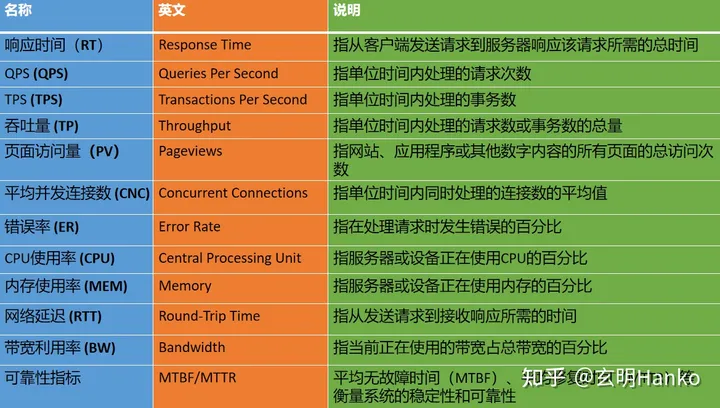
在前面的文章中,我们介绍了“数据服务”对于“数据中台”的重要性,并讲解了数据服务解决的问题及其核心功能,在这个系列的最终篇我们展开聊聊数据服务的四大关键技术,然后总结一下数据服务架构的三大关键点,希望对大家有所帮助。
为了使数据中台具备快速响应前端业务需求的能力,主流的数据中台均采用了云原生技术来构建数据服务层,实现数据服务的快速开发、有序落地。

云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论,因此在这里先不展开云原生的具体架构。我们重点关注在数据中台领域,基于云原生的关键技术应用。

在数据中台领域,应用云原生的核心优势在于每个服务至少有两个副本,实现了服务的高可用;同时,根据访问量大小,服务的副本数量可以动态调整,可以实现对客户端透明的弹性伸缩;服务之间基于容器实现了资源隔离,避免了服务之间的相互影响;这些特性非常适用于提供高并发、低延迟,在线数据查询的数据服务。
麦聪软件,全球领先的DaaS厂商,轻量级数据中台领导者。目前已服务超过400家中大型企业客户,世界500强集团中已有30多家选用。核心产品麦聪DaaS平台,主推数据统一管理和服务两大模块,主要功能包括元数据管理、数据开发、数据治理、数据服务、数据市场等,客户涉及汽车、重型装备、制造、军工、政府、金融等行业。

以下是具体技术应用场景。
第一,配置即开发。
平台用户分为两类角色:数据服务生产方、数据服务调用方。数据服务生产方只需要配置,实现“配置即开发”。配置内容包括:
数据源
数据加速到何处
接口形态,访问方式
测试环境,访问隔离的测试数据
当配置完毕后,数据服务平台便会根据配置清单,完成接口的自动化生产和部署。生产和部署完毕后,调用方在平台申请服务权限调用。通过自动化生产,达到配置即开发的目的,从而极大的提升效率。

第二,多模式服务形态。

数据服务有多种服务形态,包括:
KV API:简单点查,可以支撑百万QPS、毫秒延迟。这类API是通过模板自动化创建,支持单查、批量查询等接口,返回的结果是 Protobuf (PB) 结构体,从而将结果自动做了ORM,对于主调方更加友好。典型场景包括:根据IP查询GEO位置信息、根据用户ID查询用户标签画像信息等。
SQL API:复杂灵活查询,底层基于OLAP/OLTP 存储引擎。通过Fluent API接口,用户可自由组合搭配一种或若干种嵌套查询条件,可查询若干简单字段或者聚合字段,可分页或者全量取回数据。典型场景包括:用户圈选(组合若干用户标签筛选出一批用户)。
Union API:融合API,可自由组合多个原子API,组合方式包括串行和并行方式。调用方不再需要调用多个原子API,而是调用融合API,通过服务端代理访问多个子查询,可以极大降低访问延迟。
第三,高效数据加速。

企业的数据资产,通常是存在于低速的存储引擎中,无法支撑线上业务高访问流量。因此需要以系统化的方式进行数据加速。目前有两种加速方式:
全量数据加速。从多个数据源摄入原始数据(如Kafka,MySQL、线上访问日志等),进行加工建模后,得到数据资产。数据资产经由独立的数据同步服务,同步至其他更高速的存储引擎,如redis、hbase、druid等。数据同步支持一次性或者周期性(小时、天、周等)将数据从Hive同步至其他存储中,数据同步本身是基于分布式的调度系统,内核是基于datax 进行数据同步。大数据服务化平台单日同步的数据量达到1200亿条,数据size达到20TB。
多级缓存(部分数据加速)。大数据服务化平台会使用Redis、Hbase、Druid、Clickhouse等方式存储所有数据,但是部分存储如Hbase速度可能较慢,针对热点数据需要使用额外的热点缓存来Cache数据。热点缓存是多级缓存,针对每个API接口,用户可自由搭配组合多级缓存、灵活设置缓存策略。此外,针对数据较大的API,还可配置数据压缩,通过多种压缩方式(如 ZSTD, SNAPPY, GZIP 等),可将数据量显著减少(部分API 甚至能减少90%的数据存储量)。
第四,资源隔离。

资源隔离是可用性保障的常见手段之一,通过隔离将意外故障等情况的影响面降低。不管是微服务,还是存储,需要按照业务+优先级(高、中、低)粒度隔离部署,独立保障,业务之间互不影响、业务内不同级别也互不影响。同一业务线内可能有多个不同数据服务,通过混合部署,提高资源使用率。
综上,我们可以梳理数据服务的核心框架。

图中,每个已经发布上线的API接口都对应了一个Kubernates的Service,每个 Service 有多个副本的Pod组成,每个API接口访问后端存储引擎的代码运行在Pod对应的容器中,随着 API 接口调用量的变化,Pod可以动态的创建和销毁。
Envoy是服务网关,可以将Http请求负载均衡到Service的多个Pod上。Ingress Controller可以查看Kubernates中每个Service的Pod变化,动态地将Pod IP写回到Envoy,从而实现动态的服务发现。前端的APP,Web或者是业务系统的 Server端,通过一个4层的负载均衡LB接入到Envoy。
基于云原生的设计,解决了数据服务不同接口之间资源隔离的问题,同时可以基于请求量实现动态的水平扩展,同时借助Envoy实现了限流、熔断的功能。
最后,我们总结数据服务架构的关键,主要有以下三点:文章来源:https://www.toymoban.com/news/detail-430876.html
支持丰富的数据源:包括大宽表、文本文件、机器学习模型(模型也是一种数据资产),来构建完善的数据服务。
支持多样取数方式:除了支持同步快速取数之外,还支持异步查询取数、推送结果、定时任务等多样化方式,以满足业务多种场景需求。
建设统一的API网关:集成权限管控、限流降级、流量管理等于一体,不仅平台创建的服务可以注册进API网关,用户自己开发的API也可注册进API网关,从而享受已有的基础网关能力,为业务提供数据服务能力。文章来源地址https://www.toymoban.com/news/detail-430876.html
到了这里,关于数据中台选型前必读(七):解读数据服务的四大关键技术的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!