1.hudi的介绍
Hudi 是什么
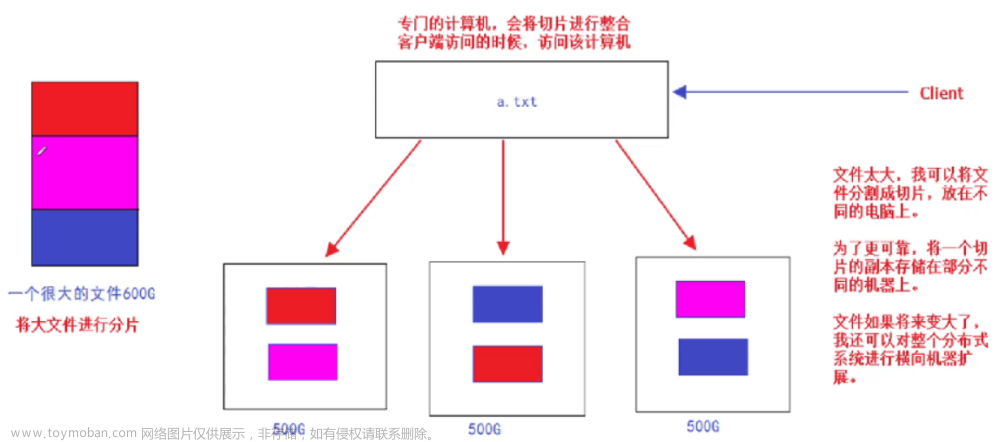
Hudi(Hadoop Upserts Deletes and Incrementals缩写):用于管理分布式文件系统DFS上大型分析数据集存储。一言以蔽之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi 功能
- Hudi是在大数据存储上的一个数据集,可以将Change Logs通过upsert的方式合并进Hudi;
- Hudi对上可以暴露成一个普通Hive或Spark表,通过API或命令行可以获取到增量修改的信息,继续供下游消费;
- Hudi保管修改历史,可以做时间旅行或回退;
- Hudi内部有主键到文件级的索引,默认是记录到文件的布隆过滤器。
Hudi 特性
Apache Hudi使得用户能在Hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,不仅可以批处理,还可以在数据湖上进行流处理。
- Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
- 变更流:Hudi对获取数据变更提供了一流的支持,可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询类别。
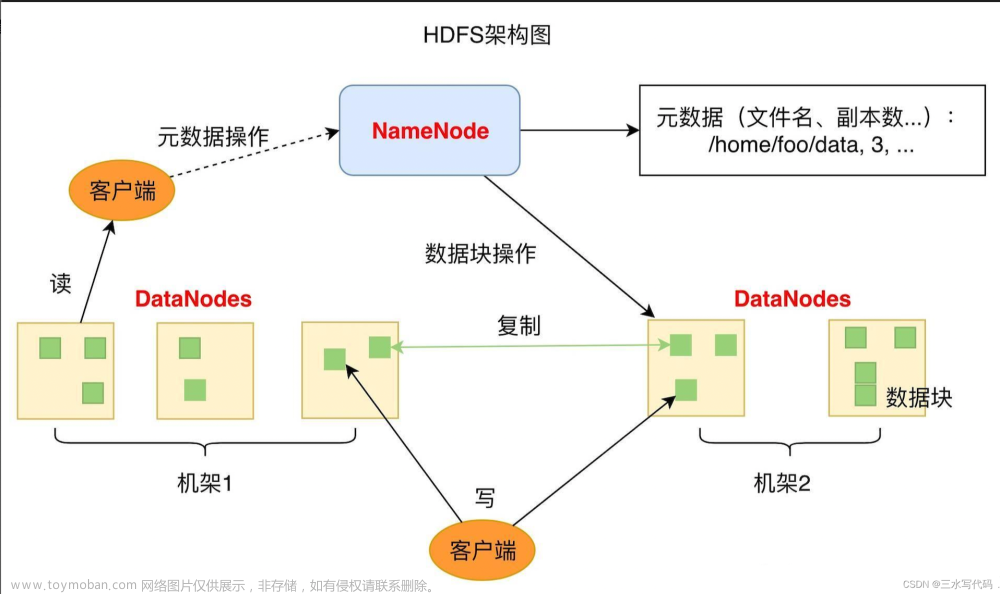
Hudi 基础架构
- 通过DeltaStreammer、Flink、Spark等工具,将数据摄取到数据湖存储,可使用HDFS作为数据湖的数据存储;
- 基于HDFS可以构建Hudi的数据湖;
- Hudi提供统一的访问Spark数据源和Flink数据源;
- 外部通过不同引擎, 如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA、AWS Redshit访问接口。
2.hudi的编译和安装
参考地址:hudi编译网址
和flink整合:
1.启动hdfs
2.启动flink
- 将 hive-exec-3.1.2.jar包放入到flink安装目录的lib下:/export/server/flink/lib(三台都要放)
- Flink集成hudi,本质就是为flink添加hudi依赖包:
- 从编译的hudi目录下/export/software/hudi-0.11.1/packaging/hudi-flink-bundle/target/将 hudi-flink1.14-bundle_2.12-0.11.1.jar,放入flink安装目录的lib下即可:/export/server/flink/lib(如果有多台都要放)。
3.体验flink整合hudi
- 批量插入数据:
-- 在SQL Cli设置分析结果展示模式为tableau模式:
set sql-client.execution.result-mode = tableau;
--创建t1表,在SQL Cli执行:
CREATE TABLE t1(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi', -- 连接器指定hudi
'path' = 'hdfs://node1:8020/hudi/t1', -- 数据存储地址
'table.type' = 'MERGE_ON_READ' -- 表类型,默认COPY_ON_WRITE,可选MERGE_ON_READ
);
--使用values插入数据,执行:
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
-- 查询数据
select * from t1;
--更新数据 更新主键为id1的数据内容,执行:
insert into t1 values
('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');
- 流式查询
参数名称 是否必填 默认值 备注
read.streaming.enabled false false 设置为true,开启stream query
read.start-commit false the latest commit Instant time的格式为:’yyyyMMddHHmmss’
read.streaming_skip_compaction false false 是否不消费compaction commit,消费compaction commit会出现重复数据
clean.retain_commits false 10 当开启change log mode,保留的最大commit数量。如果checkpoint interval为5分钟,则保留50分钟的change log|
注意:如果开启read.streaming.skip_compaction,但stream reader的速度比clean.retain_commits慢,可能会造成数据丢失
--流式查询
-- 流式查询(Streaming Query)需要设置read.streaming.enabled = true。再设置read.start-commit,如果想消费所有数据,设置值为earliest。
CREATE TABLE t2(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi', -- 连接器指定为hudi
'path' = 'hdfs://node1:8020/hudi/t2', -- 数据存储地址
'table.type' = 'MERGE_ON_READ', -- 表类型,默认COPY_ON_WRITE,可选MERGE_ON_READ
'read.streaming.enabled' = 'true', -- 默认值false,设置为true,开启stream query
'read.start-commit' = '20210316134557', -- start-commit之前提交的数据不显示,默认值the latest commit,instant time的格式为:‘yyyyMMddHHmmss’
'read.streaming.check-interval' = '4' -- 检查间隔,默认60s
);
INSERT INTO t2 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
select * from t2;
4.Apache Hudi 核心概念剖析
总述
Hudi提供了Hudi表的概念,这些表支持CRUD(增删改查)操作,可以利用现有的大数据集群比如HDFS做数据文件存储,然后使用SparkSQL或Hive等分析引擎进行数据分析查询。
