一、HDFS shell命令
首先启动Hadoop,命令如下:
cd /usr/local/hadoop/sbin
start-dfs.sh
在终端输入如下命令,查看hdfs dfs总共支持哪些操作:
cd /usr/local/hadoop/bin
hdfs dfs
上述命令执行后,会显示如下的结果:

如果显示WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable,说明环境变量JAVA_LIBRARY_PATH并未定义,首先进入配置界面
vim ~/.bashrc
按`i``进入编辑模式,在文件中添加一行:
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
添加完成后按esc退出编辑模式,输入:wq保存并退出,然后输入指令使配置立刻生效
source ~/.bashrc
可以看出,hdfs dfs命令的统一格式是类似hdfs dfs -ls这种形式,即在“-”后面跟上具体的操作。
可以查看某个命令的作用,比如,当需要查询put命令的具体用法时,可以采用如下命令:
hdfs dfs -help put
输出的结果如下:

二、HDFS目录操作
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:
cd /usr/local/hadoop/bin
hdfs dfs -mkdir -p /user/hadoop
该命令中表示在HDFS中创建一个/user/hadoop目录,–mkdir是创建目录的操作,-p表示如果是多级目录,则父目录和子目录一起创建,这里/user/hadoop就是一个多级目录,因此必须使用参数-p,否则会出错。/user/hadoop目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:
hdfs dfs –ls .
该命令中,-ls表示列出HDFS某个目录下的所有内容,.表示HDFS中的当前用户目录,也就是/user/hadoop目录,因此,上面的命令和下面的命令是等价的:
hdfs dfs –ls /user/hadoop
如果要列出HDFS上的所有目录,可以使用如下命令:
hdfs dfs –ls
下面,可以使用如下命令创建一个input目录:
hdfs dfs -mkdir input
在创建这个input目录时,采用了相对路径形式,实际上,这个input目录创建成功以后,它在HDFS中的完整路径是/user/hadoop/input。如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
hdfs dfs -mkdir /input
可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的/input目录(不是/user/hadoop/input目录):
hdfs dfs -rm -r /input
上面命令中,-r参数表示如果删除/input目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用-r参数,否则会执行失败。
三、HDFS文件操作
在实际应用中,经常需要从本地文件系统向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。
首先,使用vim编辑器,在本地Linux文件系统的/home/hadoop/目录下创建一个文件myLocalFile.txt
cd /home/hadoop
vim myLocalFile.txt
里面可以随意输入一些单词,比如,输入如下三行:
Hadoop
Spark
XMU DBLAB
然后,可以使用如下命令把本地文件系统的/home/hadoop/myLocalFile.txt上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的/user/hadoop/input/目录下:
cd /usr/local/hadoop/bin
hdfs dfs -put /home/hadoop/myLocalFile.txt input
可以使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:
hdfs dfs -ls input
该命令执行后会显示类似如下的信息:
Found 1 items
-rw-r--r-- 1 hadoop supergroup 23 2021-10-19 13:04 input/myLocalFile.txt
下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
hdfs dfs -cat input/myLocalFile.txt
下面把HDFS中的myLocalFile.txt文件下载到本地文件系统中的/home/hadoop/download/这个目录下,命令如下:
cd /home/hadoop
mkdir download
cd /usr/local/hadoop/bin
hdfs dfs -get input/myLocalFile.txt /home/hadoop/download
可以使用如下命令,到本地文件系统查看下载下来的文件myLocalFile.txt:
cd /home/hadoop/download
ls
cat myLocalFile.txt
最后,了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的/user/hadoop/input/myLocalFile.txt文件,拷贝到HDFS的另外一个目录/input中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:
cd /usr/local/hadoop/bin
hdfs dfs -cp input/myLocalFile.txt /input
四、第三章课后实验
首先在HDFS中上传一些文件以便实验~
cd /home/hadoop
vim test1.txt
(文本中内容为hello world!)
vim test2.txt
(文本中内容为this is test2!)
cd /usr/local/hadoop/bin
hdfs dfs -put /home/hadoop/test1.txt input
hdfs dfs -put /home/hadoop/test2.txt input
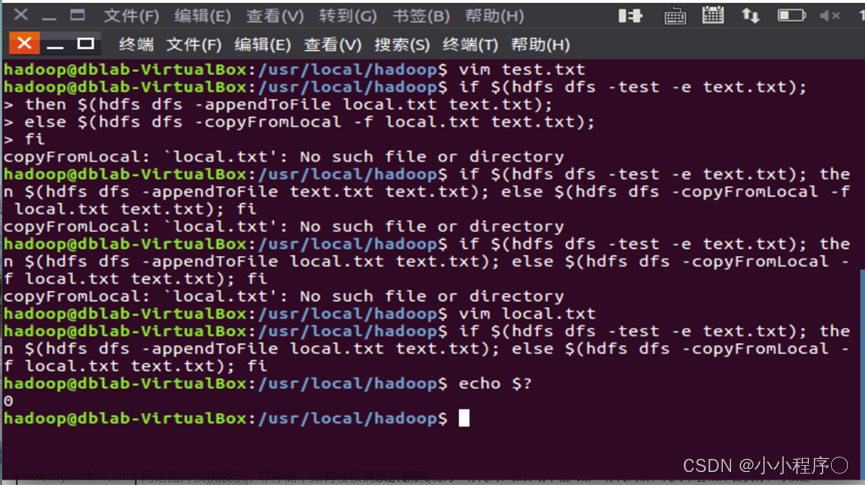
①向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件
$ if $(hdfs dfs -test -e input/test1.txt);#判断test1.txt是否存在
then $(hdfs dfs -appendToFile /home/hadoop/test2.txt input/test1.txt);#若存在则将本地test2.txt中的内容追加到HDFS中test1.txt的末尾
else $(hdfs dfs -copyFromLocal -f /home/hadoop/test2.txt input/test1.txt);#若不存在则用本地test2.txt的内容覆盖至HDFS的test.txt中
fi
此时查看HDFS中test1.txt的内容(hdfs dfs -cat input/test1.txt)输出应该如下:
hello world!
this is test2!
②从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
if $(test -e /home/hadoop/test1.txt);#判断本地是否存在test1.txt
then $(hdfs dfs - copyToLocal input / test1.txt / home / hadoop / test3.txt); #若存在则将HDFS中的test1.txt重命名为test3.txt后下载至本地 / home / hadoop
else $(hdfs dfs - copyToLocal input / test1.txt / home / hadoop / test1 / txt); #否则将test1.txt下载至本地 / home / hadoop
fi
在本地查看下载结果:
cd /home/hadoop
ls
输出如下:

