一、ElasticSearch
1 基本概念
全文检索工具:快速储存、搜索和分析海量数据。
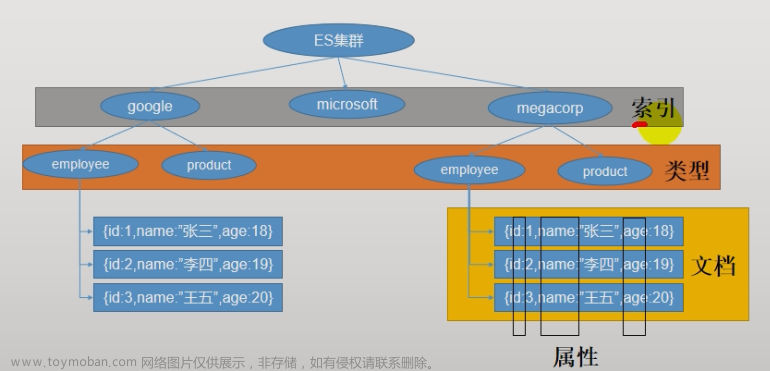
- Index (索引) → Mysql的库
- 动词,相当于MySQL中的insert;
- 名词,相当于MySQL中的Database。
- Type (类型) → Mysql的表(过时)
- 在Index中,可以定义一个或多个类型。类似于MySQL中的Table;每一种类型的数据放在一起。
- Document (文档) → Mysql的记录
- 保存在某个Index下,某种Type的一个数据 (Document),文档是JSON格式的,Document就像是MySQL中的某个Table里面的内容。
- 倒排索引
-
词 记录 红海 1,2,3,4,5 行动 1,2,3 探索 2,5 特别 3,5 记录篇 4 特工 5 分词:将整句分拆为单词
保存的记录
1 - 红海行动
2 - 探索红海行动
3 - 红海特别行动
4 - 红海纪录篇
5 - 特工红海特别探索检索
红海特工行动?
红海行动?相关性得分
比如搜索“红海特别行动”,找到词“红海”,“特工”和“行动”,共涉及到记录1, 2, 3, 4, 5。
对于记录1和5,都命中了两个词。但是记录1只拆分出了2个词,记录5拆分出了4个词,所以记录1的相关性得分会更高。
2 安装
docker pull elasticsearch:7.4.2 # 存储和检索数据
docker pull kibana:7.4.2 # 可视化检索数据
mkdir -p /mydata/elasticsearch/config # 用于挂载
mkdir -p /mydata/elasticsearch/data # 用于挂载
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml # 允许任何IP访问
2.1 安装ElasticSearch
docker run命令:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ # 9200-API端口 9300-集群通信端口
-e "discovery.type=single-node" \ # 指定参数
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \ # 指定参数
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2 # 指定后台启动镜像
下面供复制使用:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx128m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
问题1 运行后
docker ps没有运行,使用docker logs elasticsearch查看报错原因如下:... "org.elasticsearch.bootstrap.StartupException: ElasticsearchException[failed to bind service]; nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes];" ... "Caused by: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes"解决 宿主机挂载目录权限问题,给要被挂载的目录所有用户的读写权限:
chmod -R 777 /mydata-R是给目录下所有文件赋予权限
2.2 安装Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://172.16.212.10:9200 -p 5601:5601 -d kibana:7.4.2
3 初步检索
3.1 _cat 查看ES的节点信息
| 请求 | 说明 |
|---|---|
| GET /_cat/nodes | 查看所有节点 |
| GET /_cat/health | 查看ES健康状况 |
| GET /_cat/master | 查看主节点 |
| GET /_cat/indices | 查看所有索引 → show databases; |
3.2 索引一个文档
_ 开头的是元数据。现在type已不推荐使用,使用 _doc
| 请求 | 说明 |
|---|---|
PUT customer/external/1 body {“name”: “John”} |
在customer索引下的external类型下保存1号数据为请求体中的JSON内容。如果之前存在对应ID的数据,则会进行更新;否则新增。必须携带ID。 |
POST customer/external/1body {“name”: “John”} |
同上,但是可以不带ID,表示新增。 |
GET customer/external/1 |
查询一条数据。返回信息中:_seq_no: 6, 并发控制字段,每次更新就会+1,用来做乐观锁_primary_term: 1, 同上,主分片重新分配、重启就会变化更新时携带下面的参数: ?if_seq_no=0&if_primary_term=1,比如只想修改序列号为1时的数据,别人如果中途修改过就不再修改,返回409错误并提供新的版本号。 |
POST customer/external/1/_updatebody {“doc”: {“name”: “John”}} |
更新文档。会对比原来数据,如果更新前后没有变化,那么序列号和版本都不会增加。前面两种更新都会修改。 |
DELETE customer/external/1 |
删除一条数据。 |
DELETE customer |
删除索引。ES不支持删除类型。 |
# 在Kibana中执行POST customer/external/_bulk{“index”:{“_id”:“1”}} {“name”:{“name”:“John”}} {“index”:{“_id”:“2”}} {“name”:{“name”:“Jack”}} |
批量保存。上一条失败不会影响下一条。语法格式: {action: {metadata}} {request body} actions: delete create title index
|
4 进阶检索
4.1 SearchAPI
select * from bank order by account_number asc
GET bank/_search?q=*&sort=account_number:asc
4.2 QueryDSL
4.2.1 基本查询
select balance, firstname from bank order by account_number asc limit 0, 5
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [{
"account_number": "asc"
},
{
"balance": "desc"
}],
"from": 0,
"size": 5,
"_source": ["balance", "firstname"]
}
- match
select * from bank where balance = 16418GET bank/_search { "query": { "match": { "balance": 16418 } } } - match_phrase
select * from bank where address like '%mill lane%'
(MySQL和ES都忽略大小写)GET bank/_search { "query": { "match_phrase": { "address": "mill lane" } } } - multi_match
select * from bank where address like '%mill%' or city like '%mill%' or address like '%movico%' or city like '%movico%'GET bank/_search { "query": { "multi_match": { "query": "mill movico", "fields": ["address", "city"] } } } - bool
可以使用mustmust notshould,均为字面意思,符合查询值的会贡献相关性得分。
也可以使用filter进行过滤,但不会计算相关性得分。GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "F" } } ]}}} - term