- Hudi表的三个主要组件:
- 有序的时间轴元数据,类似于数据库事务日志。
- 分层布局的数据文件:实际写入表中的数据;
- 索引(多种实现方式):映射包含指定记录的数据集。
4.1时间轴Timeline
Hudi把随着时间流逝,对表的一系列CRUD(增删改查)操作叫做Timeline,Timeline中某一次的操作,叫做Instant。Hudi的核心就是在所有的表中维护了一个包含在不同的即时(Instant)时间对数据集操作(比如新增、修改或删除)的时间轴(Timeline)。
在每一次对Hudi表的数据集操作时都会在该表的Timeline上生成一个Instant,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据。
同时,可以高效地只查询更改前的文件(如在某个Instant提交了更改操作后,仅query某个时间点之前的数据,则仍可以query修改前的数据)。
Timeline是Hudi用来管理提交(commit)的抽象,每个commit都绑定一个固定时间戳,分散到时间线上。在Timeline上,每个commit被抽象为一个HoodieInstant,一个instant记录了一次提交
(commit) 的行为(action)、时间戳(time)、和状态(state)。
- Hudi Instant由以下组件组成:
- Instant Action:
指的是对Hudi表执行的操作类型,目前包括COMMITS、CLEANS、DELTA_COMMIT、COMPACTION、ROLLBACK、SAVEPOINT这6种操作类型。- Commits:表示一批记录原子性的写入到一张表中。
- Cleans:清除表中不再需要的旧版本文件。
- Delta_commit:增量提交指的是将一批记录原子地写入MergeOnRead类型表,其中一些/所有数据都可以写入增量日志。
- Compaction:将行式文件转化为列式文件。
- Rollback:Commits或者Delta_commit执行不成功时回滚数据,删除期间产生的任意文件。
- Savepoint:将文件组标记为“saved”,cleans执行时不会删除对应的数据。
- Instant Time:本次操作发生的时间,通常是时间戳(例如:20190117010349),它按照动作开始时间的顺序单调递增;
- Instant State:表示在指定的时间点(Instant Time)对Hudi表执行操作(Instant Action)后,表所处的状态,目前包括REQUESTED(已调度但未初始化)、INFLIGHT(当前正在执行)、COMPLETED(操作执行完成)这3种状态。
- Instant Action:
- Hudi中的每个操作都是原子性的,Hudi保证了在时间轴上操作的原子性和基于Instant时间轴的一致性;
4.2文件管理
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。
Hudi为了实现数据的CRUD(增删改查),需要能够唯一标识一条记录,Hudi将把数据集中的**唯一字段(record
key ) +数据所在分区(partitionPath) 联合起来当做数据的唯一键。其数据集的组织目录结构与Hive表示非常相似,一份数据集对应着一个根目录**。数据集被打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件。在根目录下,每个分区都有唯一的分区路径,每个分区目录下有多个文件。
4.3数据文件
每个目录下面会存在属于该分区的多个文件,类似Hive表,每个Hudi表分区通过一个分区路径(partitionpath)来唯一标识。
在每个分区下面,通过文件分组(file groups)的方式来组织,每个分组对应一个唯一的文件ID。每个文件分组中包含多个文件分片(file slices)(一个新的 base commit time 对应一个新的文件分片,实际就是一个新的数据版本),每个文件分片包含一个Base文件(.parquet),这个文件是在执行COMMIT/COMPACTION操作的时候生成的,同时还生成了几个日志文件(.log.*),日志文件中包含了从该Base文件生成以后执行的插入/更新操作。
- Hudi的base file (parquet文件) 在footer的meta记录了record key组成的BloomFilter,用于在file based index的实现中实现高效率的key contains检测。
- Hudi的log(avro文件)是自己编码的,通过积攒数据buffer以LogBlock为单位写出,每个LogBlock
包含magic number、size、content、footer等信息,用于数据读、校验和过滤。
4.4Index 索引
基本介绍
Hudi通过索引机制将给定的hoodie键(RecordKey记录键+PartitionPath分区路径)一致地映射到文件id,从而提供高效的upsert。记录键和文件id之间的这种映射,一旦记录的第一个版本被写入文件,就永远不会改变。简而言之,映射文件组包含一组记录的所有版本。
对于Copy-On-Write表,可以实现快速upsert/delete操作,避免需要连接整个数据集以确定要重写哪些文件。对于Merge-On-Read表,这种设计允许Hudi绑定任何给定基本文件需要合并的记录数量。具体来说,给定的基本文件只需要针对作为该基本文件一部分的记录的更新进行合并。相反,没有索引组件的设计最终必须将所有基本文件与所有传入的更新/删除记录合并:
索引类型
1)目前,hudi支持以下索引选项,可以使用hoodie.index.type选择这些选项。
- Bloom Index(默认):使用由记录键构建的Bloom过滤器,还可以选择使用记录键范围修改候选文件。
- 简单索引:针对从存储表中提取的键执行传入更新/删除记录的精益连接。
- HBase索引:管理外部 Apache HBase 表中的索引映射。
- 自带实现:可以扩展此公共API以实现自定义索引。
Bloom Index和简单索引都有全局选项:hoodie.index.type=GLOBAL_BLOOM和hoodie.index.type=GLOBAL_SIMPLE。HBase索引本质上是一个全局索引。
2)全局索引和非全局索引之间的区别:
- 全局索引:全局索引在表的所有分区中强制执行键的唯一性,即保证表中对于给定的记录键只存在一条记录。全局索引提供了更强的保证,但更新/删除成本随着表的大小而增长,所以更适合小表。
- 非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依赖于写入器在更新/删除期间为给定的记录键提供相同的一致分区路径。但因为索引查找操作可以很好地随写入量而扩展,所以也可以提供更好的性能。
