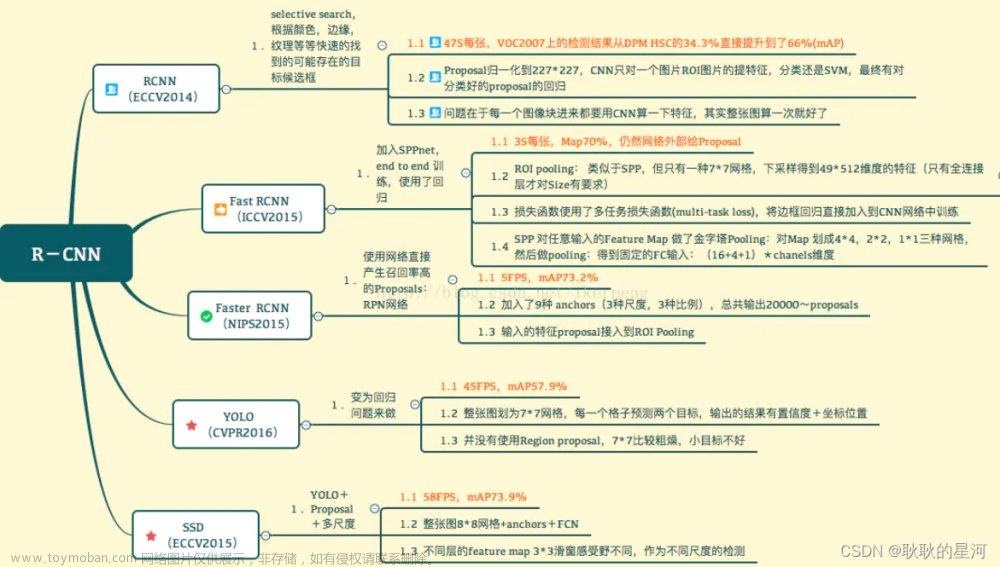
一、背景
随着人们的生活水平不断提高,汽车数量日益增加。随之而来的管理难度逐渐增大,对车牌检测有了越来越高的需求,比如:在汽车违法检测、停车场的入口检测等都需要车牌检测进行辅助管理。中国车牌根据颜色可划分为五种颜色:蓝色、黄色、白色、黑色、绿色。根据车牌层数可以分为单层和双层车牌,还可以更加细分为以下类别:
- 蓝色单层车牌
- 黄色单层车牌
- 黄色双层车牌
- 绿色新能源车牌、民航车牌
- 绿色农用车牌
- 黑色单层车牌、使馆车牌
- 白色警牌、军牌、武警车牌
- 白色双层军牌
考虑到目前实际生活中的实际情况以及开源的车牌数据集的原因,仅实现对蓝色、黄色、绿色的单层车牌进行车牌检测,白色和黑色车牌检测效果不佳。
二、开发环境与库函数说明
采用Python语言编写,使用到的库函数较多。这里仅介绍主要使用的库:
tkinter:tkinter模块是Python的标准Tk GUI工具包的接口。GUI界面采用该工具包。
opencv-python:是一个Python绑定库,旨在解决计算机视觉问题。在实现传统图像处理方法检测车牌中使用大量使用到。
torch:是深度学习神经网络中常用的库。在实现YOLOv5算法检测车牌中使用到。
tensorflow:tensorflow是Google推出的机器学习开源神器,拥有各种各样的模型和算法。在实现CNN对车牌字符识别中使用到。
还使用到了许多其他库,这里就不一一介绍了,详情可见代码中的requirements.txt文件。
三、编程思想介绍
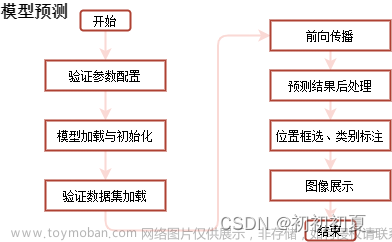
本次课程设计采用模块化设计,将程序GUI和具体算法的实现进行分隔,将每一个识别算法进行封装,互不影响。各模块调用关系流程图如图1所示:

