以下实验源码均使用Scala语言编写。
作业中使用的输入文件可以通过以下网盘地址下载:
https://pan.baidu.com/s/1J8miFmJ6RVZKZqe2O5gAwg
提取码:ethn
输入文件放置在项目根目录下的file文件夹(也可以根据实际情况进行调整)。
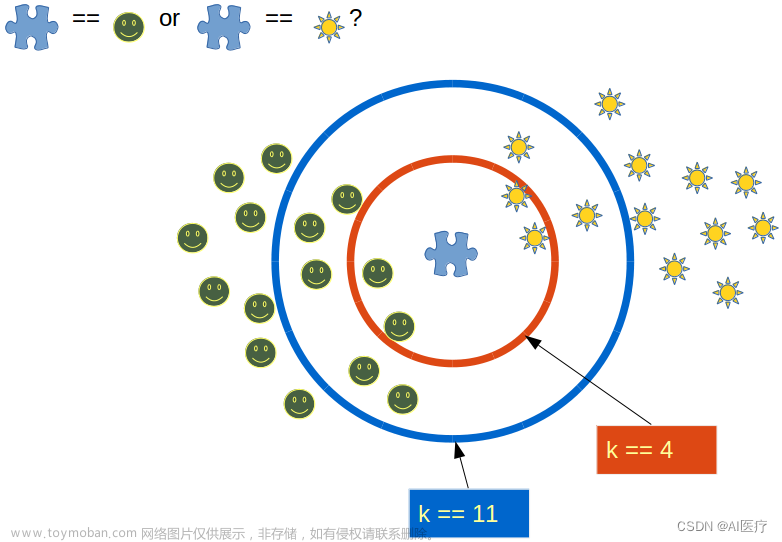
大作业一:基于Spark的K近邻(KNN)查询
问题描述:
在空间中共有N个点,每个点由R维向量表示其坐标,对于一个点,KNN指距离其最近的K个点的集合,距离为欧几里得距离。
参数:
K = 20(返回近邻的个数)
R = 4(每个点的坐标维度)
要查询KNN的坐标 (0,0,0,0)
输入文件: KNN-input.txt
i,a,b,c,d (共1000行,每行开始一个整数i,表示点的id,之后4个整数,表示坐标,数据之间以”,”分割)
输出结果:文章来源:https://www.toymoban.com/news/detail-429799.html
- 问题1:输出K个整数,为查询的K近邻结果的id,按照距离升序排序(如果距离相等优先输出id靠前的)。
- 问题2:输出1个浮点数,为K近邻距离的平均值
- 问题3:输出1个浮点数,为K近邻距离的方差
题解:
import org.apache.spark.{SparkConf, SparkContext}
object KNN {
val parameter_K: Int = 20 //KNN中的参数K
val pivot: Array[Int] = Array(0,0,0,0) //要查询KNN的坐标
def main(args: Array[String]): Unit = {
//步骤1:启动spark并读入数据
val sparConf = new SparkConf().setMaster("local").setAppName("KNN")
val sc = new SparkContext(sparConf)
val lines = sc.textFile("file\\KNN-input.txt")
val array = lines.collect()
//步骤2:定义相关函数
//字符串处理,返回(Array[Int], Int)元组
def String_Split(str : String) = {
val arr = str.split(",").map(x_ => x_.toInt)
(arr.slice(1,arr.length),arr(0))
}
//计算到数组中所有点到某个点的距离,并返回(Array[Int], Int, Double)元组
def Calculate_Distance(t : (Array[Int], Int), p : Array[Int]) = {
val arr = t._1
var dist: Int = 0
for(i <- arr.indices){
val diff = arr(i) - p(i)
dist += diff * diff
}
(arr,t._2,math.sqrt(dist))
}
//计算数组平均值
def Calculate_Average(arr: Array[Double]) = {
var sum: Double = 0
arr.foreach(x => sum += x)
sum/arr.length
}
//计算数组方差
def Calculate_Variance(arr: Array[Double]) = {
val avg = Calculate_Average(arr)
var variance: Double = 0
arr.foreach(x => {val diff = x - avg; variance += diff * diff})
variance/arr.length
}
//步骤3:进行KNN算法
//进行字符串处理
val ret = array.map(String_Split)
//对数组每个元素依次计算到pivot的距离
.map(t => Calculate_Distance(t,pivot))
//按照距离为第一优先级,id为第二优先级排序
.sortWith((a,b) => if(a._3 == b._3) {a._2 < b._2} else {a._3 < b._3})
//最后选取前K个元素
.slice(0,parameter_K)
//步骤4:提取ret的ID和距离,赋值给ids和distances数组
val ids = ret.map(t => t._2)
