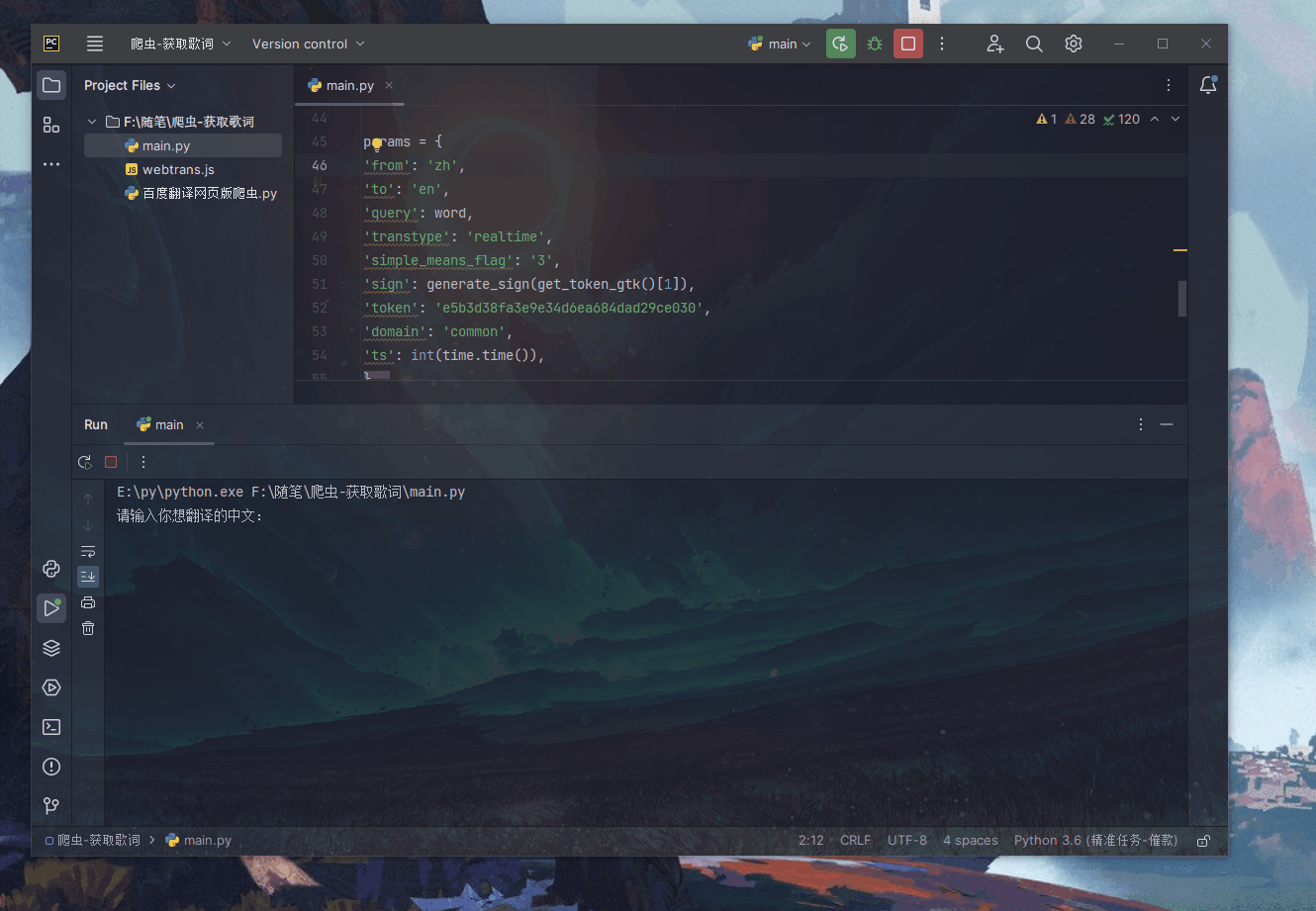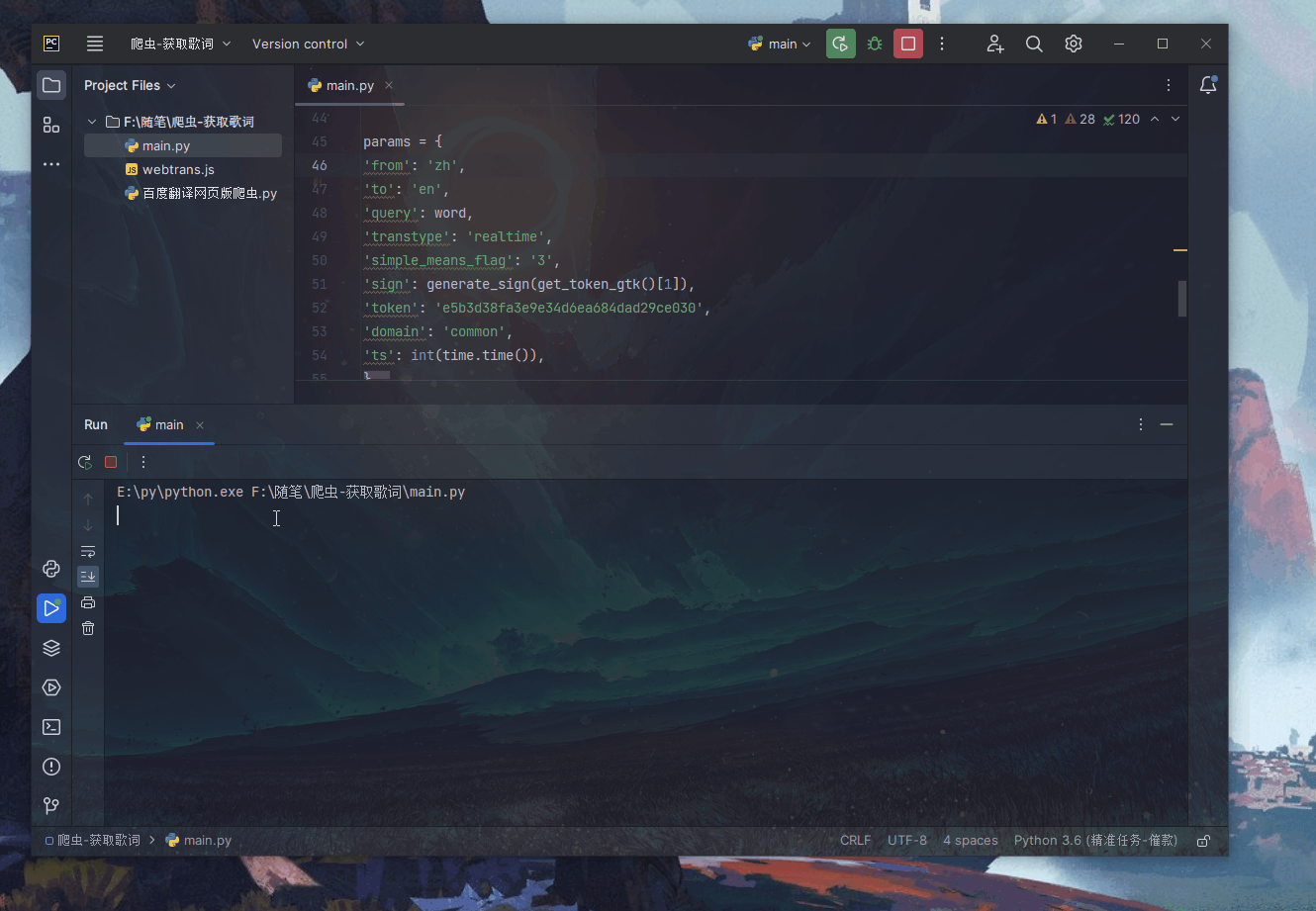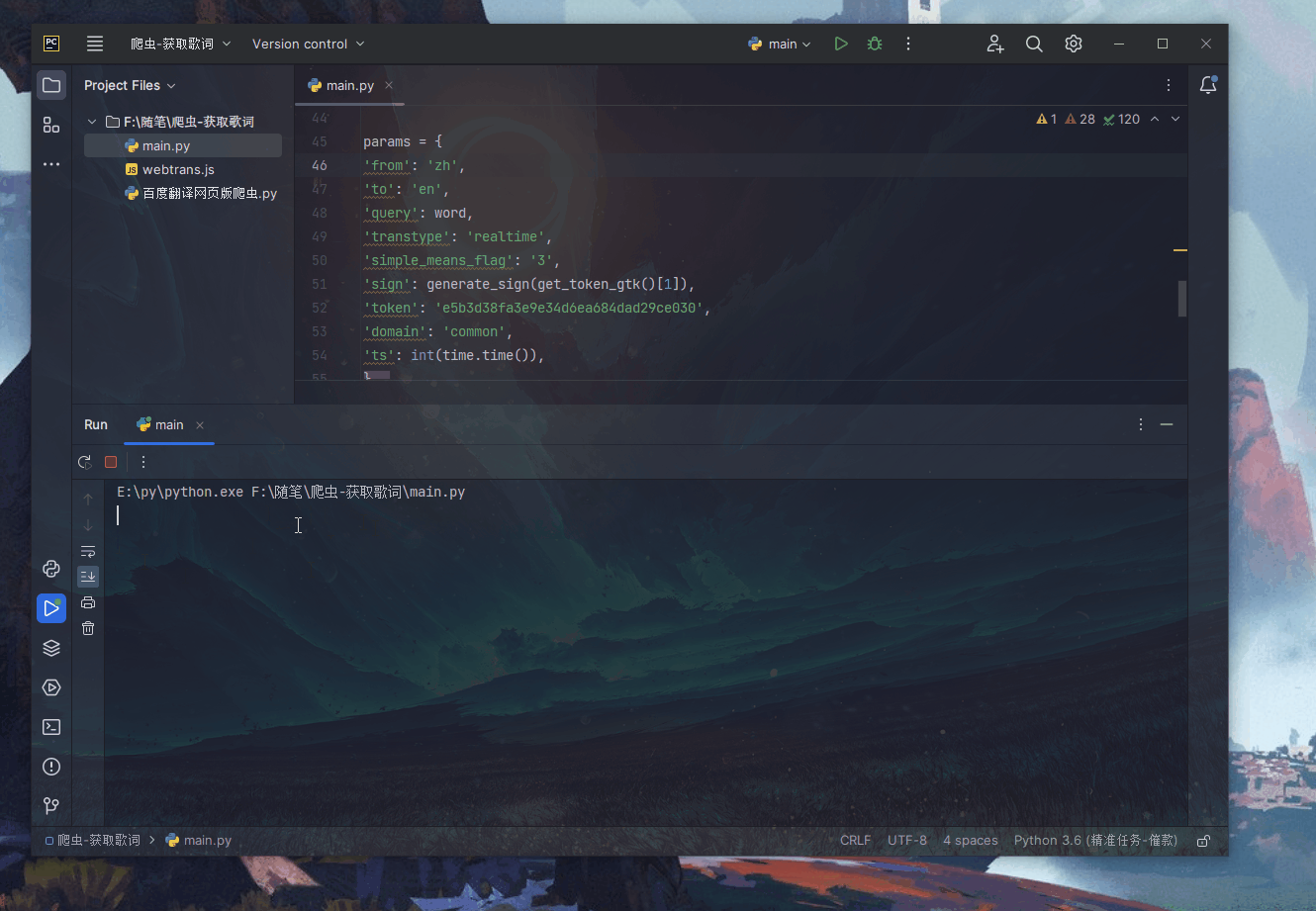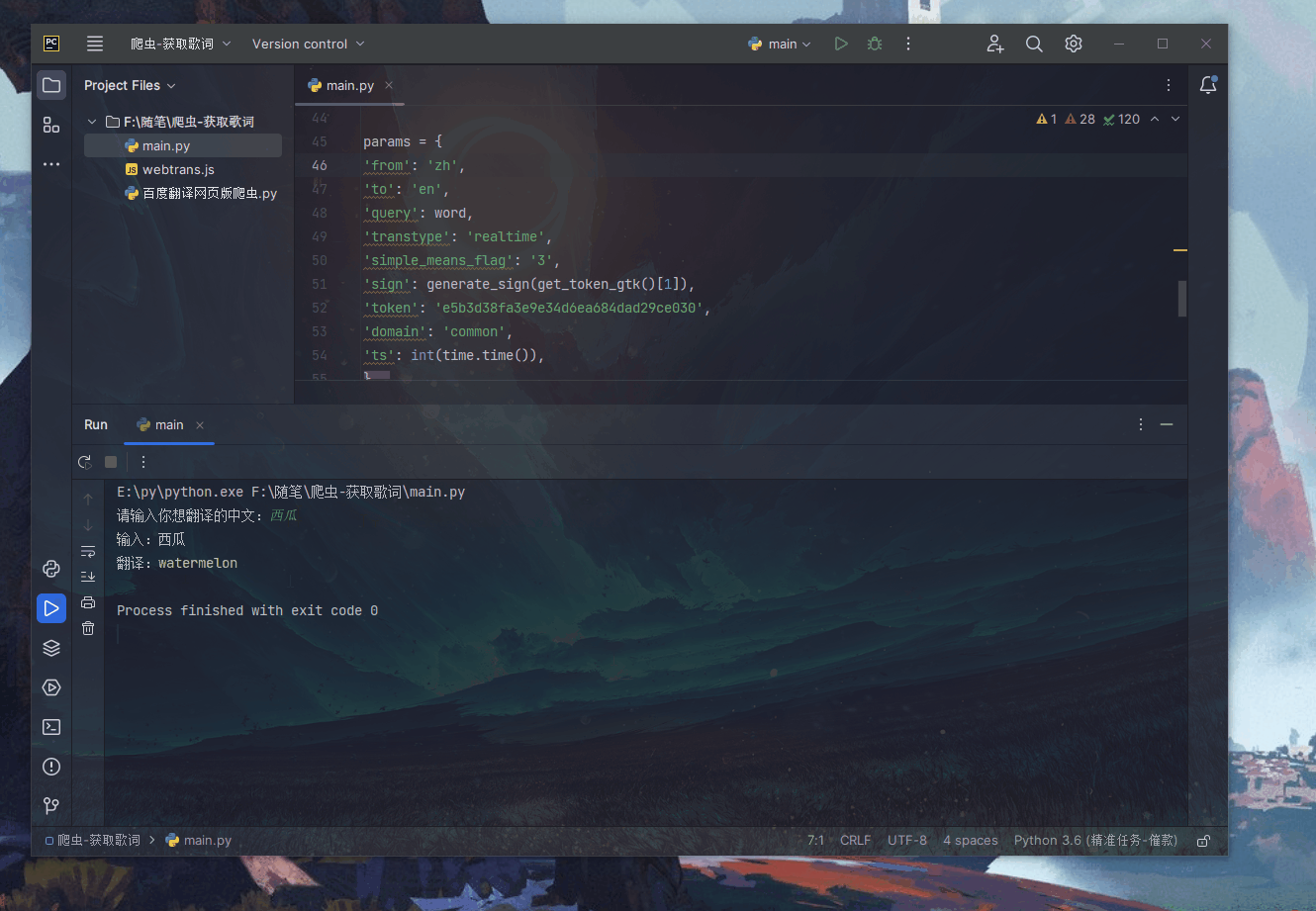
jS动态生成,由于呈现在网页上的内容是由JS生成而来,我们能够在浏览器上看得到,但是在HTML源码中却发现不了
一、注意:代码加入了常规的防爬技术
如果不加,如果网站有防爬技术,比如频繁访问,后面你会发现什么数据都取不到
1.1 模拟请求头: 这里入进入一步加强,随机,主要是User-Agent这个参数
User-Agent获取地方:


1.2 伪造请求cookie:当然也这里可以做随机的

网页获取位置:

1.3 使用代理IP(我这里没有做这个,这个网站没必要,也没深入研究)
使用代理IP解决反爬。(免费代理不靠谱,最好使用付费的。有按次数收费的,有按时长收费的,根据自身情况选择)
是什么意思呢,就是每次发送请求,让你像从不同的地域发过来的一样,第一次我的ip地址是河北,第二次是广东,第三次是美国。。。像这样:
def get_ip_pool(cnt):
"""获取代理ip的函数"""
url_api = '获取代理IP的API地址'
try:
r = requests.get(url_api)
res_text = r.text
res_status = r.status_code
print('获取代理ip状态码:', res_status)
print('返回内容是:', res_text)
res_json = json.loads(res_text)
ip_pool = random.choice(res_json['RESULT'])
ip = ip_pool['ip']
port = ip_pool['port']
ret = str(ip) + ':' + str(port)
print('获取代理ip成功 -> ', ret)
return ret
except Exception as e:
print('get_ip_pool except:', str(e))
proxies = get_ip_pool() # 调用获取代理ip的函数
