活动地址:CSDN21天学习挑战赛
一、Selenium搭建环境
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持目前比较主流的浏览器。它也实现了诸多自动化功能,比如软件自动化测试,检测软件与浏览器兼容性,自动录制、生成不同语言的测试脚本,以及自动化爬虫等。
1、安装
pip install selenium

2、安装Chrome安装浏览器驱动WebDriver
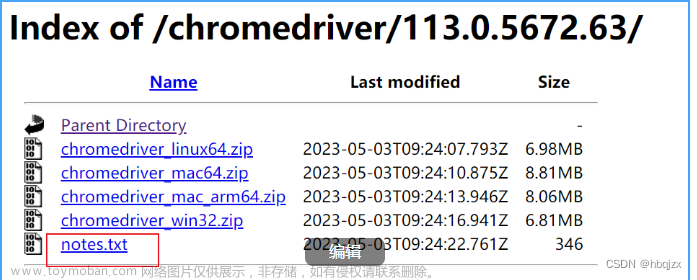
Chrome驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
1)查看Chrome浏览器版本

2)在驱动器版本里选择一个版本相近的




3)常用方法或属性
| driver 常用方法或属性 | 说明 |
|---|---|
close() |
关闭当前标签页 |
quit() |
关闭浏览器 |
forward() |
页面前进 |
back() |
页面返回 |
page_source |
当前标签页浏览器渲染之后的网页源代码 |
current_url |
当前标签页的url |
screen_shot(img_name) |
页面截图 |
(1)实战有界面


from selenium import webdriver
import time
# 创建Chrome浏览器对象
browser = webdriver.Chrome()
# 发送请求
browser.get('https://www.baidu.com/')
# 打印标题
print(browser.title)
# 延迟几秒看下浏览器
time.sleep(3)
# 退出浏览器
browser.quit()
(2)实战无界面
headless支持无界面命令模式
注意:chrome_options已经弃用了,改为options即可
DeprecationWarning: use options instead of chrome_options


from selenium import webdriver
# 创建Chrome浏览器对象
chrome_opt = webdriver.ChromeOptions()
# 开启无界面模式
chrome_opt.add_argument('--headless')
# 禁用gpu
chrome_opt.add_argument('--disable-gpu')
# 实例化配置带有driver对象
browser = webdriver.Chrome(options=chrome_opt)
# 发送请求
browser.get('https://www.baidu.com/')
# 打印标题
print(browser.title)
# 退出浏览器
browser.quit()
(3)常用参数说明
| 常用参数 | 说明 |
|---|---|
--user-agent="" |
设置请求头的User-Agent |
--window-size=1280x1024 |
设置浏览器分辨率(窗口大小) |
--start-maximized |
最大化运行(全屏窗口),不设置,取元素会报错 |
--disable-infobars |
禁止使用浏览器正在被自动化程序控制的提示 |
--incognito |
隐身模式(无痕模式) |
--hide-scrollbars |
隐藏滚动条, 应对一些特殊页面 |
--disable-javascript |
禁止使用javascript |
--blink-settings=imagesEnabled=false |
不加载图片, 提升速度 |
--headless |
浏览器无界面 |
--ignore-certificate-errors |
禁止使用扩展插件并实现窗口最大化 |
--disable-gpu |
禁止使用GPU加速 |
–disable-software-rasterizer |
禁止使用谷歌浏览器GPU加速-配置2(linux上用) |
--disable-extensions |
禁止使用扩展插件 |
--start-maximized |
最大化运行(全屏窗口) |
(4)八中元素定位方法
- 老版本方法
| 定位方法 | 说明 |
|---|---|
find_element_by_id() |
元素的id来定位 |
find_element_by_name() |
元素的name来定位 |
find_element_by_tag_name() |
元素的标签名来定位 |
find_element_by_class_name() |
元素的class来定位 |
find_element_by_link_text() |
元素标签对之间的文字信息来定位 |
find_element_by_partrial_link_text() |
元素标签对之间的部分文字信息来定位 |
find_element_by_xpath() |
1、用标签名的层级关系来定位元素的绝对路径 2、用元素的属性来定位 |
find_element_by_css_selector() |
id、class、元素、属性、层级等都多种定位方法 |
- 新版本方法
注意:
获取单个元素
driver.find_element()
find_element(By.ID, 'kw')
find_element(by=By.ID, value='kw')
获取多个元素
driver.find_elements()
find_elements(By.ID, 'kw')
find_elements(by=By.ID, value='kw')
- 案例

