配合视频教程使用更佳:【1行代码提取6种TCGA表达矩阵和临床信息】 https://www.bilibili.com/video/BV12R4y197Ne/?share_source=copy_web&vd_source=abc21f68a9e2a784892483fd768dbafa
之前写了一个脚本,可以让大家1行代码提取6种类型的表达矩阵以及对应的临床信息。但是很多人完全看不见注意事项或者根本看不懂,所以我决定改动一下。
上一版的脚本主要报错是这个:
Error in GDCprepare(query, save = T, save.filename = "tcga_read.rdata") :
I couldn't find all the files from the query. Please check if the directory parameter is right or `GDCdownload` downloaded the samples.
原因无非就是3种可能:
-
TCGAbiolinks的版本不是2.25.1以上 - 路径不对
- 下载的方式不正确
首先解决R包版本的问题
你可以用以下代码检查自己的TCGAbiolinks包的版本:
packageVersion("TCGAbiolinks")
## [1] '2.25.2'
如果是在2.25.1以下,需要安装开发版本的TCGAbiolinks包,安装方法如下:
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("BioinformaticsFMRP/TCGAbiolinksGUI.data")
BiocManager::install("BioinformaticsFMRP/TCGAbiolinks")
安装完成后,重新使用packageVersion("TCGAbiolinks")查看版本。
如果你用上面的安装代码报错,那么你的R语言基础可能不过关,你需要参考以下教程:可能是最好用的R包安装教程!
然后是路径问题
**路径必须要正确,你位置都搞错了,代码找不到你放文件的位置,那肯定是报错!**路径设置可以参考这篇推文:手动下载的TCGA也是可以用TCGAbiolinks整理的。
我在里面说的非常清楚,你的文件路径必须是在GDCdata\TCGA-COAD\harmonized\Transcriptome_Profiling\Gene_Expression_Quantification这个路径下,而且脚本getTCGAexpr.r必须和GDCdata在同一个文件夹下!!!!

下载方式问题
如果你是直接用TCGAbiolinks下载的数据,那么路径一般不会有大问题,只要你把脚本和GDCdata放在同一个文件夹下就行了。
如果你是在官网下载的,或者用gdc_clinet下载的,就必须按照这篇推文介绍的方法进行选择:可能是最适合初学者的TCGA数据下载教程,**命令行或者图形界面都可以,关键是选择的时候一定要选对!!**如果没选对,就会出现开头所示的报错!!
以上3个问题,我在脚本使用注意里都明确说明了,实在是不懂为什么还有那么多问题!!!
2.0版本
我觉得有一部分是我的原因,作为一个已经学会的人,我已经忘记了自己不会的时候是什么样子,现在也无法理解初学者为什么会遇到那么多报错。
所以我改了一下脚本,1行代码下载并整理6种类型的TCGA表达矩阵和临床信息!!
主要是以下改进:
- 在任何位置都可以运行,不需要构建路径!
- 会自动下载数据,不需要手动下载
2.0版本的脚本我也放在了QQ群里,需要的加群下载即可。
使用方法和之前一模一样!!
但我还是建议你先看一下使用注意!!
- 需要良好的网络
-
TCGAbiolinks包的版本必须要在2.25.1以上
下面是使用方法:
加载需要的R包:
library(TCGAbiolinks)
library(SummarizedExperiment)
library(tidyverse)
加载脚本"getTCGAexpr.r":
source("getTCGAexpr.r")
使用函数,需要提供TCGA的癌症简称,比如:TCGA-LUSC。
getTCGAexpr(project = "TCGA-LUSC")
这个脚本会自动从GDC官网下载最新的数据,所以需要联网,如果你的网络不好,可以手动下载,按照这篇推文自己构建合适的路径:xxxxxxx,它也可以成功!
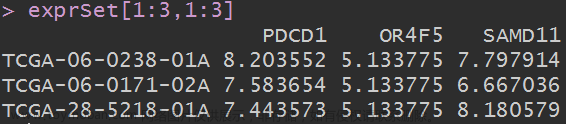
完成后会在当前目录多出一个output_expr文件夹,里面就是6个表达矩阵和临床信息文章来源:https://www.toymoban.com/news/detail-429781.html
 文章来源地址https://www.toymoban.com/news/detail-429781.html
文章来源地址https://www.toymoban.com/news/detail-429781.html
- TCGA-LUSC_expr.rdata:原始的se对象,所有信息都是从这里面提取的;
- TCGA-LUSC_clinical.rdata:TCGA-LUSC的临床信息;
- TCGA-LUSC_lncRNA_expr_counts.rdata:lncRNA的counts矩阵;
- TCGA-LUSC_lncRNA_expr_fpkm.rdata:lncRNA的fpkm矩阵;
- TCGA-LUSC_lncRNA_expr_tpm.rdata:lncRNA的tpm矩阵;
- TCGA-LUSC_mRNA_expr_counts.rdata:mRNA的counts矩阵;
- TCGA-LUSC_mRNA_expr_fpkm.rdata:mRNA的fpkm矩阵;
- TCGA-LUSC_mRNA_expr_tpm.rdata:mRNA的tpm矩阵;
到了这里,关于新版TCGA表达矩阵1行代码提取2.0版的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!