查看test3.txt的内容:
cat test3.txt
输出如下:

③将HDFS中指定文件的内容输出到终端中
cd /usr/local/hadoop/bin
hdfs dfs -cat input/test1.txt
④显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
hdfs dfs -ls -h input/test1.txt
输出如下:
-rw-r--r-- 1 hadoop supergroup 28 2021-10-22 21:46 input/test1.txt
⑤给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
hdfs dfs -ls -R -h /user/hadoop
输出如下:
drwxr-xr-x - hadoop supergroup 0 2021-10-22 21:44 /user/hadoop/input
-rw-r--r-- 1 hadoop supergroup 23 2021-10-19 13:04 /user/hadoop/input/myLocalFile.txt
-rw-r--r-- 1 hadoop supergroup 28 2021-10-22 21:46 /user/hadoop/input/test1.txt
-rw-r--r-- 1 hadoop supergroup 15 2021-10-22 21:44 /user/hadoop/input/test2.txt
⑥提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
if $(hdfs dfs -test -d /user/hadoop/test);#查看是否存在test目录
then $(hdfs dfs - touchz / user / hadoop / test / test1.txt); #若存在,则在test目录下创建一个test1.txt
else $(hdfs dfs - mkdir - p / user / hadoop / test && hdfs dfs - touchz / user / hadoop / test / test1.txt); #若不存在,则先创建该目录,再到该目录下创建test1.txt
fi
查看结果:
hdfs dfs -ls -R -h /user/hadoop
输出如下:
drwxr-xr-x - hadoop supergroup 0 2021-10-22 21:44 /user/hadoop/input
-rw-r--r-- 1 hadoop supergroup 23 2021-10-19 13:04 /user/hadoop/input/myLocalFile.txt
-rw-r--r-- 1 hadoop supergroup 28 2021-10-22 21:46 /user/hadoop/input/test1.txt
-rw-r--r-- 1 hadoop supergroup 15 2021-10-22 21:44 /user/hadoop/input/test2.txt
drwxr-xr-x - hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test
-rw-r--r-- 1 hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test/test1.txt
⑦提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
if $(hdfs dfs -test -e /user/hadoop/test2);#查看是否存在test2目录
then $(); #若存在则什么都不做
else $(hdfs dfs - mkdir - p / user / hadoop / test2); #否则创建该目录
fi
查看结果:
hdfs dfs -ls -R -h /user/hadoop
输出如下:
drwxr-xr-x - hadoop supergroup 0 2021-10-22 21:44 /user/hadoop/input
-rw-r--r-- 1 hadoop supergroup 23 2021-10-19 13:04 /user/hadoop/input/myLocalFile.txt
-rw-r--r-- 1 hadoop supergroup 28 2021-10-22 21:46 /user/hadoop/input/test1.txt
-rw-r--r-- 1 hadoop supergroup 15 2021-10-22 21:44 /user/hadoop/input/test2.txt
drwxr-xr-x - hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test
-rw-r--r-- 1 hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test/test1.txt
drwxr-xr-x - hadoop supergroup 0 2021-10-22 22:06 /user/hadoop/test2
if $(hdfs dfs -test -e /user/hadoop/test2);#检查是否存在test2目录
then $(hdfs dfs -rm -r /user/hadoop/test2);#若存在则删除该目录
fi
查看结果:
hdfs dfs -ls -R -h /user/hadoop
输出如下:
hdfs dfs -ls -R -h /user/hadoop
drwxr-xr-x - hadoop supergroup 0 2021-10-22 21:44 /user/hadoop/input
-rw-r--r-- 1 hadoop supergroup 23 2021-10-19 13:04 /user/hadoop/input/myLocalFile.txt
-rw-r--r-- 1 hadoop supergroup 28 2021-10-22 21:46 /user/hadoop/input/test1.txt
-rw-r--r-- 1 hadoop supergroup 15 2021-10-22 21:44 /user/hadoop/input/test2.txt