图1 各模块调用关系图
四、程序设计过程
程序可以划分为GUI模块、传统方法检测车牌+SVM识别车牌字符模块、YOLOv5方法检测车牌+SVM识别车牌字符模块、YOLOv5方法检测车牌+CNN识别车牌字符模块等四大模块,下面将进行详细介绍。
1.GUI模块
GUI模块采用tkinter库实现界面,由于界面不是重点,所以界面设计得比较简约。界面效果如图2所示:

图2 界面效果图
界面主要包含原图、车牌位置、识别结果、选择识别算法、选择图片等组件。由于界面布局比较简单,在此不对代码逻辑进行介绍。使用时需注意当没有选择图片时,无法选择识别算法,识别算法默认选择“传统方法检测车牌+SVM识别车牌字符”算法。当选择图片后,可以随意更改识别算法。
2.传统方法检测车牌+SVM识别车牌字符模块
该模块可以细分为两个子模块,分别是传统方法检测车牌和识别车牌字符模块。传统方法检测车牌模块使用图像处理方法负责在一张图像中检测出车牌,识别车牌字符模块使用SVM算法负责识别车牌中的字符。
(1)以图3为例,下面介绍传统方法检测车牌做了哪些工作:
①调整图片比例,进行高斯去噪,并将图片转换为灰度图。处理后的效果图如图4所示:


图3 原图 图4 去噪后的灰度图
②进行形态变化,并将变化后的图像和灰度图两幅图像合成为一幅图像。处理后的效果图如图5所示:


图5 形态变化后的效果图
③先对图像进行阈值处理,再使用cv2.Canny函数进行边缘检测。处理后的效果图如图6所示:

图6 边缘检测后的效果图
④查找图像边缘整体形成的矩形区域,可能有很多,可以根据长宽比例是否是2~2.5之间进行排除那些不是矩形的区域。
⑤矩形区域可能是倾斜的矩形,所以先进行矫正,然后根据颜色定位,排除不是车牌的矩形,目前只识别蓝、绿、黄车牌。
⑥检测到车牌位置后,再根据车牌颜色再定位,缩小边缘非车牌边界。得到车牌如图7所示:

图7 检测到的车牌
(2)在检测到车牌后,紧接着对车牌进行字符识别的工作:
①将车牌转换为灰度图,并根据车牌颜色进行处理。由于黄、绿车牌字符比背景暗,蓝车牌刚好相反,所以黄、绿车牌需要进行反向处理。处理好后的效果图如图8所示:

图8 处理后的车牌
②对字符进行分割。首先进行水平投影,将二值化的车牌图片水平投影到Y轴,得到连续投影最长的一段作为字符区域,因为车牌四周有白色的边缘,这里可以把水平方向上的连续白线过滤掉。然后进行垂直投影,因为字符与字符之间总会分隔一段距离,因此可以作为水平分割的依据,分割后的字符宽度必须达到平均宽度才能算作一个字符,这里可以排除车牌第2、3字符中间的“.”。
③将分割后的字符进行预测,使用训练好的svmchinese.dat对车牌中的中文字符进行预测,使用训练好的svm.dat对车牌中的英文和数字字符进行预测,得到预测结果为['京','A','D','7','Z','9','7','2']。预测结果中,有一点小错误,是因为训练SVM模型的数据集太少的原因,导致结果不准确。程序GUI显示的效果图如图9所示:

图9 GUI显示的效果图
2.YOLOv5方法检测车牌+SVM识别车牌字符
该模块可以细分为两个子模块,分别是YOLOv5方法检测车牌和识别车牌字符模块。YOLOv5方法检测车牌模块使用YOLOv5模型负责在一张图像中检测出车牌,识别车牌字符模块使用SVM算法负责识别车牌中的字符。SVM算法识别车牌中的字符的过程在上一个小节描述了,在这儿不再赘述了。
YOLOv5模型Ultralytics公司于2020年6月9日公开发布的。YOLOv5模型是基于YOLOv3模型基础上改进而来的,有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5四个模型。YOLOv5模型由骨干网络、颈部和头部组成。是计算机视觉界十分流行的模型,由于模型较大同时数据集也很大,导致训练时间非常长,本次课程设计采用在CCPD数据集上预训练好的模型作为车牌检测模型。
①加载预训练好的模型,检测出车牌的四个角的坐标,检测效果图如图10所示,红框中即是检测出的车牌。