from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 打开chrome浏览器
driver = webdriver.Chrome()
# 打开百度搜索页面
driver.get('http://www.biqugse.com/')
# 通过id定位元素
id = driver.find_element(By.ID, 'wrapper')
print(id)
# 通过name定位元素
name = driver.find_element(By.NAME, 'password')
print(name)
# 通过name定位多元素
names = driver.find_elements(By.NAME, 'password')
print(names)
# 定位class元素
class_name = driver.find_element(By.CLASS_NAME, 'cc')
print(class_name)
# 定位class_name多元素
class_names = driver.find_elements(By.CLASS_NAME, 'cc')
print(class_names)
# 通过xpath来获取元素
xpath = driver.find_element(By.XPATH, '//*[@id="wrapper"]/div[6]/div/p[2]')
print(xpath)
print(xpath.text)
# 通过link_text标签来获取元素(精确定位)
link_text = driver.find_element(By.LINK_TEXT, '设为首页')
print(link_text)
# 通过link_text标签来获取元素(模糊定位)
partial_link_text = driver.find_element(By.PARTIAL_LINK_TEXT, '首页')
print(partial_link_text)
# 通过tag标签来获取元素
tag = driver.find_element(By.TAG_NAME, 'img')
print(tag)
# 强制等待2秒查看效果
time.sleep(2)
# 关闭浏览器
driver.quit()
结果:
D:\python383\python.exe D:/pythonproject/csdn/RequestsDemo.py
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="6d607d2d-cc8e-46a1-87ac-bf4c1324fb98")>
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="1cca4773-69f9-4059-b29c-e534b907af6c")>
[<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="1cca4773-69f9-4059-b29c-e534b907af6c")>]
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="09e4359e-d6fb-4c6e-881e-c25e53689cd7")>
[<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="09e4359e-d6fb-4c6e-881e-c25e53689cd7")>, <selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="f99f220f-70f1-4dae-970c-9a0a1c5f537c")>]
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="61ef193c-bbf0-4619-b847-f7566b527a66")>
Copyright © 2021 笔趣阁 京ICP备88080001号
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="ccfe2632-e494-49b2-bd4d-138642a4bc13")>
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="ccfe2632-e494-49b2-bd4d-138642a4bc13")>
================================================================================ 分割线 ================================================================================
<selenium.webdriver.remote.webelement.WebElement (session="d4a0544fde3220aa6c6d73d10f4eef7d", element="aa815fdd-a8af-475b-bb4f-6214e137b118")>
Process finished with exit code 0
(5)元素的操作
 文章来源:https://www.toymoban.com/news/detail-431447.html
文章来源:https://www.toymoban.com/news/detail-431447.html
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 打开chrome浏览器
driver = webdriver.Chrome()
# 打开百度搜索页面
driver.get('http://www.biqugse.com/')
# 通过id定位元素
# 通过xpath来获取元素文本信息
xpath = driver.find_element(By.XPATH, '//*[@id="wrapper"]/div[6]/div/p[2]')
print(xpath.text)
# 通过xpath来获取元素属性信息
xpath = driver.find_element(By.TAG_NAME, 'a')
print(xpath.get_attribute('href'))
# 强制等待2秒查看效果
time.sleep(2)
# 关闭浏览器
driver.quit()
(6)前进后退
# 前进
browser.forward()
# 后退
browser.back()
(7)嵌套JS
 文章来源地址https://www.toymoban.com/news/detail-431447.html
文章来源地址https://www.toymoban.com/news/detail-431447.html
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'http://www.biqugse.com/'
browser.get(url)
# js语句 滚动条拉倒最底部
js = "var q=document.documentElement.scrollTop=10000"
# 执行js的方法
browser.execute_script(js)
time.sleep(3)
browser.quit()
到了这里,关于Python selenium自动化操作Chrome浏览器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!