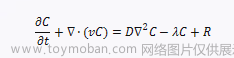目录
A题:数据题
A:评价问题、机器学习问题(套算法就可做,相关算法现学上手快,所有人都可以选)
- 首先来看附件数据,行为不同的银行(未编号),每个银行有64个指标,最后一列1表示破产,0表示存活,没有给银行编号,就不用衡量那个银行的好坏,这道题只需要你筛选出主要指标后用于机器学习训练,最简单的就是Logistic算法,典型的二分类模型。
- 首先还是需要对数据进行预处理,特别是存在异常字符和缺失的,如果存在异常较多的指标可以删除,缺失数据可以剔除或拟合填补,指标有解释,初步可以人为去排除不相关变量(可选做),特别还要注意,一些指标中存在少数离散度较高的数据,需要剔除对应的样本。然后进行降维,matlab函数工具箱drtool(下载地址http://lvdmaaten.github.io/drtoolbox/)内包含多种降维算法,可以去下载安装,里面的方法可自行选择适合的就行,注意这里的降维因为涉及到多个年份,因此严谨来说需要把所有年份的指标合并来进行降维,筛选出主要指标,这样可以保证指标的统一性
- 确定权重就不用多说,很多方法(层次分析、熵权法、投影寻踪、模糊Borda等)。风险预测,就是0-1二分类,这里大家可以先套算法去做,肯定效果不好,后面我把我之前做过的一个数据清洗模型分享出来,能很大程度上减少机器学习算法训练误差。
- 【关于为什么不能用数据包络,本来64个指标就是不同的投入产出指标的比值了,还犯基本的逻辑错误,并且数据包络不是用来做评价的,只是算一个相对的投入产出效率,只能当成一个指标参考,不能当作综合评价水平,算法底层逻辑要弄明白】
第一问
从64个指标中降维,将几个年份的数据合并降维,首先数据需要标准化去量纲,可以就通过主成分分析法,得到累计贡献率达到85-95%以上的主要成分,该算法降维后得到的是n个映射基线(n个主成分),接下来用每条基线与64个指标求距离和相关性,距离最小的或相关性最强的当选第i个主成分[这个步骤在spss中可以直接轻松得到,要用matlab编程就采用这个来],各主成分贡献率归一化可以作为权重,也可以重新用熵权法等方法计算权重,然后加权和得出评价值,也可以用因子分析一步到位。评价值越大,理应不存在较多破产,数据离散可能存在少数异常情况,反正需要反向验证下模型的合理性。如果不合理就需要换一种方法,drtool工具箱中有很多降维方法,可以选择一种更合适的,做法也同以上思路。然后是倒闭各指标的分界线,其实很简单,单独对筛选出来的指标,依次进行聚类分成两类,两个聚类中心的中点就可以定义为分界值,这里不建议把所有指标一起拿来聚类。
第二问
要注意和第一问算法有所区别,第二问最合适的是方差分析或相关性分析,在64个指标中,依次遍历对因变量(是否破产)进行方差分析,最后保留影响最显著的5个指标。
第三问
在一二问得出不同的重要指标组合,分别作为自变量,是否破产作为因变量,用神经网络,逻辑回归,机器学习等方法进行训练,最后比较结果误差。
第四问
其实就是说小样本训练,考虑的指标由第三问得出的结论来定,看是用第一问主要指标组合还是第二问的,接下来分别在2021年存活和破产的银行和列表中,以主要指标作为空间点,找出尽可能能反映出整体情况的20个点,理想情况就是这20个点均匀分布,其实这里就用普通的聚类就可以了,聚20类,每类中距离聚类中心最近的点作为小样本。然后同样是带入机器学习算法训练,结果误差与第三问进行对比。
第五问
