MySQL数据库命令
一、数据库
1、创建数据库
create database 数据库名
2、查看数据库
show databases; 查看所有的数据库
show create database 数据库名; 查看指定数据库
3、删除数据库
drop database 数据库名;
4、切换数据库
use 数据库名;
5、查看正在使用的数据库
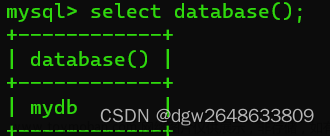
select database();
6、按指定码表创建数据库
CREATE DATABASE 数据库名 CHARACTER SET UTF8;
二、表
1、创建表
create table 表名(
字段名 类型(长度) 约束,
字段名 类型(长度) 约束
);
2、创建一个和之前一样但名字不一样的表
create table 新表名 like 旧的表名;
3、查看表
show tables; 查看所有表
4、查看表结构
desc 表名;
5、删除表
drop table 表名;
drop table 表名 if exists; 判断是否存在,存在则删
6、修改表名
rename table 旧名 to 新名;
7、修改表的字符集
alter table 表名 character set 字符集;
8、向表中添加字段
alter table 表名 add 字段名 字段类型(长度);
9、修改表中字段的类型或长度
alter table 表名 modify 字段名 字段类型(长度);
10、修改字段名
alter table 表名 change 旧字段名 新字段名 类型(长度);
11、删除字段
alter table 表名 drop 字段名;
12、查询表详细结构
show create table 表名称;
三、操作数据
1、写字段名的,插入全部数据
insert into 表名(字段1,字段2 ...) values(数据1,数据2 ...);
后面括号里的数据与第一个括号的字段顺序要一一对应
2、不写字段名的,插入全部数据(全列添加)
insert into 表名 values(数据1,数据2 ...)
括号内按创建表的列顺序添加数据
3、插入指定字段值
insert into 表名(字段名) values(数据);
4、修改(不带条件)
update 表名 set 字段名 = 值;
5、修改(带条件)
update 表名 set 字段名 = 值 where 字段名 = 值;
6、删除数据
delete from 表名; 一个个删除表中所有数据,效率慢,一般不用
truncate 表名; 直接删除整个表,并且再创建一个新表
7、删除一行数据
delete from 表名 where 条件;
四、查询数据
1、查询表中所有数据
select *from 表名;
2、查询表,只显示指定的字段
select 指定字段1,指定字段2,指定字段3... from 表名;
3、将所有的员工信息查询出来,并将列名改为中文显示
别名查询,使用关键子AS (不写AS也可)
SELECT
eid AS '编号',
ename AS '姓名',
sex AS '性别',
salary AS '薪资',
edate AS '入职日期',
edpt AS '部门'
FROM emp;
4、查一共有几个部门(指定字段名)(去重查询)
select distinct 字段名 from 表名;
5、查询所有的员工的工资+1000进行显示
select ename,salsy+1000 from emp;
6、查询含有“八”的所有员工信息
SELECT *FROM emp WHERE ename LIKE "%八%";
7、查询“沙”开头的所有员工信息
SELECT *FROM emp WHERE ename LIKE "沙%";
8、查询第三个字为“马”的所有员工信息
SELECT *FROM emp WHERE ename LIKE "__马%";
9、查询没有部门的员工信息
SELECT *FROM emp WHERE edpt IS NULL;
10、查询有部门的员工信息
SELECT *FROM emp WHERE edpt IS NOT NULL;
11、查询名字为孙悟空的员工信息
SELECT *FROM emp WHERE ename = '孙悟空';
12、查询薪资大于500的员工信息
SELECT *FROM emp WHERE salary > 500;
13、查询薪资不是5000的员工信息
SELECT *FROM emp WHERE salary != 5000;
SELECT *FROM emp WHERE salary <> 5000;
14、查询工资在200到500之间的
SELECT *FROM emp WHERE salary>=200 AND salary <= 500;
SELECT *FROM emp WHERE salary BETWEEN 200 AND 500;
15、指定的参数 not
SELECT *FROM emp WHERE salary NOT IN(200,300);
16、去重查询的命令
select distinct 字段1,字段2,… from 表名;
17、limit关键字(分页查询)
方言mysql
格式:
select 字段 from 表名 limit offset,length
offset :从哪开始 默认是0
length :要查询的条数
如需查询3条数据,需写三条语句,一个语句分一页
分页查询,每次显示2条数据
起始索引= (当前页-1) * 每页的条数
五、单表操作
5-1 排序
1、通过一个字段升序排序
select *from 表名 order by 字段名;
2、通过一个字段降序排序
select *from 表名 order by 字段名 desc;
3、如果薪资一样,按编号排
select *from 表名 order by 薪资 desc , 编号 desc;
5-2 聚合
格式:
select 聚合函数(字段名) from 表名
聚合函数:
sum、max、min、avg
如求平均值
select AVG(字段名) from 表名;
5-3 分组
1、格式
SELECT * FROM emp GROUP BY 字段 [having 条件]
只能显示集合中的第一条数据,因此单纯的使用分组查询是没有实际意义的
所以,经常使用聚合函数和分组结合使用
2、通过性别进行分组,求每组的平均薪资
select 性别 ,avg(薪资) from 表名 group by 性别;
3、查看所有的部门信息
select 部门 from 表名;
4、查询每个部门的平均薪资
select
部门,
avg(薪资)
from 表名 group by 部门;
5、查询每个部门的平均薪资,部门名称不能为null
select
部门,
avg(薪资)
from 表名 where 部门 is not null group by 部门;
6、查询平均薪资大于600的部门
select
部门,
avg(薪资)
from 表名 group by 部门 having avg(薪资) >600;
7、结论:
where : 分组前的过滤,进行条件判断,后面不能跟聚合函数
having : 分组后的过滤,进行条件判断,后面可以跟聚合函数
5-4 主键
1、第一种设置主键
在创建表的时候就设置
create table 表名(
sid int primary key,
sname varchar(10)
);
2、第二种设置主键
在创建表的最后一行设置主键
create table 表名(
sid int,
sname varchar(10),
primary key(sid)
);
3、第三种设置主键
在创建表之后再设置主键
通过向表添加字段的方式添加
create table 表名(
sid int,
sname varchar(10)
);
alter table 表名 add primary key(sid);
4、删除主键
alter table 表名 drop primary key;
5、主键特点:
不可重复、唯一、非空
6、
针对业务去设计主键,每张表都要设计一个主键id
主键没有实际的含义,给数据库和程序使用的,跟客户无关
主键没有意义没关系,只要保证不重复、非空就可以了
7、主键设置初始值自增(也是设置主键的时候的默认写法)
create table 表名(
sid int primary key auto_increment,
sname varchar(10)
);
8、设置主键从100开始自增
CREATE TABLE 表名(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10)
)AUTO_INCREMENT=100;
9、删除操作对主键的影响
delete : 对自增没有影响
truncate :恢复自增初始化,从1开始自增
5-5 唯一约束
1、格式
字段名 字段类型 unique;
5-6 非空约束
1、含义
设置的字段不能为空
2、格式
字段名 字段类型 not bull;
5-7 事物
1、什么是事物
是由一条或者多条sql语句组成
要么全部成功,要么全部失败(执行回滚)
2、回滚
在事务运行的过程中发生了某个故障,事务便不再继续执行下去,
系统对事物中数据所有已完成的操作全部撤销,滚回到开始时的状态
3、转钱案例
先初始化一个表:
CREATE TABLE zh(
id int primary key auto_increment,
sname VARCHAR(20),
money DOUBLE
);
INSERT INTO zh VALUES(NULL,'小明',1000);
INSERT INTO zh VALUES(NULL,'小王',1000);
开启事务:
start transaction;
转钱操作:
UPDATE zh SET money = money - 500 WHERE id = 1;
(系统崩了)
UPDATE zh SET money = money + 500 WHERE id = 2;
回滚:
ROLLBACK;
提交:
commit;
4、查看当前的提交方式
show variables like 'autocommit';
on :自动提交
off :手动提交
5、取消自动提交
SET @@autocommit = off;
5-8 事务四大特性
| 特性 | 含义 |
|---|---|
| 原子性 | 每个事务都是一个整体,不可再拆分。事务中所有的sql要么全部执行成功,要么都失败 |