精确值查询。但是查询text字段由于存在分词分析的原因,会查询不到,还是需要使用match。
实践GET bank/_search { "query": { "term": { "age": "28" } } }
全文检索字段使用match,其他非text字段匹配用term。
4.2.2 聚合
- terms聚合
- 搜索address中包含mill的所有人的年龄分布以及平均年龄
-
select * from bank+select age, count(age) from age group by age
GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 # 只看10条聚合结果 } } }, "size": 0 # 不看具体记录只看聚合结果 } -
- 对text类型字段做聚合需要添加后缀
.keyword。 - 嵌套聚合:
with (select age, count(age) from bank group by age) as t1select avg(balance) from bank, t1 on bank.age = t1.age group by balanceGET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 # 只看10条聚合结果 }, "aggs": { "balanceAvg": { "avg": { "field": "balance" } } } } }, "size": 0 # 不看具体记录只看聚合结果 }
- avg聚合
- 求平均值
select avg(age) from bank
GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAvg": { "avg": { "field": "age", } } }, "size": 0 # 不看具体记录只看聚合结果 }
其他聚合类型参考官方文档。
4.3 Mapping
- 指定字段类型。
PUT /my_index
{
"mappings": {
"properties": {
"age": {"type": "integer"},
"email": {"type": "keyword"},
"name": {"type": "text"} # text类型会进行分词分析
}
}
}
- 给已有映射添加字段
employee-id:
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false # 控制这个字段是否可以被查询(false为冗余字段)
}
}
}
- 对于已存在的索引,不能进行更新。只能创建新的索引,进行数据迁移。
POST _reindex
{
"source": {
"index": "bank",
"type": "account" # 过时,迁移后默认变成_doc
},
"dest": {
"index": "newbank"
}
}
4.4 分词
默认按空格进行分词,忽略句尾句号。但是这样无法对中文进行分词(被拆分为单字)。
POST _analyze
{
"analyzer": "standard",
"text": "中文之间是没有空格的"
}
在GitHub上下载对应ES版本的ik分词器https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2,使用wget下载到挂载插件目录下
cd /mydata/elasticsearch/plugins
wget https://www.notion.so/1-ElasticSearch-a3b1bbe49f404ee8898d1b99b76d812a#061e5af6f9f940509ca3e89197754abc
unzip -d ik elasticsearch-analysis-ik-7.4.2.zip
rm elasticsearch-analysis-ik-7.4.2.zip
然后进入docker容器使用elasticsearch-plugin list查看安装好的插件。
使用ik分词器
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
我们经常需要自定义词库,可以将自定义词库部署到nginx让ES来访问。
附录——调整ES占用内存最大为512M
删除原来的容器,新建一个。
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
附录——安装Nginx
- 随便启动一个nginx实例,为了复制其中配置文件
docker run -p 80:80 --name nginx -d nginx:1.10- 将容器内的配置文件拷贝到当前目录
docker container cp nginx:/etc/nginx .- 修改文件名,并移动到/mydata/nginx下
mv nginx confmkdir /mydata/nginxmv conf /mydata/nginx- 终止原容器并删除
docker stop nginxdocker rm nginx- 创建新的nginx
docker run -p 80:80 --name nginx -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10Nginx可以直接通过路径访问html目录下的文件。
在nginx的html目录下创建一个txt文件存储自定义词库
cd /mydata/nginx/html
mkdir es
cd es
vim segmentation.txt # 词汇换行存储
然后修改ES中ik插件的配置文件
cd /mydata/elasticsearch/plugins/ik/config
vim IKAnalyzer.cfg.xml
# 将下面这条配置取消注释,并配置为自己的自定义词库文件
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://172.16.212.10/es/segmentation.txt</entry>
重启ES就可以生效了docker restart elasticsearch
5 整合Java
使用官方提供的Java High Level REST Client
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-getting-started-maven.html
Maven导入:
<properties>
<java.version>1.8</java.version>
<!-- springdata对es版本做了管理,在这里覆盖掉 -->
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
问题1 按照视频中导入上方陪配置后报错
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'configurationPropertiesBeans' defined in class path resource解决 nacos和springboot版本冲突,引入依赖管理:
<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
@Test
void indexData() throws IOException {
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");
// indexRequest.source("userName", "zhangsan", "age", 18, "gender", "男");
User user = new User();
String jsonStr = JSON.toJSONString(user);
indexRequest.source(jsonStr, XContentType.JSON);
IndexResponse index = client.index(indexRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(index);
}
@Test
void searchData() throws IOException {
SearchRequest searchRequest = new SearchRequest();
// 指定在哪里检索
searchRequest.indices("bank");
