| 框架 | 优点 | 缺点 |
|---|---|---|
| TensorFlow | - 由Google开发和维护,社区庞大,学习资源丰富 - 具备优秀的性能表现,支持大规模分布式计算 - 支持多种编程语言接口,易于使用 - 提供了可视化工具TensorBoard,可用于调试和可视化模型 |
- 底层架构复杂,操作较为繁琐 - 不支持动态图,调试和修改模型较为困难 - 对于一些高级算法实现,需要自己手动编写代码 |
| PyTorch | - 由Facebook开发和维护,在学术界和工业界都有广泛应用 - 支持动态图和静态图,提供了灵活的模型构建方法 - 简单易用,具有良好的API设计 - 支持与NumPy的交互,方便数据处理和模型构建 |
- 面向Python,不支持其他编程语言 - 对于大规模分布式计算支持较弱 - 在性能方面与TensorFlow相比,还有一定差距 |
| Keras | - 使用Python编写,简单易学 - 支持多种深度学习模型的快速构建和调试 - 可以灵活切换使用TensorFlow、Theano、CNTK等后端实现 - 提供了丰富的预训练模型,可供使用 |
- 如果需要进行深度定制,可能需要编写底层API的代码 - 对于一些高级算法的实现可能略显不足 |
| MXNet | - 由Amazon开发和维护,具有良好的性能表现 - 支持多种编程语言接口,如Python、C++、Julia、JavaScript等 - 进行分布式计算时,可以在不同的硬件和操作系统之间进行无缝切换 - 代码规范,易于维护和修改 |
- API设计不够友好,使用起来不如其他框架直观 - 细节较多,对于初学者不够友好 - 开发社区相较于其他框架相对较小 |
| Caffe | - 底层C++实现,性能表现优秀 - 针对图像和语音处理等领域,具有丰富的模型预训练和数据集,方便使用和构建模型 - API设计比较简单易懂,适合初学者使用 |
- 需要手动编写一些代码,无法自动化完成深度定制 - 不如TensorFlow等框架灵活,无法支持较为复杂的计算图和分布式计算 - 不支持动态图,对于一些高级算法的实现可能略显不足 |
全连接神经网络
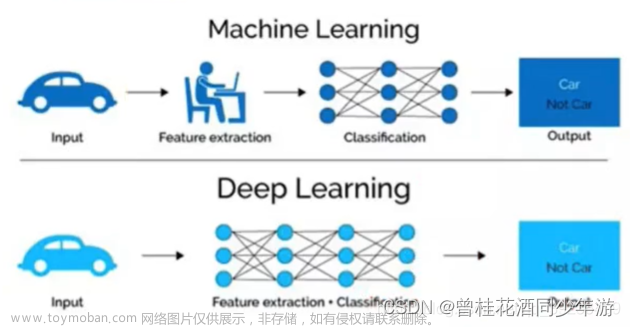
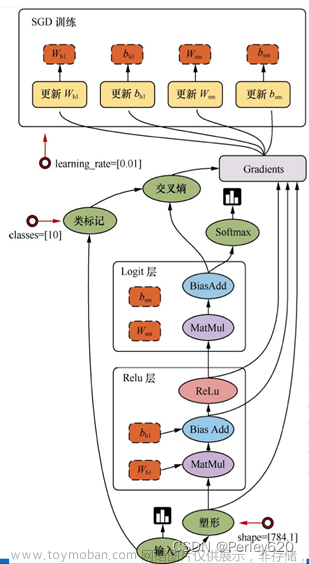
全连接神经网络(Fully Connected Neural Network)是一种深度学习模型,也称为多层感知器(Multi-Layer Perceptron)。它由多个神经元或节点组成,每个节点与下一层的每个节点都有连接,这些连接形成了一个完全连接的图形。全连接神经网络是一种前馈神经网络,神经元之间的信息只能向前传递。在训练期间,通过梯度下降等算法来优化权重和偏差参数,以使模型能够准确地预测输出结果。全连接神经网络广泛应用于图像和语音识别、自然语言处理等领域。
激活函数
激活函数(Activation Function)是神经网络中的一种函数,它的作用是对输入信号进行非线性映射,将其转换为更有意义的输出信号。
神经网络需要激活函数的原因在于,如果神经网络只是简单的线性变换,则无法处理非线性问题,因为多个线性层级的组合依然是线性的,无法构造出更复杂的函数。而采用激活函数可以使神经网络具有非线性特性,进而可以处理更加复杂的问题。
激活函数可以有效地增强神经网络的表达能力,使其能够更好地学习数据中的特征,从而提高模型的分类和预测能力。常见的激活函数包括Sigmoid、ReLU、Tanh等,不同的激活函数适用于不同的场景和任务,所以选择合适的激活函数对于神经网络的性能和效果非常重要。
卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,用于处理具有网格状结构的数据,特别是图像和视频数据。CNN由多个卷积层和池化层组成,最后接上全连接层进行分类。
卷积层是CNN的核心,它采用卷积核对输入数据进行卷积操作,提取出数据的局部特征。卷积层的好处是它能有效地减少模型的参数数量,提高模型的泛化能力。池化层则用于降低特征图的维度,进一步减小模型的复杂度,防止过拟合。
CNN的优点在于,它能够自动提取图像的特征,不需要手动去设计特征提取器。同时,CNN还可以通过多个卷积层和池化层进行层层提升特征的提取和抽象能力,进而实现更高质量的图像分类和识别。
CNN已经被广泛应用于图像识别、图像分割、目标检测等领域,成为深度学习领域的重要技术之一。
什么是泛化?
泛化能力(Generalization Ability)是指机器学习模型在面对新的、未见过的数据时,能够正确地预测输出结果的能力。泛化能力是评估机器学习模型的重要指标之一,好的模型应当具有较强的泛化能力。
在机器学习中,我们通常会将数据集分成训练集和测试集,模型在训练集上学习到一定的规律和知识后,需要在测试集上进行测试,以评估模型的泛化能力。如果模型只是简单地“背诵”了训练集中的样本,而无法适应新的数据,那么它的泛化能力就会很差,出现过拟合现象。相反,如果模型能够从训练集中学到一般性的规律,而不是简单地记住训练集的个别样本,那么它就能够具有很好的泛化能力,能够处理新的、未见过的数据。
在实际应用中,我们通常会通过调整模型结构、增加训练数据、引入正则化等方式来提高模型的泛化能力。
递归神经网络
递归神经网络(Recurrent Neural Network,RNN)是一种深度学习模型,主要用于处理序列数据的任务,如语音识别、自然语言处理等。与传统的前馈神经网络不同,RNN具有循环连接,可以处理任意长度的输入序列。
RNN的循环连接允许网络保存历史信息,并将它们传递到后续时间步中进行处理,这使得RNN可以学习到序列数据的长期依赖关系。在每个时间步中,RNN会接收到当前时间步的输入,根据上一个时间步的状态和当前输入计算出当前时间步的状态,然后将状态传递到下一个时间步中。
RNN的一个主要缺点是,在处理长序列数据时,容易出现梯度消失或爆炸的问题,导致无法进行有效的学习。为了解决这个问题,一些改进的RNN结构被提出,如长短时记忆网络(LSTM)和门控循环单元(GRU),它们通过引入门机制,有效地控制了信息的传递和过滤,从而解决了梯度消失或爆炸的问题。
递归神经网络已经被广泛应用于自然语言处理领域、信号处理领域等,是深度学习领域的重要技术之一。
长短时记忆网络
AI: 长短时记忆网络(LSTM)是一种深度学习模型,它可以有效地捕捉和处理时间序列数据。LSTM具有以下优点:文章来源:https://www.toymoban.com/news/detail-430648.html
- LSTM具有记忆能力,能够更好地捕捉长序列的信息。
- LSTM可以处理时间序列数据中的数据丢失和噪声情况。
- LSTM在训练过程中可以避免梯度消失或梯度爆炸的问题。
LSTM的缺点包括:文章来源地址https://www.toymoban.com/news/detail-430648.html
- LSTM需要比其他模型更多的计算资源。
- LSTM在处理某些时间序列数据时可能会出现过拟合问题。
- LSTM对输入序列的长度有限制,超过一定的长度可能导致性能下降。
到了这里,关于常见的深度学习框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!