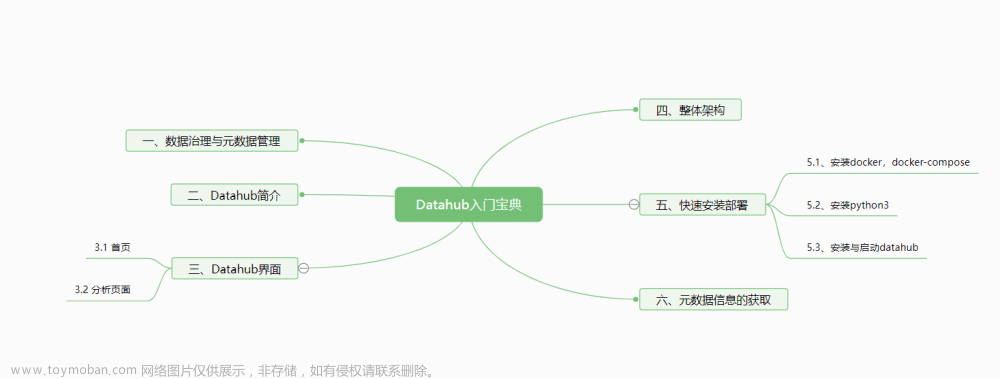
一、AllData数字化方案数据治理平台
AllData科学护城河:一种在数据驱动的科学和研究领域中,
保护和维护数据的竞争优势和独特性的解决方案。
AllData通过汇聚大数据与AI领域生态组件,提供自定义化数据中台。
包括大数据生态方案,人工智能生态方案,
大数据组件运维方案,大数据开发治理方案,
机器学习方案,大数据SQL开发ChatGPT方案,
数据集成方案,湖仓分析方案。文章来源地址https://www.toymoban.com/news/detail-431748.html
数据平台的数据治理:数据治理是一个大而全的治理体系。
需要数据质量管理、元数据管理、主数据管理、模型管理管理、数据价值管理、
数据共享管理和数据安全管理等等模块是一个活的有机体。
1、数据质量: 依托Griffin平台,为您提供全链路的数据质量方案,
包括数据探查、对比、质量监控、SQL扫描和智能报警等功能:
开源方案: Apache Griffin + ES + SparkSql
2、元数据: 描述数据的数据,对数据及信息资源的描述性信息,
例如字段元数据描述字段的类型、长度、默认值。
发布:指将某一元数据发布为数据资产的动作。
数据资产是指可以对外提供服务并且产生价值的数据。
表/字段血缘:即表/字段的来龙去脉,
主要包含表/字段的来源、加工方式、映射关系及数据出口。
血缘是元数据的一部分,有利于数据变更影响分析以及数据问题排查。
开源方案: Apache Atlas + ES + Hbase + JanusGraph + Hive + Kafka
3、数据标准: 参考阿里的DataWorks,
数据标准是用于描述公司层面需共同遵守的数据含义和业务规则,
它描述了公司层面对某个数据的共同理解,
这些理解一旦确定下来,就应作为企业层面的标准在企业内被共同遵守。
数据标准,也称数据元,由一组属性规定其定义、标识、表示和允许值的数据单元,
是不可再分的最小数据单元。您可以将数据标准关联到各个业务上的数据库中。
其中,标识符、数据类型、表示格式、值域是数据交换的基础,
它们用于描述表的字段元信息,规范字段所存储的数据信息。
暂无事实性标准的开源方案:Mysql + SpringBoot
4、数据服务:参考阿里的DataWorks,
数据服务旨在为企业搭建统一的数据服务总线,帮助企业统一管理对内对外的API服务。
数据服务为您提供快速将数据表生成API的能力,
同时支持您快速注册现有的API至数据服务平台,进行统一的管理和发布。
数据服务已经与API网关(API Gateway)连通,支持一键发布API服务至API网关。
数据服务与API网关为您提供了安全稳定、低成本、易上手的数据开放共享服务。
数据服务采用Serverless架构,
您只需要关注API本身的查询逻辑,无需关心运行环境等基础设施,
数据服务会为您准备好计算资源,并支持弹性扩展,零运维成本。
开源方案:Apache Kong + Mysql + Lua + Postgresql + ES
二、AllData数字化方案核心价值定位
在生产实践中,为了更好地实施数据中台提供数据服务,
总会需要将其与外部服务集成,例如代码仓库、指标监控页面、
实时日志记录或 HDFS/OSS 上的检查点/保存点文件夹等。
AllData作为一站式大数据开发与治理平台,
如果能够提供以扩展链接的形式集成这些服务的能力,
在统一的地方集中定义,并自动应用于每个数据开发服务,将为用户带来更多价值
三、AllData数字化方案混合数仓引擎
基于Kylin3.1.3 DataSourceSDK + Calcite进行开发
1、增加ClickHouseAdapter
2、基于Calcite进行语法词法解析
3、根据Calcite解析SQL进行规则路由
4、封装JDBC转发查询不同OLAP引擎
5、返回SQL查询结果
四、AllData社区与Dinky社区分享
Dlink为Apache Flink而生,让Flink SQL尽享丝般顺滑,
致力于实时计算平台的构建
Dinky项目:https://github.com/DataLinkDC/dlink
AllData项目:https://github.com/alldatacenter/alldata
感谢社区成员@yg9538的会议纪要
第一:如何激发社区对用户来参与到项目的建设,一起推动项目的发展?
