目录
1.简介
1.什么是EMR
2.组成
3.与自建hadoop集群对比
4.产品架构
2.使用
1.创建EMR集群
1.登录EMR on ECS控制台
2.软件设置
3.硬件设置
3.基础配置
2.配置
1.组件配置
2.用户管理
3.安全组
4.Gateway
5.trino配置
6.ranger配置
7.LDAP认证
3.组件UI
4.监控告警
1.ECS磁盘内存等监控
2. EMR组件服务状态监控
5.脚本操作
1.手动执行
2.引导操作
3.遇到的问题
1.emr-cli
1.ecs部署了emr-cli,然后使用spark的时候会报错,但是在emr管理的机器上启动没这个问题
1.简介
1.什么是EMR
EMR是运行在阿里云平台上的一种大数据处理的系统解决方案。可以简单的理解为一个对标ambari的产品。EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark。可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR提供on ECS和on ACK两种方式,on ACK指的是容器化。
2.组成
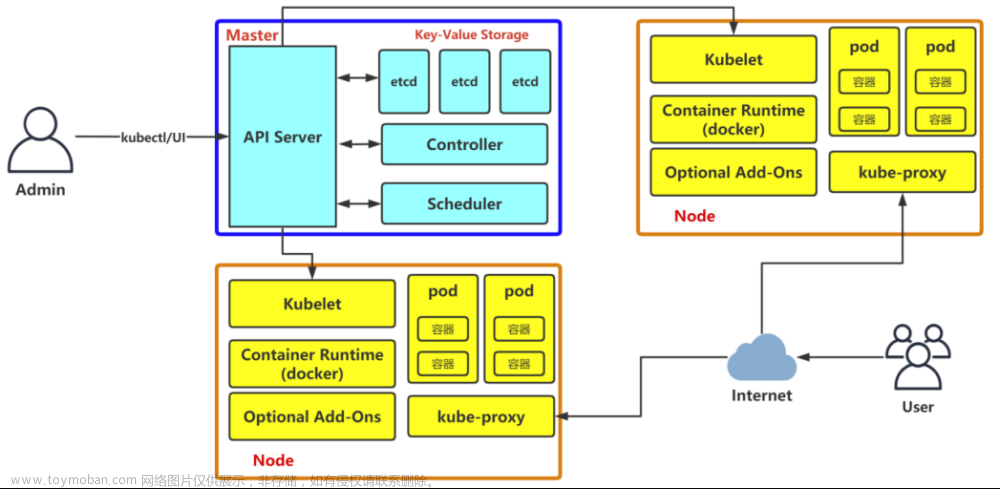
E-MapReduce的核心是集群。E-MapReduce集群是由一个或多个阿里云ECS实例组成的Hadoop、Flink、Druid、ZooKeeper集群。以Hadoop为例,每个ECS 实例上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager和NodeManager),这些daemon进程共同组成了Hadoop集群。

- Master节点,部署了Hadoop的主节点服务,包括HDFS NameNode、HDFS JournalNode、ZooKeeper、YARN ResourceManager和HBase HMaster等服务,可以根据集群的使用场景,选择高可用集群或非高可用集群。测试环境可以选择非高可用集群,生产环境建议选择高可用集群。高可用集群可以选择2个或3个Master节点,当选择2个Master节点时,HDFS JournalNode和ZooKeeper会部署在Core的emr-worker-1节点。生产环境建议创建高可用集群时选择3个Master节点。
- Core节点,部署了HDFS DataNode和YARN Nodemanager,用于HDFS数据的存储和YARN的计算,不可以弹性伸缩。
- Task节点,部署了YARN NodeManager,用于YARN计算,可以通过弹性伸缩的方式灵活扩容或缩容。
- Gateway集群,部署了Hadoop的客户端文件,您可以通过Gateway提交作业,避免直接登录集群产生的安全和客户端环境隔离问题。您需要先创建Hadoop集群,然后创建Gateway集群关联至Hadoop集群。
3.与自建hadoop集群对比
| 对比项 | 阿里云EMR | 自建Hadoop集群 |
|---|---|---|
| 成本 | 支持按量和包年包月付费方式,集群资源支持灵活调整,数据分层存储,资源使用率高。无额外软件License费用。 | 需提前预估资源,且资源相对固定,资源使用率低。采用Hadoop发行版,需额外支付License费用。 |
| 性能 | 较开源版本性能大幅提升。 | 采用开源社区版本,性能需自行优化。 |
| 易用性 | 分钟级别启动Hadoop集群,敏捷响应业务需求。 | 采购服务器,部署Hadoop生态组件,周期长达数周。 |
| 弹性 | 可根据作业临时启动和销毁集群。集群资源可根据时间周期或集群负载动态自动调整。基于JindoFS计算存储分离架构,轻松分别扩展计算和存储资源。 | 计算和存储耦合,资源相对固定,无法弹性调整资源。 |
| 安全 | 支持企业级多租户资源管理,支持对表、列、行级别的权限控制和日志审计,支持数据加密。 | 多租户管理能力需自行配置,能力不完善,无法满足企业级需求。 |
| 可靠 | 大规模、企业级环境的检验,随开源版本升级,并经过专业的兼容性验证测试,提供优于社区版本的使用体验。 | 需自行更新和升级开源版本,验证各组件版本兼容性,自行修复社区bug。 |
| 服务 | 专业和资深大数据专家技术服务团队提供售后支持。 | 社区版本无服务支持,Hadoop发行版,需额外支付License和服务费用。 |
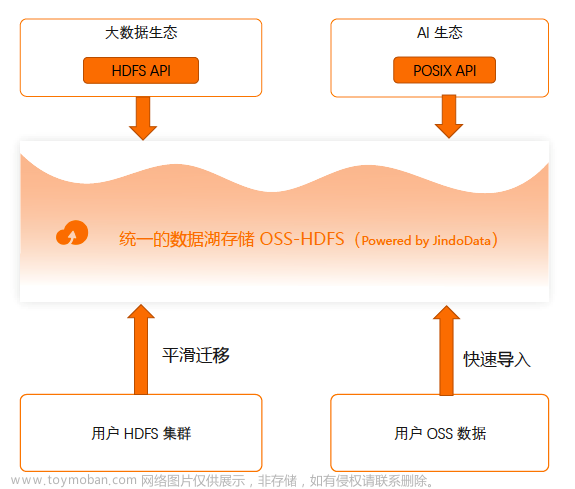
4.产品架构