其实本问就是让你找出2017-2021年都有的一些银行,不是破产是1吗,你可以划分5等分,分别五个不同的倒闭风险,然后进行说明就行了。那么剩下的就是如何从2017-2021中判断出哪些数据为同一家银行,这里不精准都可以,主要是方法逻辑正确就行。本问的基础数据有之前的数据清洗和主要指标筛选方式决定,找2017-2021都有数据的银行,可以简单考虑,如果是同一家银行,其指标变化一般特定的几个指标不会变化太大,这里可不是简单的聚类,这里我给大家举个例子,假设指标变化临界值为5%,假设当前主要指标为5个,依次遍历所有样本,达到以下两个情况则认为是同一个家银行:
- 有两个以上指标变化在5%内
- 平均误差在10%以内。
B题:疫情题
第一问
预测清零时间反正就SIR模型吧,网上有很多参考就不多说,能获取到历史数据的网站推荐新浪疫情、网易疫情(有城市的累计死亡、累计感染、累计治愈数据),文档也给大家整理了一些,后续还会补充。仅考虑传染病模型显然是不足的,结合第二问,经济发展水平其实一定程度上能反映出一个地区的医疗物资的保供能力,那么势必会结合疫情期间的资源配送情况,那么对于迁入指数(疫情期间一般是物资配送)就可以考虑其中了,如下图,其他的指标都不是特别重要,主要是物资运送,第一问就在SIR模型中将迁入指数作为影响治愈率的影响因子就行,政治因素没办法量化,就不做考虑。下面是百度迁徙指数的上海迁入指数情况,网上直接搜“百度迁徙指数”就行,自己爬取下数据下来,不行就人工统计。假设不考虑政治等因素,有了参数就去推导下上海和北京清零时间。
第二问
就是说不能因为疫情防控,就限制了居民看病的权利,可以去查一下当地医院总数和用于新冠治疗的医院数,更多而医疗机构加入到抗疫当中自然疫情能够得到很好地解决,但是反过来看,会增加一些重症疾病的死亡率,本文大家可以假设一所医院的服务的患者数,该地区患者存在重症的概率,每有一所医院加入到抗击新冠行列中,新冠治愈率会得到提高,但是对于重症疾病患者的治愈率会降低,构建一个博弈模型进行推导,得到最佳用于抗击新冠的意愿数。也是封长春、上海、北京讨论并做对比分析。
第三问
根据平均入住率先推导出每栋楼的户数,根据总数推导一户平均有多少人,然后计算得到每栋楼有多少人。核酸检测点肯定有多个,本题就这么来考虑,一个核酸点检测多栋楼,那么本题可以考虑为一个优化算法,自变量为核酸检测点数,不同的核酸检测点位,又有不同的分组情况,也就是有不同的人数,假设检测一人需要10s中,那么该小区完成核酸检测的时间以检测最后一个人为准,由此可以进行优化算法寻优,以核酸检测点数最小且核酸完整时间最小为目标函数,进行多目标寻优。
第四问
这个现象我们平常生活经常见到,一个骑手可能会到多个地方去送餐,在疫情期间,如果能将需求进行打包,这样就可以很大程度上减少交互行为,本问可以随机模拟一些需求点,默认每个需求点需求量为1,如果十分邻近的点可以取平均作为一个点,且需求量相加表示,背景就假设有足够的骑手配送,但是每次配送有需求量限制,然后对需求点进行打包,尽可能满足打包内的需求点尽可能集中,目标函数可以是所有打包内中的各点的平均距离之和,进行最小化寻优。文章来源:https://www.toymoban.com/news/detail-433147.html
C题 运动会优化比赛模式探索
C题 运动会优化比赛模式探索文章来源地址https://www.toymoban.com/news/detail-433147.html
文章链接
- 本文原文链接:2022数维杯数学建模竞赛A\B题目思路
- 推荐链接:2022数维杯ABC思路程序实时更新
- 推荐链接:如何看待 2021 年数维杯大学生数学建模竞赛 ABC 题?该怎么分析?
到了这里,关于2022数维杯数学建模竞赛A\B\C题目思路的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!