python爬虫框架selenium安装和使用教程
–
Selenium是一个常用的Python爬虫框架,可以模拟浏览器行为,实现一些自动化的操作。本教程将介绍Selenium的基础知识、使用方法,包括导入包、安装、示例、数据保存等方面。
导入包
在开始之前,我们需要先导入Selenium相关的包。这里我们用Python3作为演示,所以需要安装对应版本的Selenium。可以使用pip进行安装:
pip install selenium
然后在代码中导入相关的包:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
下载浏览器驱动
由于Selenium需要驱动一个真正的浏览器来实现自动化操作,所以我们需要下载对应的浏览器驱动。这里我们以Chrome浏览器为例,下载Chrome浏览器驱动的地址是:http://chromedriver.chromium.org/downloads。
下载完成后,将驱动程序所在的路径添加到环境变量中,以便Selenium能够找到驱动程序。
打开网页
下面是一个简单的示例,演示如何使用Selenium打开一个网页:
# 创建一个Chrome浏览器对象
browser = webdriver.Chrome()
# 打开一个网页
browser.get("https://www.baidu.com")
# 关闭浏览器
browser.quit()
这里首先创建了一个Chrome浏览器对象,然后使用get()方法打开了百度的首页。最后通过quit()方法关闭了浏览器。
模拟用户操作
Selenium最常用的功能之一就是模拟用户操作,比如点击按钮、输入内容等。下面是一个示例,演示如何在百度的搜索框中输入关键词,并点击搜索按钮:
# 创建一个Chrome浏览器对象
browser = webdriver.Chrome()
# 打开一个网页
browser.get("https://www.baidu.com")
# 找到搜索框并输入关键词
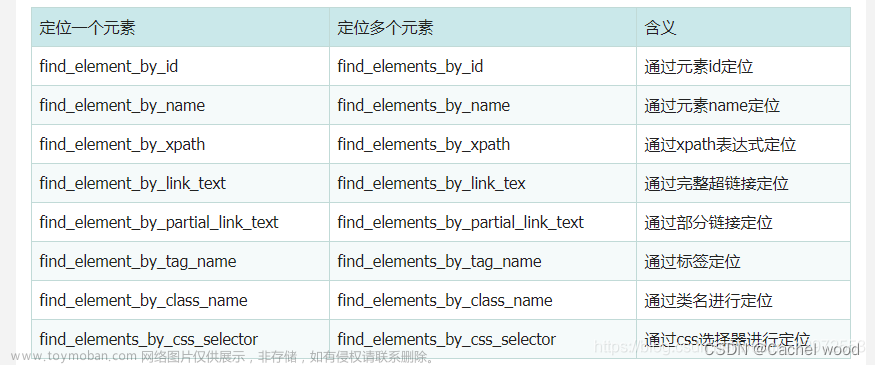
input_box = browser.find_element_by_id("kw")
input_box.send_keys("Python")
# 点击搜索按钮
search_button = browser.find_element_by_id("su")
search_button.click()
# 关闭浏览器
browser.quit()
这里首先找到了搜索框和搜索按钮的元素,然后通过send_keys()方法在搜索框中输入了关键词,并通过click()方法点击了搜索按钮。
数据保存
爬虫的目的是获取数据,因此我们需要将爬取到的数据进行保存。在本教程中,我们将演示如何将爬取到的数据保存为csv文件。
在示例代码中,我们使用了pandas库来进行数据处理和保存。pandas是一个强大的数据处理工具,可以方便地对数据进行清洗、转换和分析。我们可以使用以下代码将数据保存为csv文件:
import pandas as pd
df = pd.DataFrame(data, columns=['title', 'author', 'date', 'content'])
df.to_csv('output.csv', index=False, encoding='utf-8')
上述代码中,我们将数据保存为名为“output.csv”的文件,其中data是一个包含我们爬取到的所有数据的列表,列表中的每个元素都是一个字典,包含文章的标题、作者、日期和内容。我们使用pandas库将这个列表转换为一个DataFrame对象,并将其保存为csv文件。
完整代码如下:文章来源:https://www.toymoban.com/news/detail-430701.html
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
driver = webdriver.Chrome()
driver.get('https://www.example.com')
# 在此处填写爬虫代码
data = []
# 将爬取到的数据添加到data列表中
df = pd.DataFrame(data, columns=['title', 'author', 'date', 'content'])
df.to_csv('output.csv', index=False, encoding='utf-8')
driver.quit()
总结
在本教程中,我们介绍了如何使用selenium进行简单的爬虫,并将爬取到的数据保存为csv文件。使用selenium可以帮助我们解决一些常见的爬虫问题,例如网站需要登录、网站需要执行JavaScript等。当然,selenium并不是万能的,对于一些需要解析复杂HTML结构的网站,我们还需要使用其他的爬虫工具和技术。希望本教程能对初学者有所帮助,也欢迎大家多多探索和实践。文章来源地址https://www.toymoban.com/news/detail-430701.html
到了这里,关于python爬虫框架selenium安装和使用教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!