4.4表的存储类型
Hudi表类型定义了如何在DFS上对数据进行索引和布局,以及如何在此类组织之上实现上述基元和时间轴活动,即如何写入数据。反过来,定义如何向查询公开基础数据即为如何读取数据。
表类型 支持的查询类型
写入时复制 (Copy On Write) 快照查询(Snapshot Queries)+ 增量查询(Incremental Queries)
读取时合并 (Merge On Read) 快照查询(Snapshot Queries)+ 增量查询(Incremental Queries)+ 读取优化查询(Read Opitimized Queries)
4.5 数据计算模型
Hudi是Uber主导开发的开源数据湖框架,所以大部分的出发点都来源于Uber自身场景,比如司机数据和乘客数据通过订单Id来做Join等。在Hudi过去的使用场景里,和大部分公司的架构类似,采用批式和流式共存的Lambda架构,后来Uber提出增量Incremental模型,相对批式来讲,更加实时;相对流式而言,更加经济。
批式模型(Batch)
批式模型就是使用MapReduce、Hive、Spark等典型的批计算引擎,以小时任务或者天任务的形式来做数据计算。
- 延迟:小时级延迟或者天级别延迟。这里的延迟不单单指的是定时任务的时间,在数据架构里,
这里的延迟时间通常是定时任务间隔时间+一系列依赖任务的计算时间+数据平台最终可以展示结果的时间。数据量大、逻辑复杂的情况下,小时任务计算的数据通常真正延迟的时间是2-3小时。 - 数据完整度:数据较完整。以处理时间为例,小时级别的任务,通常计算的原始数据已经包含了小时内的所有数据,所以得到的数据相对较完整。但如果业务需求是事件时间,这里涉及到终端的一些延迟上报机制,在这里,批式计算任务就很难派上用场。
- 成本:成本很低。只有在做任务计算时,才会占用资源,如果不做任务计算,可以将这部分批式计算资源出让给在线业务使用。但从另一个角度来说成本是挺高的,如原始数据做了一些增删改查,数据晚到的情况,那么批式任务是要全量重新计算。
流式模型(Stream)
流式模型,典型的就是使用Flink来进行实时的数据计算。
- 延迟:很短,甚至是实时。
- 数据完整度:较差。因为流式引擎不会等到所有数据到齐之后再开始计算,所以有一个
watermark 的概念,当数据的时间小于watermark
时,就会被丢弃,这样是无法对数据完整度有一个绝对的报障。在互联网场景中,流式模型主要用于活动时的数据大盘展示,对数据的完整度要求并不算很高。在大部分场景中,用户需要开发两个程序,一是流式数据生产流式结果,二是批式计算任务,用于次日修复实时结果。 - 成本:很高。因为流式任务是常驻的,并且对于多流Join的场景,通常要借助内存或者数据库来做state的存储,不管是序列化开销,还是和外部组件交互产生的额外IO,在大数据量下都是不容忽视的。
增量模型(Incremental)
针对批式和流式的优缺点,Uber提出了增量模型(Incremental Mode),相对批式来讲,更加实时;相对流式而言,更加经济。增量模型,简单来讲,是以mini batch的形式来跑准实时任务。Hudi在增量模型中支持了两个最重要的特性:
- Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,可以往Hive中写入增量数据,而不是每次进行完全的覆盖。(Hudi自身维护了key->file的映射,所以当upsert时很容易找到key对应的文件)
- Incremental Query:增量查询,减少计算的原始数据量。以Uber中司机和乘客的数据流Join为例,每次抓取两条数据流中的增量数据进行批式的Join即可,相比流式数据而言,成本要降低几个数量级。
4.6 Hudi 支持表类型
Hudi提供两类型表:写时复制(Copy on Write,COW)表和读时合并(Merge On Read,MOR)表。
- Copy On Write:仅使用列文件格式(例如parquet)存储数据。通过在写入过程中执行同步合并以更新版本并重写文件。用户的update会重写数据所在的文件,所以是一个写放大很高,但是读放大为0,适合写少读多的场景。
- Merge On Read:使用列式(例如parquet)+ 基于行(例如avro)的文件格式组合来存储数据。更新记录到增量文件中,然后进行同步或异步压缩以生成列文件的新版本。整体的结构有点像LSM-Tree,用户的写入先写入到delta data中,这部分数据使用行存,这部分delta data可以手动 merge到存量文件中,整理为parquet的列存结构。
Copy On Write,简称COW。顾名思义,它是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。
- 更新update:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
- 读取read:在读取数据时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景。
如何工作
Copy On Write简称COW,在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据,生成一个新的持有base file (*.parquet,对应写入的instant time)的File Slice,数据存储格式为parquet列式存储格式。用户在读取数据时,会扫描所有最新的File Slice下的base file。
总结
- 优点:读取时,只读取对应分区的一个数据文件即可,较为高效。
- 缺点:数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。
Merge On Read(MOR)
Merge On Read,简称MOR。是COW的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。
Merge-On-Read表存在列式格式的Base文件,也存在行式格式的增量(Delta)文件,新到达的更新都会写到增量日志文件中(log文件),根据实际情况进行COMPACTION操作来将增量文件合并到Base文件上。
通过参数”hoodie.compact.inline”来开启是否一个事务完成后执行压缩操作,默认不开启。通过参数“hoodie.compact.inline.max.delta.commits”来设置提交多少次合并log文件到新的parquet文件,默认是5次。
这里注意,以上两个参数都是针对每个File Slice而言。我们同样可以控制“hoodie.cleaner.commits.retained”来保存有多少parquet文件,即控制FileSlice文件个数。