// 指定DSL,检索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造检索条件
sourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
sourceBuilder.aggregation(AggregationBuilders.terms("ageAgg").field("age").size(10));
sourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));
searchRequest.source(sourceBuilder);
// 执行检索
SearchResponse response = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 分析结果
SearchHits hits = response.getHits();
SearchHit[] hits1 = hits.getHits();
for (SearchHit hit : hits) {
String hitStr = hit.getSourceAsString();
System.out.println("hit: " + hitStr);
}
Aggregations aggregations = response.getAggregations();
Terms ageAgg = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg.getBuckets()) {
String keyStr = bucket.getKeyAsString();
System.out.println("age: " + keyStr);
}
Avg balanceAvg = aggregations.get("balanceAvg");
System.out.println("balance avg: " + balanceAvg.getValue());
}
关于nested字段类型
二、Nginx
让Nginx帮我们进行反向代理,所有来自gulimall.com的请求,都转到商品服务。
nginx.conf
|— 全局块 配置影响nginx全局的指令。如:用户组,nginx进程pid存放路径,日志存放路径。配置文件引入,允许生成worker process数等
|— events块 配置影响nginx服务器或与用户的网络连接。如:每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等
|— http块 可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置,如文件引入,mime-type定义,日志自定义,是否使用sendile传掩文件,连接超时时间,单连接请求数等
|— http全局块 如upstream,错误页面,连接超时等
|— server块 配置虚拟主机的相关参数。—个http中可以有多个server
|— location 配置请求的路由,以及各种页面的处理情况
|— location
|— ...
- 在nginx.conf总配置中,有一条
include /etc/nginx/conf.d/*.conf;表示会读取这conf.d目录下所有的conf配置文件 - 在conf.d下创建一个gulimall.conf来配置代理转发,修改其中的server_name为gulimall.com,表示将所有请求头中host为gulimall.com的进行监听
- 再修改location中的内容配置代理路径
listen 80; server_name gulimall.com; #charset koi8-r; #access_log /var/log/nginx/log/host.access.log main; location / { proxy_pass http://172.16.212.1:10000; }
缺点 如果后期微服务实例增多,需要再进入配置文件进行修改。
解决方式 给Nginx的上游服务器配置为网关,将所有匹配请求转发到网关,由网关再进行转发。
- 修改nginx.conf,添加上游服务器配置:
# 配置上游服务器 upstream gulimall { server 172.16.212.1:88; # 这个是网关URL } - 再在gulimall.conf中将proxy_pass转发目的地址改为gulimall
注意 Nginx代理给网关的时候,会丢失请求头的host信息
解决方式 配置proxy_set_header Host $hostlocation / { proxy_set_header Host $host; # 添加header Host,内容为原来的host内容 proxy_pass http://gulimall; } - 在网关服务的application.yaml中添加域名转发配置:
- id: host_route uri: lb://product predicates: - Host=**.gulimall.com
动静分离
将静态资源如js, css和图片放到Nginx来处理,减轻Tomcat的负担。
- 首先将所有的静态资源(index目录)拷贝到nginx目录中:
/mydata/nginx/html/static - 修改gulimall.conf配置,添加static访问路径直接访问nginx目录中内容的配置:
location /static/ { root /usr/share/nginx/html; }
三、压力测试
1 性能指标
- 响应时间 (Response Time: ST)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。 - HPS(Hits Per Second):每秒点击次数,单位是次秘。
- TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
- QPS(Query per Second):系統每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么TPS=QPS=HPS,一般情记下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。 - 无论TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
- 金融行业:1000TPS~50000TPS,不包括互联网化的活动
- 保险行业:100TPS~100000TPS,不包括互联网化的活动
- 制造行业:10TPS~5000TPS
- 互联网电子商务:10000TPS~1000000TPS
- 互联网中型网站:1000TPS~5000OTPS
- 互联网小型网站:500TPS~10000TPS
- 最大响应时间(Max Response Time):指用户发出请求或者指令到系统做出反应(响应)的最大时间。
- 最少响应时间(Minimum Response Time):指用户发出请求或者指令到系统作出反应(响应)的最少时间。
- 90%响应时间(90% Response Time):是指所有用户的响应时间进行排序,第90%的响应时间。
- 从外部看,性能测试主要关注如下三个指标
- 吞吐量:每秒钟系统能够处理的请求数、任务数
- 响应时间:服务处理一个请求或一个任务的耗时
- 错误率:一批请求种结果出错的请求所占比例
2 JMeter
brew install jmeter
-
在Options中可以将语言设置为简体中文。
-
添加测试配置:

线程数来模拟用户数量Ramp-Up设置执行这些请求的时间,这里为200次循环次数重复多少次 -
HTTP请求配置中:

影响性能考虑点数据库、应用程序、中间件(Tomcat、Nginx)、网络和操作系统等方面
首先考虑自己的应用属于CPU密集型还是IO密集型
3 jvisualvm(VisualVM)
升级版的jconsole
问题1
在终端中执行jvisualvm后报错如下:The operation couldn’t be completed. Unable to locate a Java Runtime that supports jvisualvm. Please visit http://www.java.com for information on installing Java.并且环境变量中已有$JAVA_HOME
解决
