录中的文件就是各种boost组件对应的组件内容。也就是我们只需要html下的文件:
/boost_searcher/boost_1_78_0/doc/html
我们将html中的内容复制到我们新建的目录data/input下,这个input放的就是boost的数据源,也就是我们8000个数据源。这里的内容就可以来构建我们的站内网页信息了。
[wjy@VM-24-9-centos boost_searcher]$ cp -rf boost_1_78_0/doc/html/* data/input/
去标签
在boost_sercher目录下创建parser.cc文件,用来将原始数据 变成 去标签之后的数据

我们随便打开一个文件看一下里面的源文件
[wjy@VM-24-9-centos input]$ nano process.html
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter?30.?Boost.Process</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="up" href="libraries.html" title="Part?I.?The Boost C++ Libraries (BoostBook Subset)">
<link rel="prev" href="poly_collection/acknowledgments.html" title="Acknowledgments">
<link rel="next" href="boost_process/concepts.html" title="Concepts">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084" alink="#0000FF">
<table cellpadding="2" width="100%"><tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86" src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a></td>
<td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td>
<td align="center"><a href="../../more/index.htm">More</a></td>
</tr></table>
<hr>
<>是html的标签,这些标签对我们搜索是没有价值的,我们需要去除标签,一般标签都是成对出现的。比如<td align="center"><a href="../../index.html">Home</a></td>这一行只要在标签里的都是没有用的,有用的只有Home。
所以我们要将数据清洗,清洗后的数据我们需要放在一个文件中,我们将清洗后的数据放在data目录下的raw_html中
[wjy@VM-24-9-centos data]$ mkdir raw_html
[wjy@VM-24-9-centos data]$ ll
total 20
drwxrwxr-x 60 wjy wjy 16384 Jul 30 19:29 input //这里放的是html原始文档
drwxrwxr-x 2 wjy wjy 4096 Jul 30 19:53 raw_html //这里放的是去标签之后干净的文档
查看input目录下,html文档有多少个
[wjy@VM-24-9-centos input]$ ls -Rl | grep -E '*.html' | wc -l
8141
目标:把每个文档都去标签,然后写入到同一个文件中,每个文档内容不需要任何\n换行!文档和文档之间用\n来进行区分。
XXXXXXXXXXX\3YYYYYYYYYYY\3ZZZZZZZZZZZ\3
为什么是\3?在下面的ascii表中我们可以看到,其中有些字符叫做控制字符,是不可显示的;有些字符是打印字符,现在很多文档中字符都是打印字符,其中\3对应的是^C,它是控制字符,是不会显示在文档中。这样就不会污染文档中的显示字符。文档中显示的只有显示字符。当然你也可以用\4,\5这些不可显示字符作为分隔符。

编写parser(将文件去标签)
我么要将input源文件去标签都放到raw_html中,所以要在raw_html目录下创建一个文档raw.txt,专门用来放这8000多个有效字符串。

[wjy@VM-24-9-centos raw_html]$ touch raw.txt
[wjy@VM-24-9-centos raw_html]$ ll
total 0
-rw-rw-r-- 1 wjy wjy 0 Jul 30 20:33 raw.txt
在去标签之前我们需要将input中的原文档读取出来,读取文档之前需要获取文档的路径,所以我们定义一个字符串,因为data/input和perser.cc在一个目录下,所以定义的路径字符串是const std::string src_path="data/input/";有读取文档目录的路径,就有接收文档路径,data/raw_html/raw.txt,将它定义成一个字符串变量output。
 文章来源:https://www.toymoban.com/news/detail-428626.html
文章来源:https://www.toymoban.com/news/detail-428626.html
下面我们来编写parser.cc的大体框架,我们需要将文档中的一大堆字符串都分成各个文档,分成8000多个文档,放入vector中;然后对每个vector中的string文档进行解析,去标签解析成我们需要的title标题,文档内容content,还有url文档网址,我们将它写成一个结构体。然后将这些解析好的string再放入raw.txt文件下,也即是我们定义的outputstring路径下。文章来源地址https://www.toymoban.com/news/detail-428626.html
[wjy@VM-24-9-centos boost_searcher]$ cat parser.cc
到了这里,关于Boost搜索引擎项目的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[C++项目] Boost文档 站内搜索引擎(5): cpphttplib实现网络服务、html页面实现、服务器部署...](https://imgs.yssmx.com/Uploads/2024/02/642172-1.png)
![[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题...](https://imgs.yssmx.com/Uploads/2024/02/630882-1.gif)
![[C++项目] Boost文档 站内搜索引擎(3): 建立文档及其关键字的正排 倒排索引、jieba库的安装与使用...](https://imgs.yssmx.com/Uploads/2024/02/732017-1.png)