requests.get(url=url, headers=headers, proxies={'HTTPS': proxies}) # 发送请求
1.4 随机等待间隔访问
尽量不要用sleep(1)、sleep(3)这种整数时间的等待,一看就是机器。。
还是那句话,让爬虫程序表现地更像一个人!
time.sleep(random.uniform(0.5, 3)) # 随机等待0.5-3秒
上面4点防爬技术,不一定要全部加入,只看被爬网站是否有防爬技术,多数用到1、2点就搞定
一、例子:以抓取双色球数据为例子
官网:阳光开奖

经过排查,是通过接口获取数据再由JS来生成这部分网页元素

通过检查元素是有数据的(JS来生成这部分网页元素)

一、不过滤什么元素字段,把所有元素导出表格

# 抓取双色球历史数据
# 编码:utf-8
import requests
import json
import random
import time
import pandas as pd
data_list = []
num_pages = 1 #抓取多少页数据
# 创建一个DataFrame,用于保存到excel中
for page in range(1, num_pages+1):
url = 'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&issueCount=&issueStart=&issueEnd=&dayStart=&dayEnd=&pageSize=30&week=&systemType=PC&pageNo='
url2 = url + str(page)
# request header,其中最关键的一项,User-Agent,可以写个agent_list,每次请求,随机选择一个agent,像这样:
agent_list = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10"
]
headers = {
'User-Agent': random.choice(agent_list), # 在调用的时候,随机选取一个就可以了
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