高版本JDK不再自带jvisualvm。从官网 https://visualvm.github.io/download.html 下载VisualVM使用。下载后打开又报错需要JDK来运行而不是JRE,修改程序目录下
/etc/visualvm.conf添加javahome的配置:
visualvm_jdkhome="/Library/Java/JavaVirtualMachines/jdk1.8.0_311.jdk/Contents/Home”插件中心不需要修改,是用默认的就可以安装。按照JDK修改后出现安装插件缺失依赖的问题。
VisualVM中可以看到的线程状态
| 运行Running | 正在运行的 |
|---|---|
| 休眠Sleeping | sleep |
| 等待Wait | wait |
| 驻留Park | 线程池里面的空闲线程 |
| 监视Monitor | 阻塞的线程,正在等待锁 |
4 压力测试实验
- 对于nginx测试,可以使用
docker stats查看容器的CPU和内存占用 - 对于网关测试,直接发请求到localhost:88,忽略404
| 压测内容 | 压测线程数 | 吞吐量/s (耗时原因) | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 5165.8 | 13 | 52 |
| Gateway | 50 | 20500.2 | 4 | 16 |
| 简单服务 | 50 | 24898.7 | 3 | 5 |
| 首级一级菜单渲染 | 50 | 634.9 (db, thymeleaf) | 119 | 200 |
| 首级渲染(开缓存) | 50 | 761.9 | 94 | 151 |
| 首级渲染(数据库加索引,关日志) | 50 | 1856.6 | 44 | 81 |
| 三级分类数据获取 | 50 | 7.7 (db) | 6680 | 7625 |
| 三级分类数据获取(数据库加索引) | 50 | 13.7 | 4223 | 4910 |
| 三级分类数据获取(关日志) | 50 | 23.7 | 2670 | 2802 |
| 三级分类数据获取(优化业务减少DB查询次数) | 50 | 126.8 | 338 | 599 |
| 三级分类数据获取(使用Redis缓存) | 50 | 511.3 | 124 | 254 |
| 首页全量数据获取 | 50 | 360.4 (静态资源) | 0 | 701 |
| Nginx+Gateway | ||||
| Gateway+简单服务 | 50 | 7267.1 | 12 | 49 |
| 全链路 | 50 | 354.9 | 40 | 61 |
结论
- 中间件越多,性能损失越大,大多都损失在网络交互了
- 业务
- DB(MySQL优化)
- 模版的渲染速度(缓存)
- 静态资源
- Nginx
- 以后将所有项目的静态资源都应该放在Nginx里面
- 规则:/static/**所有请求都由Nginx直接返回
四、缓存
1 缓存使用
为了系统性能的提升,我们一般都会将部分的数据放入缓存中,加速访问。而DB承担数据落盘工作。
1.1 哪些数据适合放到缓存中?
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
举例
电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据更新频率来定),后台如果发布一个商品,买家需要5分钟才能看到新的商品一般还是可以接受的。
1.2 整合Redis
- 引入
spring-boot-data-redis-starter - 简单配置redis的host等信息
spring: redis: host: 172.16.212.10 port: 6379 - 使用SpringBoot自动配置好的StringRedisTemplate来操作Redis
Redis客户端可能会出现堆外内存溢出OutOfDirectMemoryError问题的原因
- SpringBoot2.0以后默认使用lettuce作为操作Redis的客户端,它使用netty进行网络通信
- lettuce的bug导致堆外内存溢出
在服务中设置了-Xmx300m最大堆内存,如果netty没有指定堆外内存,默认使用这个配置
解决方案
首先,不能使用 -Dio.netty.maxDirectMemory 去调大堆外内存
- 升级lettuce客户端
- 切换使用Jedis,修改POM文件如下:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> </dependency>
lettuce 和 jedis是什么关系
lettuce和Jedis都是操作Redis的底层客户端,Spring再次封装成RedisTemplate,同时引入了两者可以根据需要选用
2 缓存失效问题
2.1 缓存穿透
(查询不存在数据)
出现原因
查询一个一定不存在的数据,由于缓存没命中,去查数据库,数据库也不存在这条记录,不会写入缓存,之后再请求这个不存在数据都会到数据库去查询。利用不存在的数据进行攻击,数据库瞬时压力增大,导致崩溃
解决
null结果缓存,并加入短暂过期时间
2.2 缓存雪崩
(大面积key同时失效)
出现原因
设置的key采用了相同的过期时间,导致某一时刻同时失效,请求全部转发到数据库,数据库瞬时压力过重雪崩
解决
原有的失效时间基础上增就一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
2.3 缓存击穿
(某一个高频热点key失效)
出现原因
对于一些设置了过期时间的key,可能会在某些时间点被超高并发访问,是一种热点数据。如果这个key再大量请求同时进来之前正好失效,所有查询进入到数据库,数据库崩溃
解决
加锁:大量并发只让一个人去查,其他人等待。查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去数据库
3 缓存数据一致性
3.1 双写模式
数据更新时同时修改数据库和缓存。
数据更新 → 写数据库 → 写缓存
读到的最新数据有延迟:最终一致性。
脏数据问题
由于卡顿等原因,导致写缓存2在最前,写缓存1在后面就出现了不一致。
这是暂时的脏数据问题,但是在数据稳定,缓存过期以后,又能得到最新的正确数据。
3.2 失效模式
数据更新时更新数据库,删掉缓存中的旧数据。数据更新 → 写数据库 → 删缓存
问题
3.3 小结
- 无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略)。
- 总结
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
3.4 解决
使用Canal更新缓存
)
使用Canal解决数据异构问题
我们系统的一致性解决方案
- 缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
- 读写数据的时候,加上分布式的读写锁
4 SpringCache
4.1 配置
- 首先引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency> - 写配置
- 自动配置了哪些
CacheAutoConfiguration会导入RedisCacheConfiguration
自动配好了缓存管理器RedisCacheManager - 配置使用redis作为缓存
spring: cache: type: redis - 测试使用缓存
在要缓存结果的方法上面添加相应的注解就可以实现@Cacheable触发将数据保存到缓存的操作@CacheEvict触发将数据从缓存删除的操作@CachePut不影响方法执行更新缓存@Caching组合以上多个操作@CacheConfig在类级别共享缓存的相同配置@EnableCaching开启缓存功能,能够扫描到这个注解就能生效
- 自动配置了哪些
4.2 @Cacheable
默认行为
- 如果缓存存在,方法不用调用
- key默认自动生成:
缓存名字::SimpleKey []
- 缓存的value的值,默认使用jdk序列化机制,将序列化后的数据存到Redis
自定义
- 指定生成的缓存使用的key:key属性指定,接收一个SpEL
// key识别为表达式,字符串注意加单引号 @Cacheable(value = {"category"}, key = "'level1Categories'") // 使用方法名作为key @Cacheable(value = {"category"}, key = "#root.method.name") - 指定缓存的数据的存活时间:在application.yaml中配置