2.使用
1.创建EMR集群
1.登录EMR on ECS控制台

2.软件设置
根据实际情况选择地域和资源组。
这里选择是数据湖的场景,如果有数据分析的可以重新再另建一个数据分析的EMR集群,这样以便于计算资源的隔离,如果不同的业务使用一个集群那资源就是混用的。
如果是生产环境需要开启服务高可用,服务高可用将会使用3个master节点保障服务的高可用。
元数据我们选择DLF统一元数据管理,当然也可以使用自建的RDS,不过这样就需要自己买个mysql的费用。
DLF数据目录我们使用默认的就好,也可以自建创建一个目录,如果其他EMR集群使用了同一个DLF数据目录,那就是使用的同一个元数据信息,这个需要注意。后面我们可以通过DLF 元数据管理对元数据进行查询及管理。
Hive存储模式使用数据湖存储,使用OSS-HDFS作为数据存储,所以这里需要我们在创建集群之前需要创建一个OSS的bucket,并开通OSS-HDFS服务。
Hive数据仓库路径这里填入前面创建OSS的bucket

3.硬件设置
付费类型,如果短期使用的我们选择按量付费,如果是长期选择包年包月。
专有网络,也就是vpc用于网络隔离的。
可用区我们这里选择和业务系统在同一个地域的同一个可用区内,保证效率。
节点组,master节点这个是不能扩容的,所以需要我们前面规划好。Master节点主要用来存储HDFS元数据和组件Log文件,属于计算密集型,对磁盘IO要求不高。HDFS元数据存储在内存中,建议根据文件数量选择16 GB以上内存空间。
Core节点会同时运行DataNode和Nodemanager。作为存储和计算节点使用,我们可以把数据存在OSS中,集群中的HDFS仅作为YARN任务分发的临时存储空间使用。
core节点的云盘不支持卸载和缩容,只支持扩容。如果卸载云盘和缩容会导致集群出问题。
core节点必须有一个数据盘,计算过程生成的临时文件会在disk1下,hdfs才会用到所有的数据盘,所以如果使用oss作为存储的话那只需要一个数据盘就行了。
查看集群组件服务的日志可以去/mnt/disk1/log目录下查看
3.基础配置
身份凭证建议使用密钥对,这样更安全。
2.配置
1.组件配置
1.hive
点击集群服务->选择Hive配置,修改配置项
hive.execution.engine=tez
hive.metastore.warehouse.dir=ossxxx/apps/hive/managed/warehouse/
hive.metastore.warehouse.external.dir=ossxx/apps/hive/warehouse
metastore.create.as.acid=false
//表最后访问时间,设置下列参数之后阿里云dlf接口可以获取最后访问时间,但是发现不准,建议通过how table extended like 'xx'方式获取
set hive.exec.pre.hooks = org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook$PreExec;2.hadoop-common
fs.trash.interval=3603.hdfs
dfs.replication=3
dfs.namenode.avoid.read.stale.datanode=true
dfs.namenode.acls.enabled=true
dfs.namenode.avoid.write.stale.datanode=true
dfs.cluster.administrators=hdfs
dfs.permissions.superusergroup=hdfs4.yarn
mapreduce.job.counters.max=1000
mapreduce.task.io.sort.mb=200
//调大之后每个sqoop的容器都占用较多资源
mapreduce.map.memory.mb=2048
mapreduce.reduce.memory.mb=12288
mapreduce.reduce.shuffle.parallelcopies=30
mapreduce.task.io.sort.factor=100
yarn.app.mapreduce.am.resource.mb=6144
yarn.scheduler.minimum-allocation-mb=2048