drwxr-xr-x - hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test
-rw-r--r-- 1 hadoop supergroup 0 2021-10-22 22:03 /user/hadoop/test/test1.txt
⑧向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾
查看test1.txt的内容:
hdfs dfs -cat input/test1.txt
输出如下:
hello world!
this is test2!
查看本地的test3.txt的内容:
cat /home/hadoop/test3.txt
输出如下:
hello world!
this is test2!
将test3.txt的内容追加到HDFS中test1.txt的末尾:
hdfs dfs -appendToFile /home/hadoop/test3.txt input/test1.txt
查看结果:
hdfs dfs -cat input/test1.txt
输出如下:
hello world!
this is test2!
hello world!
this is test2!
⑨删除HDFS中指定的文件、目录
hdfs dfs -mkdir input/test2
hdfs dfs -touchz input/test2/test.txt
hdfs dfs -rm input/test2/test.txt
hdfs dfs -rm -r input/test2
五、应用实例代码编写
首先在Ubuntu系统中安装Eclipse(安装教程传送门:Ubuntu20.04 LTS 安装Eclipse2021-03)
①下载Hadoop相关的jar包(下载地址)
首先在/opt下创建目录/jar以保存下载的jar包
cd /opt
sudo mkdir jar
接着开始下载jar包
sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-common/2.10.1/hadoop-common-2.10.1.jar
sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-client/2.10.1/hadoop-client-2.10.1.jar
sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-hdfs/2.10.1/hadoop-hdfs-2.10.1.jar
sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-mapreduce-client-core/2.10.1/hadoop-mapreduce-client-core-2.10.1.jar
②在Eclipse中导入jar包



 文章来源:https://www.toymoban.com/news/detail-430121.html
文章来源:https://www.toymoban.com/news/detail-430121.html
③编写应用实例程序文章来源地址https://www.toymoban.com/news/detail-430121.html
import java.io.*;
import java.net.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
class MyPathFilter implements PathFilter
{
String reg = null;
MyPathFilter(String reg)
{
this.reg = reg;
}
public boolean accept(Path path)
{
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
public class Merge
{
Path inputPath = null;
Path outputPath = null;
public Merge(String input, String output)
{
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
FileStatus[] sourceStatus = fsSource.listStatus(inputPath, new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
for (FileStatus sta : sourceStatus)
{
System.out.print("Path: " + sta.getPath() + ", File Size: " + sta.getLen()
+ ", Authorized: " + sta.getPermission() + ", Content: ");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
PrintStream ps = new PrintStream(System.out);
while ((read = fsdis.read(data)) > 0)
{
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
ps.close();
}
fsdos.close();
}
public static void main(String[] args) throws IOException
{
String input = "hdfs://localhost:9000/user/hadoop/input/";
String output = "hdfs://localhost:9000/user/hadoop/input/merge.txt";
Merge merge = new Merge(input, output);
merge.doMerge();
}
}
到了这里,关于熟悉常用的HDFS操作(大数据技术原理与应用-第三章实验)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!