spring: cache: type: redis redis: time-to-live: 3600000 #一小时 - 将数据保存为Json格式
@Configuration @EnableCaching // 视频中在这启用cache有关的配置类,在容器中注入CacheProperties // 实测不用,因为原来也会注入到容器中 // @EnableConfigurationProperties(CacheProperties.class) public class MyCacheConfig { @Bean public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())); config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericFastJsonRedisSerializer())); CacheProperties.Redis redisProperties = cacheProperties.getRedis(); // 将配置文件中的所有配置都生效(因为如果使用自己的配置,在org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中读取配置文件设置的config就会被取代,所以在这里重新执行读取配置的操作) if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive()); } if (redisProperties.getKeyPrefix() != null) { config = config.prefixCacheNameWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) { config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) { config = config.disableKeyPrefix(); } return config; } }
原理CacheAutoConfiguration
→ RedisCacheConfiguration
→ 自动配置了 RedisCacheManager
→ 初始化所有的缓存
→ 每个缓存决定是用什么配置
→ 如果 redisCacheConfiguration 有就用已有的,没有就使用默认配置
→ 想改缓存的配置,只需要给容器中放一个 RedisCacheConfiguration 即可
→ 就会应用到当前 RedisCacheManager 管理的所有缓存分区中
其他的配置
spring:
cache:
type: redis
redis:
time-to-live: 3600000
# 如果指定了前缀,就用我们指定的前缀加上缓存名字作为前缀(视频中的版本为替换掉缓存名字)
key-prefix: cache_
use-key-prefix: true
# 是否缓存空值,防止缓存穿透
cache-null-values: true
4.3 @CacheEvict
可以用来实现失效模式。
在更新方法上添加这个注解,调用时就会删除掉指定的缓存。
@Override
@Transactional
// 一定要记得加单引号
@CacheEvict(value = "category", key = "'getLevel1Categories'")
public void updateCascade(CategoryEntity category) ...
批量删除
同一个注解不能重复添加,想要批量删除可以使用 @Caching
@Caching(evict = {
@CacheEvict(value = "category", key = "'getLevel1Categories'"),
@CacheEvict(value = "category", key = "'getCatalogJson'")
})
或者
// 这样会删除category分区下的所有key
@Caching(value = "category", allEntries = true)
实践
存储同一类型的数据,都可以指定成同一个分区。分区名默认就是缓存的前缀。
4.4 @CachePut
可以用来实现双写模式,方法执行后会将结果放入缓存,方法需要有返回值。
4.5 不足
- 读模式:
缓存问题 描述 通用解决 SpringCache解决 缓存穿透 查询一个null数据 缓存空数据 配置文件中设置缓存空数据 缓存击穿 大量并发进来同时查询一个正好过期的数据 加锁 在 @Cacheable 参数中添加 sync = true 缓存雪崩 大量的key同时过期 加随机时间 配置文件中设置过期时间 - 写模式:
- 读写加锁
- 引入Canal,感知到MySQL的更新去更新缓存
- 读多写多,直接去数据库查询就行
总结
- 常规数据(读多写少,即时性、一致性要求不高的数据),完全可以使用SpringCache
写模式(只要缓存的数据有过期时间就足够了) - 特殊数据:特殊设计
五、分布式锁
本地锁如synchronized和ReentrantLock不适用于分布式微服务的情况,所以要引入分布式锁。
1 Redis实现
private Map<String, List<Catalog2Vo>> getCatalogJsonWithRedisLock() {
// 获取UUID用于删除锁时的验证
String uuid = UUID.randomUUID().toString();
while (true) {
// 加锁(要设定一个锁的有效时间,防止设置锁所在的机器断电不能释放锁)
Boolean locked = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
// 判断是否加锁成功
if (Boolean.TRUE.equals(locked)) {
try {
// 加锁成功
} finally {
// lua脚本解锁
String script = "if redis.call(\"get\", KEYS[1]) == ARGV[1]" +
"\nthen" +
"\n return redis.call(\"del\", KEYS[1])" +
"\nelse" +
"\n return 0" +
"\nend";
redisTemplate.execute(new DefaultRedisScript<>(script, Integer.class), Collections.singletonList("lock"), uuid);
}
}
}
}
使用lua脚本保证 【获取UUID和删除锁】 操作原子性的意义
为了避免出现这样的情况
2 Redisson实现
2.1 配置与使用
- 首先引入依赖:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.12.0</version> </dependency> - 然后配置Bean:
@Configuration public class RedissonConfig { @Bean(destroyMethod = "shutdown") public RedissonClient redisson() { // 1. 创建配置 Config config = new Config(); config.useSingleServer().setAddress("redis://172.16.212.10:6379"); // 2. 根据Config创建出RedissonClient实例 return Redisson.create(config); } }
2.2 加解锁操作
@ResponseBody
@GetMapping("/hello")
public String hello() {
// 1. 获取一把锁,只要锁的名字一样,就是同一把锁
RLock lock = redisson.getLock("my-lock");
// 2. 加锁
lock.lock();
或者lock.lock(10, TimeUnit.SECONDS); // 10s自动解锁,但是一定要大于业务的执行时间
// 1) 锁的自动续期,如果业务超长,运行期间自动给锁续到30s。不用担心业务时间长,锁自动过期被删掉
// 2) 加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除
try {
Thread.sleep(30000);
} catch (InterruptedException ignored) {
} finally {
lock.unlock();