第二:完成整个项目的基本功能路线,流程是如何的?
我首先回答第二个问题。
首先AllData用到的技术栈包括我们所设想的整个流程是非常全面丰富的。
但然,凡事都是有利有弊的,技术栈的全面会导致各个技术功能点实现复杂度增高。
2.1 最小MVP
对于第一个问题,其实跟第二个问题是非常有关系的。
当我们具备了一个可使用的一个MVP最小可行性产品时候,
用户将产品用在测试或者生产实践将会给项目带来极大的益处
最大的好处是用户将会主动参与到我们那个项目的推动中。
比如说项目的在实践中进行的测试和提出的ISSUE作为项目经验必不可少,
其次用户在实际生产中遇到的二开需求,
对于我们整个项目提升也是有极大的帮助。
2.2 门户与KM知识库
当然就是除了有一个最小可行性产品门户和知识库也必不可少,
门户可以对整个项目进行一个详细的介绍。
比如我们要进行部署的话我们可以进行搜索,百度上也会提供许多文档。
但是百度的文档质量参差不齐,非常影响用户的体验。
我看到AllData有提到三个概念我是非常赞同的:
重设计
轻编码
中度测试
对于社区来说,我们可以总结自己的经验形成文档放在社区中。
2.3 用户分类
然后第三点,因为项目前期用户是较少,在前期用户对项目的发展至关重要。
这就不仅需我们仔细的聆听用户的需求,用户的反馈,
还要积极的为用户来进行解答,一般用户会划分为两大类:
有完整的技术经验——较少数
无完整的技术经验——占多数
第一种用户是自身具备一定的技术栈,一定的能力。
第二种用户是作为项目经理或技术他引入该开源项目来作为解决方案的
门户网站和知识库至关重要,它可以帮助客户进行部署。
所以问题点就是如何教导用户会用我们的产品。
2.4 工作推动
然后,就是进行一个分工推这方面。
如果作为一个领导者要去领导我们的协作者去完成一件事情的时候,
首先要达到一个统一的共识才可以,然后如何如何来达到这个统一的共识呢
2.4.1 获得认可
首先就得需要认可你的方案,认可你的思路。
2.4.2 产品定位
就是说你不要让用户上生产的时候就把你所有的功能都要上去,
而是可以用你几块核心功能就可以完成一个产品。
2.5 技术选型
2.5.1 大数据平台选型
基于这些平台,你可以独立完整的跑起一个MVP。
这样不仅仅能享受到社区福利也可以获得用户的认可
2.5.2 MLOPS平台选型
2.5.3 CI/CD
CI/CD那一块我认为就比较独立了。这些也是有现成的项目,
然后我们要做的其实就是调研好现成的项目。然后把它集成进来。
2.6 需求场景
我个人对AllData的定位是一个把很多开源的项目平台统一管理、集成起来,
提供一个能力开放的平台
2.6.1 定义场景
一般离线开发都是需要开发需求。
2.7 其他要求
2.7.1 文档要求
第一,文档永远没有交流重要,文档的规范可以放松,但是交流是最主要的。
2.7.2 设计逻辑
第二就是设计。先是高层级设计,再是具体细节设计。
这具体如何实现呢?例如我们如何去把数据开发平台、调度平台、管理平台关联?
首先就需要把他们打通,作为一个底层Base先把他们真正的打通起来。
然后让他们可以再以流一个流程化的方式来跑起来。
建议总结:
压缩技术栈
理念转变为团队思想
多于其他社区沟通,达到互帮互助引流的效果
五、社区知识库与加入开源社区
【腾讯文档】AllData社区进群必读最全资料-最新
https://docs.qq.com/doc/DVHlkSEtvVXVCdEFo
文章来源:https://www.toymoban.com/news/detail-431748.html
到了这里,关于AllData一站式大数据平台【二】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!