图10 车牌检测的效果图
②检测出车牌后,将车牌截取出来,截取出的车牌如图11所示。截取出的车牌再使用SVM模型进行字符识别。

图11 截取出的车牌效果图
3.YOLOv5方法检测车牌+CNN识别车牌字符
该模块可以细分为两个子模块,分别是YOLOv5方法检测车牌和识别车牌字符模块。YOLOv5方法检测车牌模块使用YOLOv5模型负责在一张图像中检测出车牌,识别车牌字符模块使用CNN算法负责识别车牌中的字符。YOLOv5模型检测车牌的过程在上一个小节描述了,在这儿不再赘述了。
CNN算法是卷积神经网络(Convolutional Neural Networks,简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一。卷积神经网络CNN的结构一般包含这几层:
1)输入层:用于数据的输入。
2)卷积层:使用卷积核进行特征提取和特征映射。
3)激活层:由于卷积也是一种线性运算,因此需要增加非线性映射。
4)池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
5)全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失。
6)输出层:输出模型预测的结果。
采用Tensorflow库搭建CNN模型,由于CCPD数据集庞大,训练时间久,受于实验设备和时间的影响,采用在CCPD数据集上预训练好的模型作为车牌字符识别模型。但是由于该预训练模型训练轮次不够,同时由于数据集黄色和绿色牌照的数量较少,导致模型对黄色和绿色牌照的检测效果十分差,但是蓝色牌照识别准确率很高。
五、实验结果
1.程序运行效果:
程序运行的初始界面如图12所示。当未选择图片时,“选择识别算法”下的单选框处于禁用状态,默认选择“传统方法检测车牌,SVM识别车牌字符”。

图12 程序运行的初始界面
在选择图片后,可根据需要切换识别算法,在“选择识别算法”选择对应算法的单选框,程序便会自动执行对应的识别算法。选择不同的识别算法后,程序运行的界面如图13所示:



图13 程序运行界面
2.识别算法准确率分析:
为了了解算法哪个算法的检测准确率最高,在测试集对识别算法进行测试。测试集包含30张图片,其中蓝色牌照24张、黄色牌照4张以及绿色牌照2张。测试集中的牌照比例是根据CCPD数据集中各牌照比例进行设计的。测试结果如表1所示:
| 算法 |
准确率(%) |
| 传统方法检测车牌+SVM识别车牌字符 |
56.7% |
| YOLOv5方法检测车牌+SVM识别车牌字符 |
60% |
| YOLOv5方法检测车牌+CNN识别车牌字符 |
43.3% |
从实验结果可以看出,总体上看识别准确率并不高,但是观察识别错误中的数据,发现其中只是个别字符出现错误。其中YOLOv5对车牌的检测效果要略优于传统图像处理方法,如果YOLOv5算法训练数据集以及训练轮次增加,识别效果将会变得更好。SVM识别车牌字符效果看上去要比CNN识别车牌字符好,具体的原因是CNN训练轮次不足导致的,如果实验条件充足,增加训练轮次和数据集,那么CNN识别效果肯定是优于SVM的。总体上来说,我认为YOLOv5方法检测车牌+CNN识别车牌字符算法准确率是要优于其他算法的,但是资源消耗上要远远高于其他算法。这也是深度学习模型共有的缺陷了,太过于依赖训练轮次和训练数据集。
代码在:https://github.com/Dara-to-win/Plate-Recognition
欢迎Star一下!!!
参考文献:
[1]基于yolov5的车牌检测,https://github.com/xialuxi/yolov5-car-plate
[2]CCPD(中国城市停车数据集),https://github.com/detectRecog/CCPD
[3]端到端车牌识别项目,https://github.com/MrZhousf/license_plate_recognize
[4]车牌号识别python + opencv,https://blog.csdn.net/wzh191920/article/details/79589506
[5]车牌号识别https://github.com/wzh191920/License-Plate-Recognition文章来源:https://www.toymoban.com/news/detail-432298.html
[6]CNN算法,http://t.zoukankan.com/lorenshuai724005-p-9520445.html文章来源地址https://www.toymoban.com/news/detail-432298.html
到了这里,关于YOLOv5、CNN、SVM实现车牌检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!