}
return "hello";
}
lock.lock()与自动续期
- 如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时就是我们指定的时间
- 如果我们未指定锁的超时时间,就使用
30 * 1000(LockWatchdogTimeout看门狗的默认时间)。
只要占锁成功,就会启动一个定时任务(重新给锁设置过期时间,新的过期时间就是看门狗的默认时间),定时任务会每隔LockWatchdogTimeout / 3(10s)重新执行一遍续期 - 在锁已经设置的情况下,另一个尝试获取锁的线程会在
tryAquire方法得到当前被占用锁的剩余有效时间ttl,然后通过future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS)阻塞ttl这么长的时间,之后会重新尝试获取锁;如果ttl为null说明获取到了锁就不需要阻塞了 - 在
RedissonLock的unlockAsync方法中,调用了cancelExpirationRenewal(threadId)来结束续期
最佳实战
建议使用 lock.lock(10, TimeUnit.SECONDS) 省掉了整个续期操作。设置一个较大的过期时间比如30s,即使是业务超时了也说明这个业务出现问题了。
问题
使用Redisson分布式锁时出现这个报错:
... Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [org.redisson.api.RedissonClient] ... Caused by: org.redisson.client.RedisConnectionException: Unable to init enough connections amount! Only 10 of 24 were initialized. ...解决
最低连接数要求过高,在Redisson配置类中添加
setConnectionMinimumIdleSize(1)(数值根据情况设置)@Bean(destroyMethod = "shutdown") public RedissonClient redisson() { // 1. 创建配置 Config config = new Config(); config.useSingleServer().setAddress("redis://172.16.212.10:6379").setConnectionMinimumIdleSize(1); // 2. 根据Config创建出RedissonClient实例 return Redisson.create(config); }
锁的粒度越细越快
具体缓存的是某个数据,如11号商品: product-11-lock
2.3 读写锁
RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");
// 获取写锁
RLock wLock = lock.writeLock();
// 获取读锁 RLock rLock = lock.readLock();
lock.lock();
lock.unlock();
- 保证一定能读到最新的数据,修改期间,写锁是一个排他锁(互斥锁)。读锁是一个共享锁。
| 后 先 |
读 | 写 |
|---|---|---|
| 读 | 相当于无锁,并发读,只会在redis中记录好,所有当前的读锁,他们都会同时加锁成功 | 有读锁,写也需要等待 |
| 写 | 等待写锁释放 | 阻塞 |
2.4 信号量
注意要在使用之前在Redis中添加这个key和数值。
set park 3
@GetMapping("/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redisson.getSemaphore("park");
park.acquire(); // 阻塞式获取一个信号,获取一个值,占一个车位
park.tryAcquire(); // 非阻塞式
return "ok";
}
@GetMapping("/go")
@ResponseBody
public String go() {
RSemaphore park = redisson.getSemaphore("park");
park.release(); // 释放一个车位
return "ok";
}
六、CompletableFuture
1 创建一个异步操作
-
runAsync
不能获得返回值,但可以调用返回的CompletableFuture对象的get()阻塞等待执行完成。public static CompletableFuture<Void> runAsync(Runnable runnable) public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) -
supplyAsync
可以获得返回值。public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
2 计算完成回调
whenComplete
- BiConsumer的第一个参数为结果,第二个参数为异常。
- 能够得到异常信息,但是无法修改饭回信息。
public CompletableFuture<T> whenComplete( BiConsumer<? super T, ? super Throwable> action) public CompletableFuture<T> whenCompleteAsync( BiConsumer<? super T, ? super Throwable> action) public CompletableFuture<T> whenCompleteAsync( BiConsumer<? super T, ? super Throwable> action, Executor executor)
-
exceptionally
可以感知异常,同时返回默认值。
示例public CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)CompletableFuture<Integer> done = CompletableFuture.supplyAsync(() -> { System.out.println("bef"); // 会打印 int a = 1 / 0; System.out.println("aft"); // 不会打印 return a; }, executor).whenComplete((result, exception) -> { System.out.println("done"); }).exceptionally((exception) -> { return 1; }); System.out.println(done.get()); // 打印1
3 方法执行完成后的处理handle 二合一。
CompletableFuture<Integer> done = CompletableFuture.supplyAsync(() -> {
return 1 / 0;
}, executor).handle((result, exception) -> {
System.out.println("done");
return 1;
});
System.out.println(done.get()); // 打印1
4 线程串行化方法
| 方法 | 感知上一步结果 | 有返回值 |
|---|---|---|
| thenApply | ✓ | ✓ |
| thenAccept | ✓ | ✗ |
| thenRun | ✗ | ✗ |
| 带有Async默认是异步执行的。同之前。 | ||
| 以上都要前置任务成功完成。 |
5 两个任务都必须完成再执行future1.combine(future2, (result1, result2) -> …)
| 方法 | 感知上一步结果 | 有返回值 |
|---|---|---|
| thenCombine | ✓ | ✓ |
| thenAcceptBoth | ✓ | ✗ |
| runAfterBoth | ✗ | ✗ |
6 一个完成就执行
| 方法 | 感知上一步结果 | 有返回值 |
|---|---|---|
| applyToEither | ✓ | ✓ |
| acceptEither | ✓ | ✗ |
| runAfterEither | ✗ | ✗ |
7 多任务组合allOf 所有的事都做完再执行anyOf 有一个成功就执行
