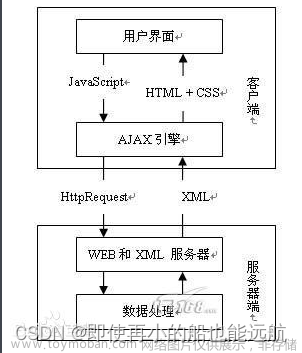
案例:爬取豆瓣电影Top 250的列表(电影名称、导演、主演、星级等信息)
浏览器console
操作:浏览器内鼠标右键 —> “检查”(不同的浏览器名称可能不一样,此处使用了Google)—> Elements :查看网页结构 —> Console : 输入指令文章来源:https://www.toymoban.com/news/detail-432222.html

 文章来源地址https://www.toymoban.com/news/detail-432222.html
文章来源地址https://www.toymoban.com/news/detail-432222.html
var i = 0;
var hd = document.querySelectorAll("div.hd > a");
var bd = document.querySelectorAll("div.bd > p");
var star = document.querySelectorAll("div.bd > div.star > span.rating_num");
var quote = document.querySelectorAll("div.bd > p.quote > span.inq");
for(var t of document.querySelectorAll("ol.grid_view > li > div.item > div.info"))
{
console.log(hd[i].href);
console.log(到了这里,关于【整理】爬取网页数据的方法汇总的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!