- 更新Update:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,
最后创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。 - 读取Read:在读取数据集时,需要先将delta log增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
如何工作
上图中,每个文件分组都对应一个增量日志文件(Delta Log File)。COMPACTION操作在后台定时执行。会把对应的增量日志文件合并到文件分组的Base文件中,生成新版本的Base文件。
对于查询10:10之后的数据的Read Optimized Query,只能查询到10:05及其之前的数据,看不到之后的数据,查询结果只包含版本为10:05、文件ID为1、2、3的文件;但是Snapshot Query是可以查询到10:05之后的数据的。
Read Optimized Query与Snapshot Query是两种不同的查询类型,后文会解释到。
总结
- 优点:由于写入数据先写delta log,且delta log较小,所以写入成本较低。
- 缺点:需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta
log和老数据文件合并。
COW vs MOR
对于写时复制(COW)和读时合并(MOR)writer来说,Hudi的WriteClient是相同的。
- COW表,用户在snapshot读取的时候会扫描所有最新的FileSlice下的base file。
- MOR表,在READ OPTIMIZED模式下,只会读最近的经过compaction的commit。
4.6 查询类型(Query Type)
Hudi支持三种不同的查询表的方式:Snapshot Queries、Incremental Queries和Read Optimized Queries。
Snapshot Queries(快照查询)
-
查询某个增量提交操作中数据集的最新快照,先进行动态合并最新的基本文件(parquet)和增量文件(log)来提供近实时数据集(通常会存在几分钟的延迟)。即读取所有partiiton下每个FileGroup最新的FileSlice中的文件,Copy On Write表读parquet文件,Merge On Read表读parquet+log文件。
-
快照查询,可以查询指定commit/delta commit即时操作后表的最新快照。
在读时合并(MOR)表的情况下,它通过即时合并最新文件片的基本文件和增量文件来提供近实时表(几分钟)。
对于写时复制(COW),它可以替代现有的parquet表(或相同基本文件类型的表),同时提供upsert/delete和其他写入方面的功能,可以理解为查询最新版本的Parquet数据文件。
Incremental Queries(增量查询)
-
仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个Instant)作为条件,来查询此条件之后的新数据。这有效的提供变更流来启用增量数据管道。
-
增量查询,可以查询给定commit/delta commit即时操作以来新写入的数据。有效的提供变更流来启用增量数据管道。
Read Optimized Queries(读优化查询)
- 直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。并保证与非Hudi列式数据集相比,具有相同的列式查询性能。
- 也可查看给定的commit/compact即时操作的表的最新快照。
- 读优化查询和快照查询相同仅访问基本文件,提供给定文件片自上次执行压缩操作以来的数据。通常查询数据的最新程度的保证取决于压缩策略。
- 读优化查询,可查看给定的commit/compact即时操作的表的最新快照。仅将最新文件片的基本/列文件暴露给查询,并保证与非Hudi表相同的列查询性能。
4.7 数据写操作
在Hudi数据湖框架中支持三种方式写入数据:UPSERT(插入更新)、INSERT(插入)和BULK INSERT(批插入)。
UPSERT
这是默认操作。在该操作中,数据先通过index打标(INSERT/UPDATE),即通过查找索引,将输入记录标记为插入或更新。再运行启发式算法以确定如何最好地将这些记录放到存储上。
- 开始提交:判断上次任务是否失败,如果失败会触发回滚操作。
然后会根据当前时间生成一个事务开始的请求标识元数据。 - 构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd
对象,方便后续数据去重和数据合并。 - 数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据写入Hudi
表。 - 数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileid,在数据合并时需要知道数据update操作向那个fileId文件写入新的快照文件。
- 数据合并:Hudi 有两种模式cow和mor。在cow模式中会重写索引命中的fileId快照文件;在mor
模式中根据fileId 追加到分区中的log 文件。 - 完成提交:在元数据中生成xxxx.commit文件,只有生成commit
元数据文件,查询引擎才能根据元数据查询到刚刚upsert 后的数据。 - compaction压缩:主要是mor模式中才会有,他会将mor模式中的xxx.log
数据合并到xxx.parquet 快照文件中去。 - hive元数据同步:hive
的元素数据同步这个步骤需要配置非必需操作,主要是对于hive和presto
等查询引擎,需要依赖hive元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。
第二种解释:
1)Copy On Write
(1)先对 records 按照 record key 去重
(2)首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入)
(3)对于 update 消息,会直接找到对应 key 所在的最新 FileSlice 的 base 文件,并做 merge 后写新的 base file (新的 FileSlice)
(4)对于 insert 消息,会扫描当前 partition 的所有 SmallFile(小于一定大小的 base file),然后 merge 写新的 FileSlice;如果没有 SmallFile,直接写新的 FileGroup + FileSlice