'Referer': 'http://www.cwl.gov.cn/ygkj/wqkjgg/ssq/',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cookie': 'HMF_CI=xxxxxxxxxxxxxxxxxxxxxxxxx' # 加入自己的Cookie
}
# 使用代理IP
# proxies = {
# 'http': 'http://10.10.1.10:3128',
# 'https': 'http://10.10.1.10:1080',
# }
#response = requests.get(url2, headers=headers, proxies=proxies).text
wbdata = requests.get(url2, headers=headers).text
time.sleep(random.uniform(0.5, 3)) # 随机等待0.5-3秒
data = json.loads(wbdata) # json.loads() 方法将 JSON 数组转换为 Python 列表
news = data['result']
for n in news:
df = pd.DataFrame(n)
df.to_excel("双色球历史数据.xlsx")
print('完成')
导出excel

二、只要需要的元素字段,这里比如只需要期号、红球、蓝球("code", "red", "blue")三个数据

# 抓取双色球历史数据
# 编码:utf-8
import requests
import json
import random
import time
import pandas as pd
data_list = []
# 抓取多少页数据
pageNo = 1
# 页数
pageSize = 30
# 只需要期号、红球、蓝球("code", "red", "blue")三个数据
columns = ["code", "red", "blue"]
df = pd.DataFrame(columns=columns)
for page in range(1, pageNo+1):
url = 'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&issueCount=&issueStart=&issueEnd=&dayStart=&dayEnd=&pageSize=' + \