//必须大于12g,因为spark jdbc thrift服务需要大于12g内存,具体大小根据总内存大小设置
yarn.scheduler.maximum-allocation-mb=24576
yarn.scheduler.maximum-allocation-vcores=24
#maper-site.xml新增 是否遍历目录
mapreduce.input.fileinputformat.input.dir.recursive=true
//每个节点可以分配的虚拟cores,节点是32c的,默认是64,文档说大内存规格设置物理核数的2倍,这里我们使用默认值
yarn.nodemanager.resource.cpu-vcores=64
//每个节点可以分配的内存。节点是128g的,默认是内存的80%,也就是104857,我们设置为内存的70%
yarn.nodemanager.resource.memory-mb=91750
5.spark
#开启强制转换
spark.sql.legacy.timeParserPolicy=LEGACY
spark.sql.storeAssignmentPolicy=LEGACY
#设置仓库地址
hive.metastore.warehouse.dir=ossxxx/apps/hive/managed/warehouse/
hive.metastore.warehouse.external.dir=ossxx/apps/hive/warehouse
#开启日志清理
spark.history.fs.cleaner.enabled=true
#新增配置,因为hive3.1.0之后from_unixtime时间是使用的utc时间,改不了,所有把spark改成和hive一样使用utc时间,在业务使用的时候加上8个小时,from_unixtime(8*60*60+
spark.sql.session.timeZone=UTC2.用户管理
我们前面选择的knox,它可以让我们通过公网方式访问HDFS、YARN、Spark和Ganglia等Web UI页面,它可以帮助我们只开放一个端口访问所有的UI。
点击EMR集群->点击用户管理->添加用户,选择我们要添加的用户,然后设置密码,这个用户和密码用于后面访问组件UI的时候的验证。
3.安全组
knox默认使用了8443端口,所以在安全组中我们手动添加8443端口,授权对象为需要访问资源机器的ip地址。
4.Gateway
Gateway 主要用于向计算集群提交任务和进行安全隔离。部署组件客户端,访问EMR集群。
其部署过程如下
- 在 ECS 控制台创建 ECS 实例
- 在 ECS 实例安装 EMR-CLI 工具,并配置认证信息
- 通过 EMR-CLI 命令完成部署客户端软件包、同步集群配置及更新软件包操作。
部署完成之后各客户端使用的配置文件默认存在/etc/taihao-apps目录下,在这里可以查看组件config。
在ECS实例安装EMR-CLI工具过程如下:
需要注意的是,如果使用spark客户端需要配置Gateway节点的域名解析。
如何创建ECS实例并基于EMR-CLI快速部署Gateway环境_开源大数据平台 E-MapReduce-阿里云帮助中心
5.trino配置
1.设置内存
调整query.max-memory、query.max-total-memory、query.max-memory-per-node大小,并且query.max-memory-per-node的内存大小+ heap headroom的内存必须小于jvm的内存。其中heap headroom默认大小是10G,修改之后重启trino生效。
我们机器是64G,这里我们配置为64g的80%,配置的过高有可能导致内存溢出

这里至少要配置的比前面的52G小10G。我们配置32G避免内存撑爆,可以适当调大一点,注意观察后台日志

2.设置warehouse
将hive.properties中的dlf.catalog.default-warehouse-dir值设置为hive中的hive.metastore.warehouse.dir值,这个值好像不设置也没影响。
3.设置dlf.catalog.id
将dlf.catalog.id设置为hive中的dlf.catalog.id值,这个值设置一下,不然trino无法访问到元数据信息,造成查不到数据。