2)Merge On Read
(1)先对 records 按照 record key 去重(可选)
(2)首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入)
(3)如果是 insert 消息,如果 log file 不可建索引(默认),会尝试 merge 分区内最小的 base file (不包含 log file 的 FileSlice),生成新的 FileSlice;如果没有 base file 就新写一个 FileGroup + FileSlice + base file;如果 log file 可建索引,尝试 append 小的 log file,如果没有就新写一个 FileGroup + FileSlice + base file
(4)如果是 update 消息,写对应的 file group + file slice,直接 append 最新的 log file(如果碰巧是当前最小的小文件,会 merge base file,生成新的 file slice)
(5)log file 大小达到阈值会 roll over 一个新的
INSERT
就使用启发式算法确定文件大小而言,此操作与插入更新(UPSERT)非常相似,但此操作完全跳过了索引查找步骤。
因此,对于日志重复数据删除等用例(结合下面提到的过滤重复项的选项),它可以比插入更新快得多。
插入也适用于这种用例,这种情况数据集可以允许重复项,但只需要Hudi的事务写/增量提取/存储管理功能。
第二种解释:
1)Copy On Write
(1)先对 records 按照 record key 去重(可选)
(2)不会创建 Index
(3)如果有小的 base file 文件,merge base file,生成新的 FileSlice + base file,否则直接写新的 FileSlice + base file
2)Merge On Read
(1)先对 records 按照 record key 去重(可选)
(2)不会创建 Index
(3)如果 log file 可索引,并且有小的 FileSlice,尝试追加或写最新的 log file;如果 log file 不可索引,写一个新的 FileSlice + base file
备注:Key 生成策略
用来生成 HoodieKey(record key + partition path),目前支持以下策略:
- 支持多个字段组合 record keys
- 支持多个字段组合的 parition path (可定制时间格式,Hive style path name)
- 非分区表
BULK_INSERT
Apache Hudi除了支持insert和upsert外,还支持bulk_insert操作来将数据初始化至Hudi表中,该操作相比insert和upsert操作速度更快,效率更高。bulk_insert不会查看已存在数据的开销并且不会进行小文件优化。
三种模式
bulk_insert按照以下原则提供了3种开箱即用的模式(PARTITION_SORT、GLOBAL_SORT、NONE)来满足不同的需求:
- 如果数据布局良好,排序将为我们提供良好的压缩和upsert性能。特别是记录键具有某种排序(时间戳等)特征,则排序将有助于在upsert期间裁剪大量文件,如果数据是按频繁查询的列排序的,那么查询将利用parquet谓词下推来裁剪数据,以确保更低的查询延迟。
- 写parquet文件是内存密集型操作。当将大量数据写入一个也被划分为1000个分区的表中时,如果不进行任何排序,写入程序可能必须保持1000个parquet写入器处于打开状态,同时会产生不可持续的内存压力,并最终导致崩溃。
- 在批量导入数据时,最好控制好少的文件个数,以避免以后写入和查询时的元数据开销。
配置
可以通过hoodie.bulkinsert.sort.mode配置项来设置上述模式(NONE, GLOBAL_SORT
, PARTITION_SORT),默认值为GLOBAL_SORT。
删除策略
1)逻辑删:将 value 字段全部标记为 null
2)物理删:
(1)通过 OPERATION_OPT_KEY 删除所有的输入记录
(2)配置 PAYLOAD_CLASS_OPT_KEY = org.apache.hudi.EmptyHoodieRecordPayload 删除所有的输入记录
(3)在输入记录添加字段:_hoodie_is_deleted
总结
通过对写流程的梳理可以了解到 Apache Hudi 相对于其他数据湖方案的核心优势:
(1)写入过程充分优化了文件存储的小文件问题,Copy On Write 写会一直将一个 bucket (FileGroup)的 base 文件写到设定的阈值大小才会划分新的 bucket;Merge On Read 写在同一个 bucket 中,log file 也是一直 append 直到大小超过设定的阈值 roll over。
(2)对 UPDATE 和 DELETE 的支持非常高效,一条 record 的整个生命周期操作都发生在同一个 bucket,不仅减少小文件数量,也提升了数据读取的效率(不必要的 join 和 merge)。
4.8 模式介绍
GLOBAL_SORT(全局排序)
- upsert效率高:全局排序就是为了提高upsert的性能。
- insert效率低:由于全局排序的过程,导致insert的性能降低。
PARTITION_SORT(分区排序)
- upsert效率居中:不是全局排序,而仅对spark分区内排序
- insert效率居中:无论是什么排序过程,总会降低insert效率,但可以缓解内存压力。
NONE
- upsert效率低:未排序的原始文件进行upsert索引查找期间大量读取bloom filter
- insert效率高:虽然写入效率高,但会有内存风险。也会有大量小文件产生
用户自定义Partitioner
如果上述模式都不能满足需求,用户可以自定义实现partitioner来满足业务需求。
4.9 核心参数设置
Flink可配参数:https://hudi.apache.org/docs/configurations#FLINK_SQL
4.9.1 去重参数
-- 设置单个主键
create table hoodie_table (
f0 int primary key not enforced,
f1 varchar(20),
...
) with (
'connector' = 'hudi',
...
)
-- 设置联合主键
create table hoodie_table (
f0 int,
f1 varchar(20),
...
primary key(f0, f1) not enforced
) with (
'connector' = 'hudi',
...