str(pageSize) + '&week=&systemType=PC&pageNo='
url2 = url + str(page)
# request header,其中最关键的一项,User-Agent,可以写个agent_list,每次请求,随机选择一个agent,像这样:
agent_list = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10"
]
headers = {
'User-Agent': random.choice(agent_list), # 在调用的时候,随机选取一个就可以了
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
'Referer': 'http://www.cwl.gov.cn/ygkj/wqkjgg/ssq/',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cookie': 'HMF_CI=xxxxxxxxxx' # 加入自己的Cookie
}
# 使用代理IP
wbdata = requests.get(url2, headers=headers).text
# 随机等待间隔访问 随机等待0.5-3秒
time.sleep(random.uniform(0.5, 3))
data = json.loads(wbdata)
news = data['result']
# 过滤不要的元素数据
new_json = json.dumps(
[{key: x[key] for key in columns} for x in news]
)
# 再将JSON 数组转换为 Python 列表list
new_response = json.loads(new_json)
for n, arr in enumerate(new_response):
index = n+(pageNo-1)*pageSize # 插入新数据时要添加索引
df.loc[index] = arr # 一次插入一行数据
df.to_excel("双色球历史数据2.xlsx")
print('完成')
上面都是获取一个网页的数据,如果源数据网页是有分页的,那如何抓取