| 一致性 | 事务在执行前数据库的状态与执行后数据库的状态保持一致; |
| 隔离性 | 事务和事务之间不应该相互影响,执行时保持隔离状态 |
| 持久性 | 一旦事务执行成功,对数据库修改是永久的。就算你关机,数据也会保存下来 |
5-9 MySQL的隔离级别
1、数据的并发访问
一个数据库可能有多个客户端在访问,这些客户端都可以并发方式访问数据库,数据库的相同数据可能被多个事务同时访问,如果我们不对其采用隔离,就会发生各种问题,破坏数据的完整性
2、
| 并发访问引发的问题 | 含义 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务的尚未提交的数据 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致 |
| 幻读 | 一个事务中,某一次的select操作结果所表现得数据状态,无法支撑后续的因为误操作,查询到的数据不准确,导致幻读 |
3、四种隔离级别
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 不能 | 不能 | 不能 |
| 2 | 读已提交 | read committed | 能 | 不能 | 不能 |
| 3 | 可重复读 | repeatable read | 能 | 能 | 不能 |
| 4 | 串行化 | serializable | 能 | 能 | 能 |
4、查看隔离级别文章来源:https://www.toymoban.com/news/detail-431882.html
select @@transaction_isolation;
5、设置隔离级别文章来源地址https://www.toymoban.com/news/detail-431882.html
set global transaction isolation level 四大隔离级别之一;
六、多表操作
6-1 外键约束
外键约束是指从表和主表的主键对应的那个字段(在从表中)
主从关系:
主表:主键id所在的表,约束别人的表
从表:外键所在的表,被约束的表
添加外键约束:
对已有表添加:
alter table 从表 add[两张表关系描述] foreign key(外键id) references 主表(主键id);
在创建表的时候添加:
在表的最后一行加一句:
foreign key(外键id) references 主表(主键id);
删除外键:
alter table 从表 drop foreign key 外键约束名称;
6-2 级联删除
含义:实现在删除主表数据的时候,把从表的数据也删除掉
实现:
在建表的添加外键的时候,添加一句:
on delete cascade;
6-3 多表设计
| 关系 | 说明 |
|---|---|
| 一对一 | 身份证: person 身份证 主从关系无所谓 |
| 一对多 | 部门 : 一个部门 多个员工 字段多的(数据多了)当从表 字段少的主表 |
| 多对多 | 课程 :中间表当主表 其他多表是从表 |
6-4多表查询
笛卡尔积:
两个集合内所有元素都各自相乘,
可以通过加where语句用外键消除
内连接查询:
隐式内连接;
显式内连接
概述:通过指定的条件去匹配两张表,匹配成功就显示,匹配失败就不显示
如何匹配: 从表的外键 = 主表的主键
隐式内连接:
from后面直接写多个表名,并且使用where连接条件
where条件进行无用数据的过滤
格式:
select 字段 from 左表,右表 where 连接条件;
显式内连接:
格式:
select 字段 from 左表[inner] join 右表 on 过滤条件;
外连接查询:
左外连接;
右外连接
左外连接:
以左表为基准,匹配右表中的数据,如果匹配成功就显示
如果匹配不到,左表中的数据正常显示
格式:
select 字段名 from 左表 left[outer] join 右表 on 过滤条件;
右外连接:
以右表为基准,匹配左右表中的数据,如果匹配成功就显示
如果匹配不到,右表中的数据正常显示
格式:
select 字段名 from 右表 left[outer] join 左表 on 过滤条件;
子查询:
一条select查询语句的结果,作为另外一条select语句的一部分
特点:
子查询必须在小括号中
子查询一般作为父查询的条件去使用
分类:
where型子查询
from型子查询
exists型子查询
where型子查询:
将子查询的结果,作为父查询的比较条件
select 字段名称 from 表名 where 字段 = (子查询)
from型子查询:
将子查询的结果,作为一张表,提供给父层查询使用
select 字段名称 from 表名 (子查询) 别名 where 条件
exists型子查询:
子查询的结果是单列多行的,类似于一个数组,给父层使用
select 字段名称 from 表名 别名 where 字段 in (子查询)
总结:
子查询如果查询出的是一个字段(单列),那就再where后面作为条件使用
子查询如果查询出的是一个表(多列),就当一张表去操作(起别名)
到了这里,关于MySQL数据库命令的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!