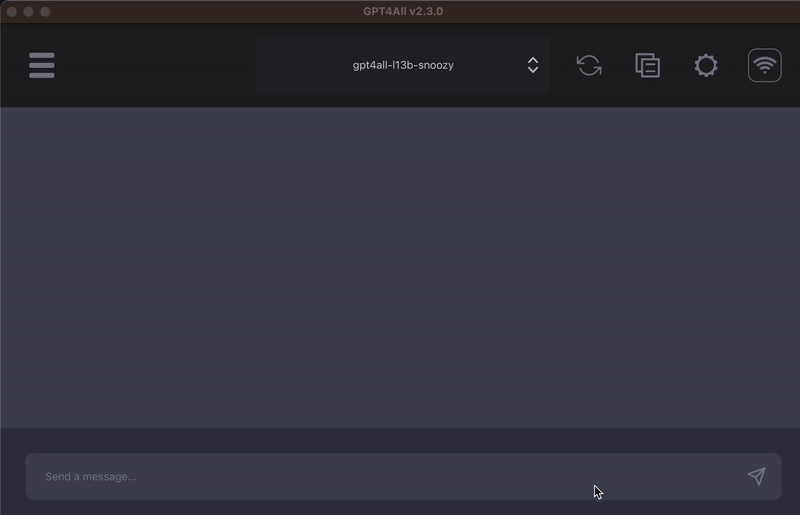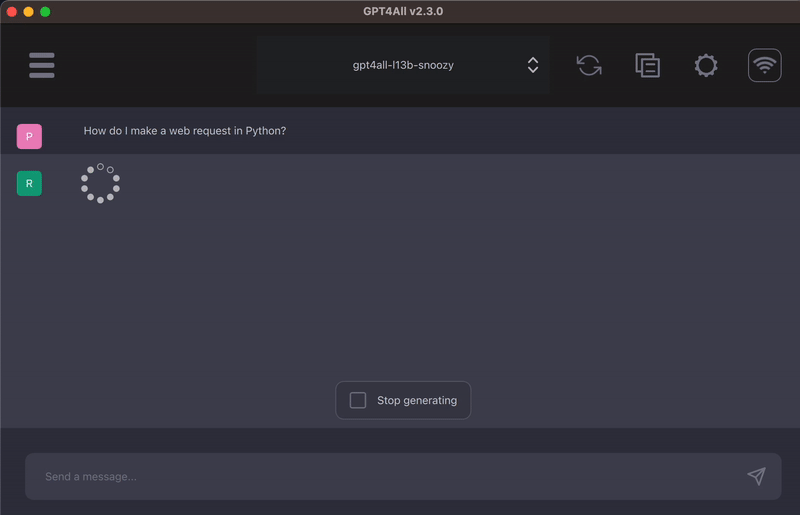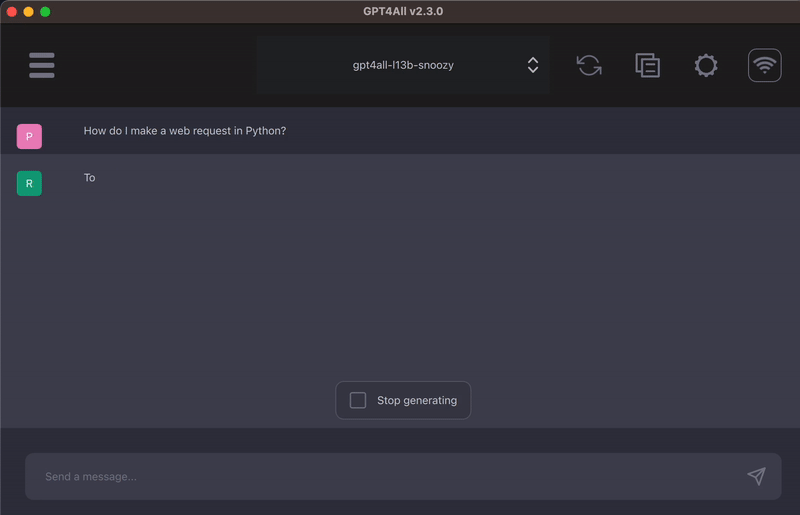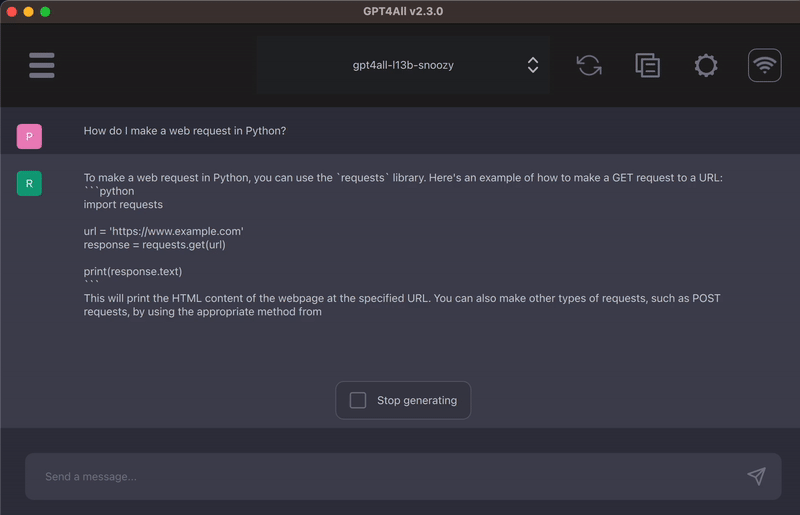
想当初图像生成从DELL到stable diffusion再到苹果的移动部署过了两三年吧
聊天bot才发展几个月就可以边缘部署了,如果苹果更新silicon,npu和运存翻倍,争取apple watch也能本地内置,最快ios18 mac、ipad、iPhone能内置吧
又是一个平民百姓都高兴的开源项目,chatGPT这种级别的模型甚至能部署到树莓派上运行,然后在操作的过程中也遇到一些问题,这篇就是记录步数的这个过程。
已经为最新版的github更新了(2023.5.23),可以放心食用,实测运行速度快了很多。
哈工大的chinese llama效果不如vicuna7b,所以我把这一块的内容给删掉了。
vicuna7b的合成需要高运行内存的电脑,如果你的电脑不足30个G,可以直接私信我要合成好的模型,只有vicuna-7b的q4.0版本。
最近很多人反应老的vicuna-7b已经没办法在新的llama.cpp上使用了(主要是q4版本),可以问我要新的。
大佬的网址:https://github.com/ggerganov/llama.cpp
下载及生成
打开命令行输入下面的指令
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
#对于Windows和CMake,使用下面的方法构建:
cd <path_to_llama_folder>
mkdir build
cd build
cmake ..
cmake --build . --config Release