)
名称 说明 默认值 备注
hoodie.datasource.write.recordkey.field 主键字段 – 支持主键语法 PRIMARY KEY 设置,支持逗号分隔的多个字段
precombine.field
(0.13.0 之前版本为
write.precombine.field) 去重时间字段 – record 合并的时候会按照该字段排序,选值较大的 record 为合并结果;不指定则为处理序:选择后到的 record
4.9.2 并发参数
可以flink建表时在with中指定,或Hints临时指定参数的方式:在需要调整的表名后面加上 /*+ OPTIONS() */
insert into t2 /*+ OPTIONS('write.tasks'='2','write.bucket_assign.tasks'='3','compaction.tasks'='4') */
select * from sourceT;
4. 10 Flink写入数据到hudi的四种方式
bulk_insert
用于快速导入快照数据到hudi
基本特性
- bulk_insert可以减少数据序列化以及合并操作,于此同时,该数据写入方式会跳过数据去重,所以用户需要保证数据的唯一性。
- bulk_insert在批量写入模式中是更加有效率的。默认情况下,批量执行模式按照分区路径对输入记录进行排序,并将这些记录写入Hudi,该方式可以避免频繁切换文件句柄导致的写性能下降。
- bulk_insert的并行度有write.tasks参数指定,并行度会影响小文件的数量。理论上来说,bulk_insert的并行度就是bucket的数量(特别是,当每个bucket写到最大文件大小时,它将转到新的文件句柄。最后,文件的数量将大于参数write.bucket.assign.tasks指定的数量)
Flink SQL实践
准备工作
- 上传jar包:将flink-connector-jdbc_2.12-1.14.5.jar上传至/export/server/flink/lib目录下
- 创建mysql源表
CREATE DATABASE IF NOT EXISTS test;
create table if not exists test.stu(
id bigint not null primary key,
name varchar(32),
age int not null
) charset = utf8;
insert into test.stu values
(1,'zhangsan',11),
(2,'lisi',13),
(3,'wangwu',17),
(4,'zhaoliu',19),
(5,'maoqi',23);
--启动hdfs
/export/server/hadoop/sbin/start-dfs.sh
-- 启动Flink服务
node1上启动Flink Standalone模式:
/export/server/flink/bin/start-cluster.sh
node1上启动Flink sql-cli:
/export/server/flink/bin/sql-client.sh
--设置参数
set sql-client.execution.result-mode = tableau;
set execution.checkpointing.interval=30sec;
--创建mysql映射表
CREATE TABLE IF NOT EXISTS stu(
id bigint not null,
name varchar(32),
age int not null,
PRIMARY KEY (id) NOT ENFORCED
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://node1:3306/test?serverTimezone=GMT%2B8',
'username' = 'root',
'password' = '123456',
'table-name' = 'stu'
);
select * from stu;
--创建hudi映射表
create table stu_sink_hudi(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced
)partitioned by (`age`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/test/stu_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'bulk_insert',
'write.precombine.field' = 'age'
);
--插入数据
insert into stu_sink_hudi select * from stu;
Index bootstrap
基本特性
该方式用于快照数据+增量数据的导入。如果快照数据已经通过bulk_insert导入到hudi,那么用户就可以近实时插入增量数据并且通过index bootstrap功能来确保数据不会重复。
如果这个过程特别耗时,那么在写快照数据的时候可以多设置计算资源,然后在插入增量数据时减少计算资源。
可选配置参数 参数名称 是否必须 默认值 参数说明
index.bootstrap.enabled true false 当启用index bootstrap功能时,会将Hudi表中的剩余记录一次性加载到Flink状态中
index.partition.regex false * 优化参数,设置正则表达式来过滤分区。 默认情况下,所有分区都被加载到flink状态
使用方法
-
CREATE TABLE创建一条与Hudi表对应的语句。 注意这个table.type配置必须正确。
-
设置index.bootstrap.enabled = true来启用index bootstrap功能
-
在flink-conf.yaml文件中设置Flink checkpoint的容错机制,设置配置项execution.checkpointing.tolerable-failed-checkpoints = n(取决于Flink checkpoint执行时间)
-
等待直到第一个checkpoint成功,表明index bootstrap完成。
-
在index bootstrap完成后,用户可以退出并保存savepoint(或直接使用外部 checkpoint)。
-
重启任务,并且设置index.bootstrap.enable 为 false
-
索引引导是一个阻塞过程,因此在索引引导期间无法完成checkpoint。
-
index bootstrap由输入数据触发。用户需要确保每个分区中至少有一条记录。
-
index bootstrap是并发执行的。用户可以在日志文件中通过finish loading the index under partition以及Load record form file观察index bootstrap的进度。
-
第一个成功的checkpoint表明index bootstrap已完成。从checkpoint恢复时,不需要再次加载索引。
Flink SQL实践
前提条件:
- 已有50w条数据已写入kafka,使用bulk_insert的方式将其导入hudi表。
- 再通过创建任务消费最新kafka数据,并开启index bootstrap特性。
--创建Kafka话题并产生消息
-- 启动zookeeper
zkServer.sh start
--启动kafka集群
cd /export/server/kafka_2.12-2.4.1/
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
-- 创建topic
bin/kafka-topics.sh --create \
--zookeeper node1:2181 \
--replication-factor 1 \
--partitions 1 \
--topic cdc_mysql_stu2_sink_test
--(如果删除topic)
bin/kafka-topics.sh --delete --zookeeper node1:2181 \
--topic cdc_mysql_stu2_sink_test
--启动kafka生产者
bin/kafka-console-producer.sh --broker-list node1.itcast.cn:9092 --topic cdc_mysql_stu2_sink_test
--往topic中插入一批测试数据
1,zhangsan,11
2,lisi,13
3,wangwu,17
4,zhaoliu,19
5,maoqi,23
--创建bulk_insert任务
create table stu2_binlog_source_kafka(
id bigint not null,
name string,
age int not null
) with (
'connector' = 'kafka',
'topic' = 'cdc_mysql_stu2_sink_test',
'properties.bootstrap.servers' = 'node1:9092',
'format' = 'csv',
'scan.startup.mode' = 'earliest-offset',