三、抓取多个网页数据
# 抓取双色球历史数据
# 编码:utf-8
import requests
import json
import random
import time
import pandas as pd
data_list = []
# 抓取多少页数据
pageNo = 2
# 页数
pageSize = 30
# 只需要期号、红球、蓝球("code", "red", "blue")三个数据
columns = ["code", "red", "blue"]
df = pd.DataFrame(columns=columns)
for page in range(1, pageNo+1):
url = 'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&issueCount=&issueStart=&issueEnd=&dayStart=&dayEnd=&pageSize=' + \
str(pageSize) + '&week=&systemType=PC&pageNo='
url2 = url + str(page)
# request header,其中最关键的一项,User-Agent,可以写个agent_list,每次请求,随机选择一个agent,像这样:
agent_list = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10"
]
headers = {
'User-Agent': random.choice(agent_list), # 在调用的时候,随机选取一个就可以了
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
'Referer': 'http://www.cwl.gov.cn/ygkj/wqkjgg/ssq/',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cookie': 'xxxxxxxxx' # 加入自己的Cookie
}
# 使用代理IP
wbdata = requests.get(url2, headers=headers).text
# 随机等待间隔访问 随机等待0.5-3秒
time.sleep(random.uniform(0.5, 3))
data = json.loads(wbdata)
news = data['result']
# 过滤不要的元素数据
new_json = json.dumps(
[{key: x[key] for key in columns} for x in news]
)
# 再将JSON 数组转换为 Python 列表list
new_response = json.loads(new_json)
# 把抓取每一个网页的数据加入data_list数组中(python中list) extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) 不能用append()
data_list.extend(new_response)
print('------------1.抓取到第' + str(page) + '页数据---------------')
# print(data_list)
for n, arr in enumerate(data_list):
df.loc[n+1] = arr # 一次插入一行数据
df.to_excel("双色球历史数据.xlsx")
df.head()
print('数据导出导出完成:双色球历史数据.xlsx')
,如果这个编程语言完全不会,用chatgpt来写代码还是有点困难的,对于编程人员来说chatpgt就很好用
参考:
python怎样抓取js生成的页面_ITPUB博客
python抓取数据,pandas 处理并存储为excel_python pandas生成excel_格物致理,的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-430222.html
【道高一尺,魔高一丈】Python爬虫之如何应对网站反爬虫策略_python应对反爬虫策略_Python程序员小泉的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-430222.html
到了这里,关于小白用chatgpt编写python 爬虫程序代码 抓取网页数据(js动态生成网页元素)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!