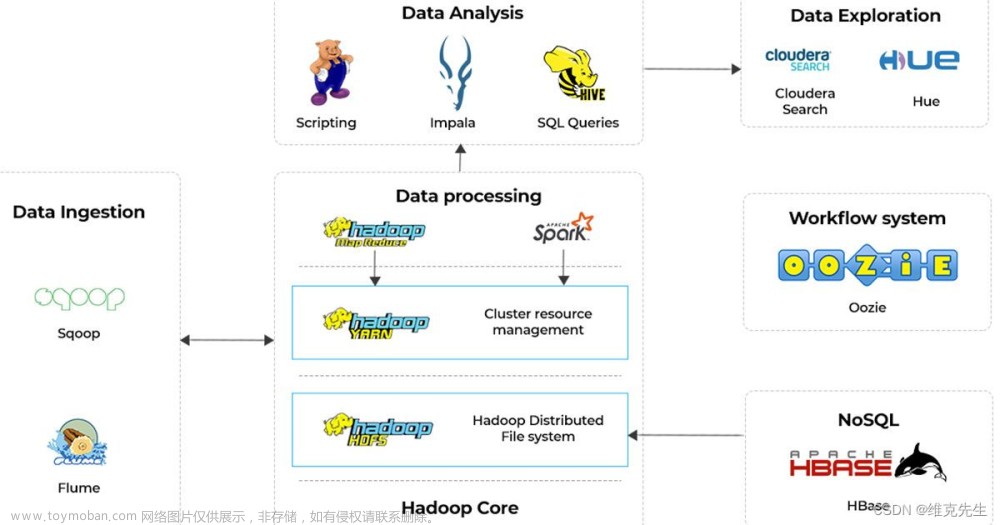
之前做大数据处理,经常遇到各种问题。很多时候是项目作业简单项配置问题,也可能是导入导出参数配置的问题,也可能是公司Hadoop平台的问题。那么如何排查问题,解决问题?这种事情,除了自己要积累一些大数据的知识和技能外,也需要一些获得一些排查问题的技巧、方法。
排查问题:
1、查看公司平台给的报错信息;
2、检查创建作业的配置是否正确;
3、直接去公司的hadoop平台查运行报错的日志
看日志排查问题技巧方法:
查看日志,搜关键字“caused by”,“error”,“connect”,“memory”等,看其上下文日志
不要总想着一点点看,一点点分析。搜关键字。
常见问题与解决方案:
1、hive2hive作业数据量太大,导致内存溢出
解决方案:
1)扩大hive数据作业的MapReduce、Spark这些计算引擎的参数
2)数据做切分后再加工处理
2、ES服务器设置的导入数据内存量太小,导致的内存溢出,hive2es导出数据失败
解决方案:扩大es内存参数。
3、连接关系数据库超时
这种问题有两种情况,我们的关系型数据库(MySQL、Oracle等)与大数据平台关联配置没成功,或者配置的账号、密码错误。还要一种情况,大数据平台关联的数据库有问题。这两种情况属于哪一种,需要看具体日志。
解决方案:正确配置关系型数据库的关联,或者启动那个未成功启动的数据库。
4、数据从hive导出经常报错,但是不是很频繁。网络抖动导致的问题导致的失败。
设置Spark这种计算工具的心跳参数。
心跳参数:spark.executor.heartbeatInterval
5、文章来源:https://www.toymoban.com/news/detail-429984.html
其他问题,后续补充……文章来源地址https://www.toymoban.com/news/detail-429984.html
到了这里,关于Hadoop内hive之间,hive与DB、ES等之间数据交互的问题与解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!