'properties.group.id' = 'testGroup'
);
create table stu2_binlog_sink_hudi(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced
)partitioned by (`age`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/test/stu2_binlog_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'bulk_insert',
'write.precombine.field' = 'age'
);
insert into stu2_binlog_sink_hudi select * from stu2_binlog_source_kafka;
--创建开启index bootstrap特性、离线压缩任务。
create table stu2_binlog_source_kafka_1(
id bigint not null,
name string,
age int not null
) with (
'connector' = 'kafka',
'topic' = 'cdc_mysql_stu2_sink_test',
'properties.bootstrap.servers' = 'node1:9092',
'format' = 'csv',
'scan.startup.mode' = 'earliest-offset',
'properties.group.id' = 'testGroup'
);
create table stu2_binlog_sink_hudi_1(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced
)partitioned by (`age`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/test/stu2_binlog_sink_hudi_1',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'upsert',
'write.tasks' = '4',
'write.precombine.field' = 'age',
'compaction.async.enabled' = 'false',
'index.bootstrap.enabled' = 'true'
);
insert into stu2_binlog_sink_hudi_1 select * from stu2_binlog_source_kafka_1;
--Kafka中添加消息
6,haoba,29
备注:
bulk_insert批写入和Index bootstrap全量接增量看结果:
在hudi表所对应的hdfs上是否有新数据的写入,bulk_insert没有新数据写入,Index bootstrap全量接增量有新数据的写入。
4.11 Changelog 模式
如果希望 Hoodie 保留消息的所有变更(I/-U/U/D),之后接上 Flink 引擎的有状态计算实现全链路近实时数仓生产(增量计算),Hoodie 的 MOR 表通过行存原生支持保留消息的所有变更(format 层面的集成),通过流读 MOR 表可以消费到所有的变更记录。
名称 Required 默认值 说明
changelog.enabled false false 默认是关闭状态,即 UPSERT 语义,所有的消息仅保证最后一条合并消息,中间的变更可能会被 merge 掉;改成 true 支持消费所有变更。
批(快照)读仍然会合并所有的中间结果,不管 format 是否已存储中间状态。
开启 changelog.enabled 参数后,中间的变更也只是 Best Effort: 异步的压缩任务会将中间变更合并成 1 条,所以如果流读消费不够及时,被压缩后只能读到最后一条记录。当然,通过调整压缩的 buffer 时间可以预留一定的时间 buffer 给 reader,比如调整压缩的两个参数:
compaction.delta_commits:5
compaction.delta_seconds: 3600。
说明:
Changelog 模式开启流读的话,要在 sql-client 里面设置参数:
set sql-client.execution.result-mode=tableau;
或者
set sql-client.execution.result-mode=changelog;
否则中间结果在读的时候会被直接合并。(参考:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sqlclient/#running-sql-queries),
--使用changelog
set sql-client.execution.result-mode=tableau;
CREATE TABLE t6(
id int,
ts int,
primary key (id) not enforced
) WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/tmp/hudi_flink/t6',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4',
'changelog.enabled' = 'true'
);
insert into t6 values (1,1);
insert into t6 values (1,2);
set table.dynamic-table-options.enabled=true;
select * from t6/*+ OPTIONS('read.start-commit'='earliest')*/;
select count(*) from t6/*+ OPTIONS('read.start-commit'='earliest')*/;
Changelog 模式结果显示:
4.12 Insert Mode
基本特性
默认情况下,Hudi对插入模式采用小文件策略:MOR将增量记录追加到日志文件中,COW合并基本parquet文件(增量数据集将被重复数据删除)。这种策略会导致性能下降。
如果要禁止文件合并行为,可将write.insert.deduplicate设置为false,则跳过重复数据删除。
每次刷新行为直接写入一个新的 parquet文件(MOR表也直接写入parquet文件)。
可选配置参数
参数名称 是否必须 默认值 参数说明
write.insert.deduplicate false true “插入模式”默认启用重复数据删除功能。 关闭此选项后,每次刷新行为直接写入一个新的 parquet文件
5.Hudi on Hive(hive元数据同步)
Hudi源表对应一份HDFS数据,可以通过Spark,Flink 组件或者Hudi客户端将Hudi表的数据映射为Hive外部表,基于该外部表,Hive可以方便的进行实时视图,读优化视图以及增量视图的查询。对于presto 等查询引擎,需要依赖hive元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。
Hudi Catalog
从 0.12.0 开始支持,通过 catalog 可以管理 flink 创建的表,避免重复建表操作,另外 hms 模式的 catalog 支持自动补全 hive 同步参数。
DFS 模式 Catalog SQL样例:
DFS 模式 Catalog SQL样例:
CREATE CATALOG hoodie_catalog
WITH (
'type'='hudi',
'catalog.path' = '${catalog 的默认路径}',
'mode'='dfs'
);
Hms 模式 Catalog SQL 样例:
CREATE CATALOG hoodie_catalog
WITH (
'type'='hudi',
'catalog.path' = '${catalog 的默认路径}',
'hive.conf.dir' = '${hive-site.xml 所在的目录}',
'mode'='hms' -- 支持 'dfs' 模式通过文件系统管理表属性
);
名称 Required 默认值 说明
catalog.path true -- 默认的 catalog 根路径,用作表路径的自动推导,默认的表路径:${catalog.path}/${db_name}/${table_name}
default-database false default 默认的 database 名
hive.conf.dir false -- hive-site.xml 所在的目录,只在 hms 模式下生效
mode false dfs 支持 hms模式通过 hive 管理元数据
table.external false false 是否创建外部表,只在 hms 模式下生效
示例:
CREATE CATALOG myhive WITH (
'type'='hive',
'hive-conf-dir'='/export/server/hive/conf',
'hive-version'='3.1.2',