4.设置不压缩
trino生成的文件默认压缩为gz,可以设置为不压缩
在hive.properties中新增属性
hive.compression-codec=NONE
6.ranger配置
1.ranger配置
以hive为例,ranager支持权限校验的访问方式有
- 通过Beeline客户端访问HiveServer2。
- 通过JDBC URL连接HiveServer2。
- 进入集群服务页面。
- 登录EMR on ECS控制台。
- 顶部菜单栏处,根据实际情况选择地域和资源组。
- 在集群管理页面,单击目标集群操作列的集群服务。
- Ranger启用Hive。
- 在集群服务页面,单击Ranger-plugin服务区域的状态。
- 在服务概述区域,打开enableHive开关。
- 在弹出的对话框中,单击确定。
- 重启HiveServer。
- 在集群服务页面,选择 > Hive。
- 在组件列表区域,单击HiveServer操作列的重启。
- 在弹出的对话框中,输入执行原因,单击确定。
- 在确认对话框中,单击确定。
如要启用其他组件,可以参考如何集成Hive到Ranger并配置权限_开源大数据平台 E-MapReduce-阿里云帮助中心
2.ranger ui
ranger配置完成之后,我们需要配置用户相应的权限
1.hadoop sql

给相应账号设置库表权限

给数据表字段进行脱敏 ,使用beeline客户端访问表敏感字段显示*。


7.LDAP认证
服务开启LDAP认证功能后,访问服务需要提供LDAP身份认证(LDAP用户名和密码),可以提升服务的安全性。
以trino启动LDAP认证说明
前提条件集群已选择了Trino和OpenLDAP服务。
开启步骤如下
1.启动TRINO-LDAP

2.重启trino服务

3.下载keystore到需要使用trino服务的机器节点
keystore的固定存放位置在master1上的/etc/emr/trino-conf/keystore
4.添加ldap用户

4.配置jdbc链接trino
url必须为trino服务中master-1的地址,如果客户端和trino集群在同一个集群,那通过DNS解析也是可以的。例如在windows的hosts中配置master-1到ip地址的解析就行
用户和密码为前面添加的ldap用户密码。
SSLKeyStorePath为keystore在需要使用trino服务机器节点上的存放位置
SSLKeyStorePassword通过在trino服务master-1上执行awk -F= '/http-server.https.keystore.key/{print $2}' ${TRINO_CONF_DIR}/config.properties查看

3.组件UI
点击集群->访问链接与端口。点击之后输入我们前面添加的用户和密码访问。
4.监控告警
1.ECS磁盘内存等监控
通过云监控->报警服务,设置报警规则达到我们的监控ECS磁盘和内存使用率等目的。


2. EMR组件服务状态监控
1.我们可以通过上面的设置报警规则达到我们的目的。例如下面我们监控HDFS DN的存活。
这种方式有些指标做不到,例如没有指标可以监控trino。

2.我们通过系统监控中的系统事件去监控


5.脚本操作
通过脚本操作我们可以实现对所有节点的批量操作,例如添加udf函数等
1.手动执行
对已经创建完成的节点进行手动批量操作,例如我们给trino添加udf函数。
创建一个脚本放到oss上面,注意放到oss上面之前需要通过dos2unix转一下文件格式

选择刚刚存放的脚本位置

点击确定之后就会在刚刚选中的执行节点执行刚刚的脚本。
2.引导操作
引导操作用来对集群扩容或者弹性伸缩的节点进行批量操作,操作方式如上面,唯一的区别只是触发时间改成了扩容的时候。
3.遇到的问题
1.emr-cli
1.ecs部署了emr-cli,然后使用spark的时候会报错,但是在emr管理的机器上启动没这个问题

解决方法:
gateway 上的/etc/taihao-apps/spark-conf/spark-defaults.conf 的配置有问题。在这个文件里找这两个配置,看一下 -Dlog4j.configuration 这个参数配的是什么,检查一下gateway集群上指向的文件是否存在,没有就会报错。

改成 /etc/taihao-apps/spark-conf/log4j.properties 就可以了
2.hive
1.spark建的表和hive建的表关联出来的结果是错的
这个是tez的bug,当使用不同的bucket_version连接多表时,会发生数据丢失。因为不同的bucket_version会选用不同的hash算法。由于哈希算法的不一致性,导致分区的数据分配不同。在Reducer阶段,具有相同密钥的数据不能配对,导致数据丢失。详情可参考[HIVE-22098] Data loss occurs when multiple tables are join with different bucket_version - ASF JIRA
解决办法:
spark建表时指定和hive on tez的bucketing_version一致
TBLPROPERTIES (
'bucketing_version'='2')
3.spark
1.spark创建任务数过多的时候,报无法创建线程

解决办法:
排查当前机器内存和当前提交任务用户的线程数限制
free -g
//注意切换用户,当前线程数限制
ulimit -u
//注意切换用户,系统用户当前的线程数
ps -eLf | wc -l
//如果是线程数限制导致的,则调大线程数限制文章来源:https://www.toymoban.com/news/detail-429577.html
/etc/security/limits.d/20-nproc.conf文章来源地址https://www.toymoban.com/news/detail-429577.html
到了这里,关于阿里云EMR集群搭建及使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!