七、SpringSession
1 分布式下Session共享问题解决
- session复制

- 优点
- Tomcat原生支持,只需要修改配置文件
- 缺点
- 同步需要数据传输,占用大量网络带宽
- 每一台服务器保存所有session,受内存限制
- 大型分布式下所有服务器保存全量数据不可取
- 客户端存储

- 优点
- 节省服务端资源
- 缺点
- 都是缺点(不要使用这种方式!)
- 每次http请求都要携带完整信息,浪费带宽
- cookie长度限制4K,不能保存大量信息
- 泄漏、篡改、窃取等安全隐患
- hash一致性

- 优点
- 只需要修改nginx配置
- 负载均衡,只要hash值分布均匀
- 支持水平扩展
- 缺点
- 服务器重启导致部分session丢失
- 水平扩展rehash后,session重新分布,部分用户路由不到正确session
但是本来session就是有有效期的,所以两种反向代理的方式可以使用
- 统一存储

- 优点
- 支持水平扩展,数据库/缓存水平切分即可
- 服务器重启不会导致session丢失
- 缺点
- 增加了一次网络调用
2 使用SpringSession实现统一存储
可以配置session在浏览器上的cookie存储的Domain属性,从而让多个子域名共享session id。
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
spring:
session:
store-type: redis
timeout: PT30M
@Configuration
public class MySessionConfig {
@Bean
public CookieSerializer cookieSerializer() {
DefaultCookieSerializer cookieSerializer = new DefaultCookieSerializer();
cookieSerializer.setDomainName(".gulimall.com");
cookieSerializer.setCookieName("GULISESSION");
return cookieSerializer;
}
@Bean
public RedisSerializer<Object> springSessionDefaultRedisSerializer() {
return new GenericJackson2JsonRedisSerializer();
}
}
八、RabbitMQ
1 工作流程

2 安装
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
docker update rabbitmq --restart=always
4369, 25672 (Erlang发现&集群端口)
5672, 5671 (AMQP端口)
15672 (web管理后台端口)
61613, 61614(STOMP协议端口)
1883, 8883 (MQTT协议端口)
https://www.rabbitmq.com/networking.html
3 Exchange
3.1 Exchange类型
- exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型: direct, fanout, topic, headers。
- headers 匹配AMQP消息的header而不是路由键,headers交换器和direct交换器完全一致,但性能差很多,目前几乎用不到了,所以直接着另外三种类型。
3.1.1 Direct Exchange

- 消息中的路由键(routing key)如果和Binding中的binding key一致,交换器就将消息发到对应的队列中。
- 如果一个队列绑定到交换机要求路由键为 “dog”,则只转发routing key标记为 “dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。
- 它是完全匹配、单播的模式。点对点
3.1.2 Fanout Exchange

- 每个发到fanout交换器的消息都会分到所有绑定的队列上去。
- 像子网广播,每台子网的主机都获得了一份复制的消息。
- fanout类型转发消息是最快的。广播
3.1.3 Topic Exchange

- 将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。
- 它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:
#(匹配0个或多个单词)和*(匹配一个单词)。主题
4 整合Spring Boot
4.1 配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
引入生效大致原理
- 引入amqp场景,
RabbitAutoConfiguration就会自动生效 - 给容器自动配置:
RabbitTemplateAmqpAdminCachingConnectionFactoryRabbitMessagingTemplate
Spring配置
- 配置文件
spring: rabbitmq: host: 172.16.212.10 port: 5672 virtual-host: / -
@EnableRabbit开启rabbit
4.2 AmqpAdmin
4.2.1 创建
@Autowired
private AmqpAdmin amqpAdmin
public void createExchange() {
DirectExchange directExchange = new DirectExchange(
name: "hello-java-exchange",
durable: true,
autoDelete: false);
amqpAdmin.declareExchange(directExchange);
}
public void createQueue() {
Queue queue = new Queue(
name: "hello-java-queue",
durable: true,
autoDelete: false
);
amqpAdmin.declareQueue(queue);
}
public void createBinding() {
// 将exchange指定的交换机和destination目的地进行绑定,使用routingKey作为指定的路由键
Binding binding = new Binding(
destination: "hello-java-queue",
Binding.DestinationType.QUEUE,
exchange: "hello-java-exchange",
routingKey: "hello.java"
);
amqpAdmin.declareBinding(binding);
}
4.2.2 收发消息
- 发送消息
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage() {
rabbitTemplate.convertAndSend(
exchange: "hello-java-exchange",
routingKey: "hello.java",
new Object() // 如果发送的消息是一个对象,就会使用序列化机制,对象必须实现Serializable
);
}
不使用序列化而使用JSON格式:
@Configuration
public class MyRabbitConfig {
@Bean
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
}
- 监听消息
@RabbitListener(queues = {"hello-java-queue"})
public void receiveMessage(
Message message,
T content // 当时发送的消息类型T在接收时Spring会自动转化
Channel channel // 当前传输数据的通道
) {
byte[] body = message.getBody();
}
- 同一个消息,只能有一个客户端收到
- 当一个消息被处理完,才可以接收下一个消息
@RabbitListener 和 @RabbitHandler@RabbitListener 可以标注在方法或类上@RabbitHandler 可以标注在方法上
二者配合使用实现对重载区分不同的消息
@RabbitListener(queues = ...)