模型下载
我觉得模型下载是最麻烦的,还好有别人给了
git clone https://huggingface.co/nyanko7/LLaMA-7B
好吧我直接给百度云
链接: https://pan.baidu.com/s/1ZC2SCG9X8jZ-GysavQl29Q 提取码: 4ret
–来自百度网盘超级会员v6的分享

然后安装python依赖,然后转换模型到FP16格式。然后第一个小bug会出现。
python3 -m pip install torch numpy sentencepiece
# convert the 7B model to ggml FP16 format
python3 convert-pth-to-ggml.py models/7B/ 1

他会报找不到文件。
打开convert-pth-to-ggml.py文件,修改"/tokenizer.model"的路径,再运行python3 convert-pth-to-gaml.py ./models/7B 1,我顺便名字也改了。
文件找到了,然后出现第二个bug。。。。。
我一开始找不出问题,后来对比原网址和7B文件夹里的文件,才发现文件大小根本都不一样,我说几十个G的东西怎么git这么。
打开网站下图这个网址,点红色框的那两个下载。替换掉7B文件夹里的那两个文件。

将模型再转换成4位格式
# quantize the model to 4-bits
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2

推理
# run the inference
./main -m ./models/7B/ggml-model-q4_0.bin -n 128

想和chatGPT一样对话的话用下面这个指令,-n 控制回复生成的最大长度, --color是区分ai和人类的颜色,-i 作为参数在交互模式下运行, -r 是一种反向提示,-f 是一整段提示, --repeat_penalty 控制生成回复中对重复文本的惩罚力度,–temp 温度系数,值越低回复的随机性越小,反之越大。
更新了之后速度快了很多。
./main -m ./models/7B/ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
让我们打开prompts/chat-with-bob.txt来看一下。
我们可以看到这相当于给了ai模型一个场景话题,然后你和ai之间就可以接着这个话题聊天。
我英文名叫zale,然后我把这个机器人叫作kangaroo,这样的身份和他聊天,你可以按自己的喜欢自己修改下面的代码。
./main -m ./models/7B/ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "Zale:" \
写一个txt文件
"Transcript of a dialog, where the Zale interacts with an Assistant named Kangaroo. Kangaroo is helpful, kind, honest, good at writing, and never fails to answer the Zale's requests immediately and with precision.
Zale: Hello, Kangaroo.
Kangaroo: Hello. How may I help you today?
Zale: Please tell me the largest city in Europe.
Kangaroo: Sure. The largest city in Europe is Moscow, the capital of Russia.
Zale:"