'hadoop-conf-dir'='/export/server/hadoop/etc/hadoop/'
);
USE CATALOG myhive;
使用dfs方式
(1)创建sql-client初始化sql文件
vim /opt/module/flink-1.13.6/conf/sql-client-init.sql
CREATE CATALOG hoodie_catalog
WITH (
'type'='hudi',
'catalog.path' = '/tmp/hudi_catalog',
'mode'='dfs'
);
USE CATALOG hoodie_catalog;
(2)指定sql-client启动时加载sql文件
hadoop fs -mkdir /tmp/hudi_catalog
bin/sql-client.sh embedded -i conf/sql-client-init.sql -s yarn-session
(3)建库建表插入
create database test;
use test;
create table t2(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20),
primary key (uuid) not enforced
)
with (
'connector' = 'hudi',
'path' = '/tmp/hudi_catalog/default/t2',
'table.type' = 'MERGE_ON_READ'
);
insert into t2 values('1','zs',18,TIMESTAMP '1970-01-01 00:00:01','a');
(4)退出sql-client,重新进入,表信息还在
use test;
show tables;
select * from t2;
5. Mysql-Flinkcdc-Hudi案例
开启服务
- 开启hdfs:
/export/server/hadoop/sbin/start-dfs.sh`
- 开启hive:
nohup /export/server/hive/bin/hive --service metastore &
nohup /export/server/hive/bin/hive --service hiveserver2 &
- 开启flink standalone:
cd /export/server/flink
./bin/start-cluster.sh
- 开启flink sql客户端:
/export/server/flink/bin/sql-client.sh embedded
flink sql客户端执行文章来源:https://www.toymoban.com/news/detail-431571.html
- 设置tableau模式:
SET sql-client.execution.result-mode = tableau;
- 设置checkpoint:
set execution.checkpointing.interval=30sec;
- 创建mysql映射表:
CREATE TABLE if not exists mysql_bxg_oe_course_type (
`id` INT,
`type_code` STRING,
`desc` STRING,
`creator` STRING,
`operator` STRING,
`create_time` TIMESTAMP(3),
`update_time` TIMESTAMP(3),
`delete_flag` BOOLEAN,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector'= 'mysql-cdc', -- 指定connector,这里填 mysql-cdc
'hostname'= '192.168.88.161', -- MySql server 的主机名或者 IP 地址
'port'= '3306', -- MySQL 服务的端口号
'username'= 'root', -- 连接 MySQL 数据库的用户名
'password'='123456', -- 连接 MySQL 数据库的密码
'server-time-zone'= 'Asia/Shanghai', -- 时区
'debezium.snapshot.mode'='initial', -- 启动模式,默认为initial
'database-name'= 'bxg', -- 需要监控的数据库名
'table-name'= 'oe_course_type' -- 需要监控的表名
);
- 创建hudi映射表:
CREATE TABLE if not exists hudi_bxg_oe_course_type (
`id` INT,
`type_code` STRING,
`desc` STRING,
`creator` STRING,
`operator` STRING,
`create_time` TIMESTAMP(3),
`update_time` TIMESTAMP(3),
`delete_flag` BOOLEAN,
`partition` STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path'= 'hdfs://192.168.88.161:8020/hudi/bxg_oe_course_type', -- 数据存储目录
'hoodie.datasource.write.recordkey.field'= 'id', -- 主键
'write.precombine.field'= 'update_time', -- 自动precombine的字段
'write.tasks'= '1',
'compaction.tasks'= '1',
'write.rate.limit'= '2000', -- 限速
'table.type'= 'MERGE_ON_READ', -- 默认COPY_ON_WRITE,可选MERGE_ON_READ
'compaction.async.enabled'= 'true', -- 是否开启异步压缩
'compaction.trigger.strategy'= 'num_commits', -- 按次数压缩
'compaction.delta_commits'= '1', -- 默认为5
'changelog.enabled'= 'true', -- 开启changelog变更
'read.tasks' = '1',
'read.streaming.enabled'= 'true', -- 开启流读
'read.streaming.check-interval'= '3', -- 检查间隔,默认60s
'hive_sync.enable'= 'true', -- 开启自动同步hive
'hive_sync.mode'= 'hms', -- 自动同步hive模式,默认jdbc模式
'hive_sync.metastore.uris'= 'thrift://192.168.88.161:9083', -- hive metastore地址
'hive_sync.table'= 'bxg_oe_course_type', -- hive 新建表名
'hive_sync.db'= 'bxg', -- hive 新建数据库名
'hive_sync.username'= '', -- HMS 用户名
'hive_sync.password'= '', -- HMS 密码
'hive_sync.support_timestamp'= 'true'-- 兼容hive timestamp类型
);
- 插入数据:
`INSERT INTO hudi_bxg_oe_course_type SELECT `id`,`type_code` ,`desc`,`creator` ,`operator`,`create_time` ,`update_time` ,`delete_flag`,DATE_FORMAT(`create_time`, 'yyyyMMdd') FROM mysql_bxg_oe_course_type;`
结果分析:
查看hive表,发现bxg数据库中多了bxg_oe_course_type_ro,bxg_oe_course_type_rt两张表。表中包括之前数据,另外增加几个与hudi有关的字段及数据。文章来源地址https://www.toymoban.com/news/detail-431571.html
- 对于mor类型的Hudi源表,如果表名为hudimor,映射为两张Hive外部表即为hudimor_ro(ro表)和hudimor_rt(rt表)。ro表是历史数据(compact策略触发后能查询到的数据),rt表是实时数据。
- rt表支持快照查询和增量查询,查询rt表将会查询表基本列数据和增量日志数据的合并视图,立马可以查询到修改后的数据。而ro表则只查询表中基本列数据并不会去查询增量日志里的数据。rt表采用HoodieParquetRealtimeInputFormat格式进行存储,ro表采用HoodieParquetInputFormat格式进行存储。
到了这里,关于hudi介绍和使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!