public class RabbitTest {
@RabbitHandler
public void handle(Car car) {
...
}
@RabbitHandler
public void handle(Plane plane) {
...
}
}
5 可靠抵达
保证消息不丢失,可靠抵达,可以使用事务消息,性能下降250倍,为此引入确认机制
- publisher confirmCallback 确认模式
- publisher returnCallback 未投递到 queue 退回模式
- consumer ack机制
5.1 ConfirmCallback 服务器收到消息
在application.properties中设置spring.rabbitmq.publisher-confirms=true
- 在建 connectionFactory的时候没置
PublisherConfirms(true)选项, 开启 confirmCallback。 - CorrelationData: 用来表示当前消息唯一性。
- 消息只要被 broker 接收到就会执行 confirmCallback,如果是 cluster模 式,需要所有 broker 接收到オ会凋用 confirmCallback。
- 被broker接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的
returnCallback。
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct // @Configuration对象创建完成以后执行的方法
public void initRabbitTemplate() {
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(
CorrelationData correlationData, // 当前消息的唯一关联数据(这个是消息的唯一id)
boolean ack, // 消息是否成功收到
String cause // 失败的原因
) {
// callback
}
});
}
5.2 ReturnCallback 消息未能抵达队列
在application.properties中配置
- 开启发送端消息抵达队列的确认
spring.rabbitmq.publisher-returns=true - 只要抵达队列,以异步发送优先回调我们这个return confirm
spring.rabbitmq.template.mandatory=true
@PostConstruct // @Configuration对象创建完成以后执行的方法
public void initRabbitTemplate() {
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
@Override
public void confirm(
Message message, // 投递失败的消息详细信息
int replyCode, // 回复的状态码
String replyText, // 回复的文本内容
String exchange, // 当时这个消息发送给哪个交换机
String routingKey // 当时这个消息用哪个路由键
) {
// callback
}
});
}
5.3 Ack 客户端消息确认
默认是自动确认的,只要消息收到,客户端会自动确认,服务端会移除这个消息。
问题
我们收到很多消息,自动回复给服务器ack,只有一个消息处理成功,宕机了,发生消息丢失。
开启手动确认模式spring.rabbitmq.listener.simple.acknowledge-mode=manual
只要没明确告诉mq货物被签收(没有ack),消息一直是unacked状态。即使Consumer宕机,消息也不会丢失,会重新变为Ready,下一次有新的Consumer连接进来就发给他。文章来源:https://www.toymoban.com/news/detail-432019.html
@RabbitListener(queues = {"hello-java-queue"})
public void receiveMessage(
Message message,
T content, // 当时发送的消息类型T在接收时Spring会自动转化
Channel channel // 当前传输数据的通道
) {
// deliveryTag是channel内按顺序自增的
channel.basicAck(
message.getMessageProperties().getDeliveryTag(),
multiple: false
requeue: true
);
}
Ack消息确认机制总结文章来源地址https://www.toymoban.com/news/detail-432019.html
- 消费者获取到消息,成功处理,可以回复Ack给Broker
- basic.ack用于肯定确认;broker将移除此消息
- basic.nack用于否定确认;可以指定broker是否丢弃此消息,可以批量
- basic.reject用于否定确认;同上,但不能批量
- 默认自动ack,消息被消费者收到,就会从broker的queue中移除
- queue无消费者,消息依然会被存储,直到消费者消费
- 消费者收到消息,默认会自动ack。但是如果无法确定此消息是否被处理完成,或者成功处理。我们可以开启手动ack模式
- 消息处理成功,
ack(),接受下一个消息,此消息broker就会移除 - 消息处理失败,
nack()/reject(),重新发送给其他人进行处理,或者容错处理后ack - 消息一直没有调用
ack()/nack()方法,broker认为此消息正在被处理,不会投递给别人。此时客户端断开,消息不会被broker移除,会投递给别人
- 消息处理成功,
到了这里,关于【笔记/后端】谷粒商城高级篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!