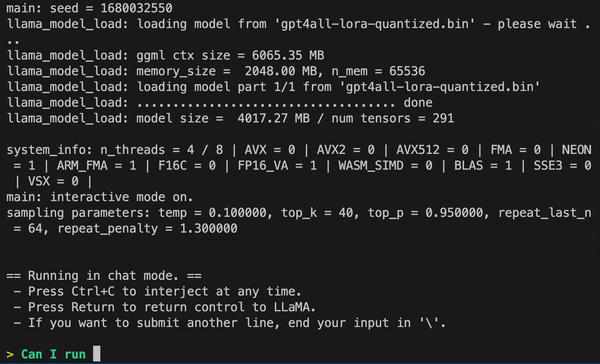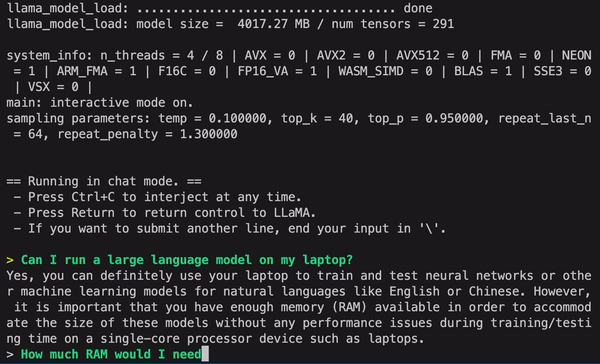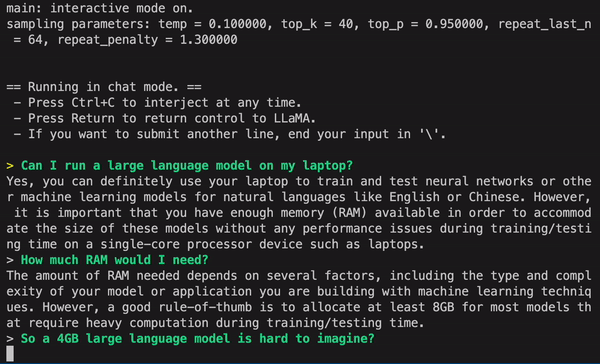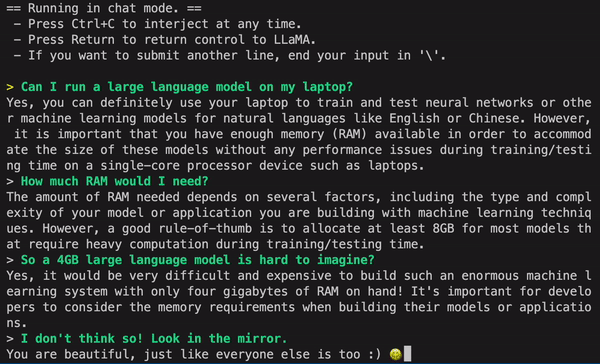
有点呆呆的,不过也算边缘部署的巨大进步了!
一个蛮有意思的发现,明明看得懂中文却跟我说不懂中文。。。。。
分享一段有意思的对话
Vicuna-7B
把原始的llama模型转换成huggleface的格式
python3 ~/anaconda3/envs/pytorch2/lib/python3.10/site-packages/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir ./llama-7b \
--model_size 7B \
--output_dir ./llama-7b-hf
这样生成的文件放在llama-7b-hf之中。
下载vicuna7b的权重文件,也可以理解为补丁。
注意融合vicuna7b模型需要30个G的内存,我特意买128G内存和4090的电脑,
如果有需要,可以私信我我看到的话直接把生成的模型发给你。
还有就是现在的模型是v1.1的版本,必须搭配使用transformers>=4.28.0 and fschat >= 0.2.0
python3 -m fastchat.model.apply_delta \
--base-model-path ./llama-7b-hf/ \
--target-model-path ./vicuna-7b/ \
--delta-path ./vicuna-7b-delta-v1.1/
这样融合的模型就在vicuna-7b的文件夹下。
可以直接用fastchat用测试一下,速度好快哦!!!确实fast
python3 -m fastchat.serve.cli --model-path ./vicuna-7b
回到llama.cpp之中,老三样
python3 convert-pth-to-ggml.py models/vicuna-7b/ 1
./quantize ./models/vicuna-7b/ggml-model-f16.bin ./models/vicuna-7b/ggml-model-q4_0.bin 2
./main -m ./models/vicuna-7b/ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt


实测理解能力和中文水平我认为都是目前最佳的边缘部署的模型,我觉得我可以把哈工大的中文模型部分给删了。目前使用下来不错,很有chatGPT那味。
我又试了一下i9-13900KF,速度是快了一些。
来点好玩的例子。

多模态部署
这个需要12g的显存,没有的朋友就图个乐。
用到的是miniGPT这个库。
1.准备环境
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4

2.修改文件指向电脑里的vicuna-7b路径
3.下载pretrained MiniGPT-4 checkpoint
4.修改文件指向电脑里的pretrained MiniGPT-4 checkpoint路径
5.运行demo
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
 文章来源:https://www.toymoban.com/news/detail-428792.html
文章来源:https://www.toymoban.com/news/detail-428792.html
StableVicuna
据说效果远超原版vicuna,实测直接用transformer4.8.0即可转换,然后转换的原模型是huggle face格式的llama原模型。
之后的步骤不再重复和上面一样,运行起来似乎失去了中文能力,然后数学能力等有提升,感觉像文科生变成理科生。 文章来源地址https://www.toymoban.com/news/detail-428792.html
文章来源地址https://www.toymoban.com/news/detail-428792.html
到了这里,关于无需GPU无需网络“本地部署chatGPT”(更新多模态)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!