val distances = ret.map(t => t._3)
//步骤5:输出数据
ids.foreach(x => {print(x);print(" ")})
println()
println("%.4f".format(Calculate_Average(distances)))
println("%.4f".format(Calculate_Variance(distances)))
//步骤6:停止运行
sc.stop()
}
}
输出结果:
560 223 554 438 324 474 274 574 294 397 291 75 440 596 684 423 658 752 118 914
38.8574
34.3549
大作业二:基于Spark的K-mer计数
问题描述:
K-mer是一个长度为K ( K > 0 )的子串,K-mer计数是指整个序列中K-mer出现的频度,本题需要返回出现次数排在前N的子串和出现频率。
假如输入的字符串为ABCDA,K=2,那么子串包含 AB, BC, CD, DA
参数:
K = 2(子串长度)
N = 10(返回排在前N的子串和频率)
输入格式: KM-input.txt
S(长度任意的字符串)
输出结果:文章来源地址https://www.toymoban.com/news/detail-429799.html
- 问题1:共N组输出,每组输出为字符串和出现频率,按照出现次数降序排序,若出现次数相同,按照字符串的字典序降序排序。
- 问题2:输出一个浮点数,为所有字符串出现次数的平均值
题解:
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable._
object Kmer {
val parameter_K: Int = 2 //子串长度
val parameter_N: Int = 10 //返回排在前N的子串和频率
def main(args: Array[String]): Unit = {
//步骤1:启动spark并读入数据
val sparConf = new SparkConf().setMaster("local").setAppName("Kmer")
val sc = new SparkContext(sparConf)
val lines = sc.textFile("file\\KM-input.txt")
val array = lines.collect()
//步骤2:定义枚举子串函数
def Find_SubStrings(str : String, k : Int) = {
val ret : ListBuffer[String] = ListBuffer()
for(i <- 0 until str.length - k + 1){
val substr = str.substring(i,i+k)
ret += substr
}
ret.toList
}
//步骤3:定义字串排名函数
def String_Count(str : String) = {
Find_SubStrings(str,parameter_K).groupBy(str => str)
.map(t_ => (t_._1, t_._2.length)).toList
.sortWith((a,b) => if(a._2 == b._2) {a._1 > b._1} else {a._2 > b._2})
}
//步骤4:定义输出与统计函数
def Show_Infomation(l : List[(String, Int)], n : Int) = {
l.slice(0,n).foreach(x_ => println(x_._1 + "," + x_._2))
var avg: Double = 0
l.foreach(x_ => avg += x_._2)
val ret = avg/l.length
println("%.4f".format(ret))
}
//步骤5:对array的每一行字符串均进行以上操作,并输出结果
array.foreach(str => Show_Infomation(String_Count(str),parameter_N))
//停止运行
sc.stop()
}
}
输出结果:
NM,16
XH,15
PN,15
IX,15
QX,14
FK,14
DL,14
XK,13
SK,13
RZ,13
7.3950
到了这里,关于【BIT云计算大作业】基于Spark的K近邻(KNN)查询以及K-mer计数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!