💥 💥 💞 💞 欢迎来到本博客 ❤️ ❤️ 💥 💥
🏆 博主优势: 🌞 🌞 🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳ 座右铭:行百里者,半于九十。
📋 📋 📋 本文目录如下: 🎁 🎁 🎁
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码实现
💥1 概述
参考文献:

CNN 是通过模仿生物视觉感知机制构建而成,能够进行有监督学习和无监督学习[33]。隐含层的卷
积核参数共享以及层间连接的稀疏性使得 CNN 能够以较小的计算量从高维数据中提取深层次局部特征,并通过卷积层和池化层获得有效的表示[34]。CNN 网络的结构包含 2 个卷积层和 1 个展平操作,每个卷积层包含 1 个卷积操作和 1 个池化操作。第2 次池化操作后,再利用全连接层将高维数据展平为 1 维数据,从而更加方便的对数据进行处理。CNN结构如图 1 所示。
当时间步数较大时,RNN 的历史梯度信息无法一直维持在一个合理的范围内,因此梯度衰减或爆
炸几乎不可避免,从而导致 RNN 将很难从长距离序列中捕捉到有效信息[35]。LSTM 作为一种特殊的RNN,其提出很好地解决了 RNN 中梯度消失的问题[36]。而 GRU 则是在 LSTM 的基础上提出,其结 构更简单,参数更少,训练时间短,训练速度也比更快[37]。GRU 结构图如图 2 所示。

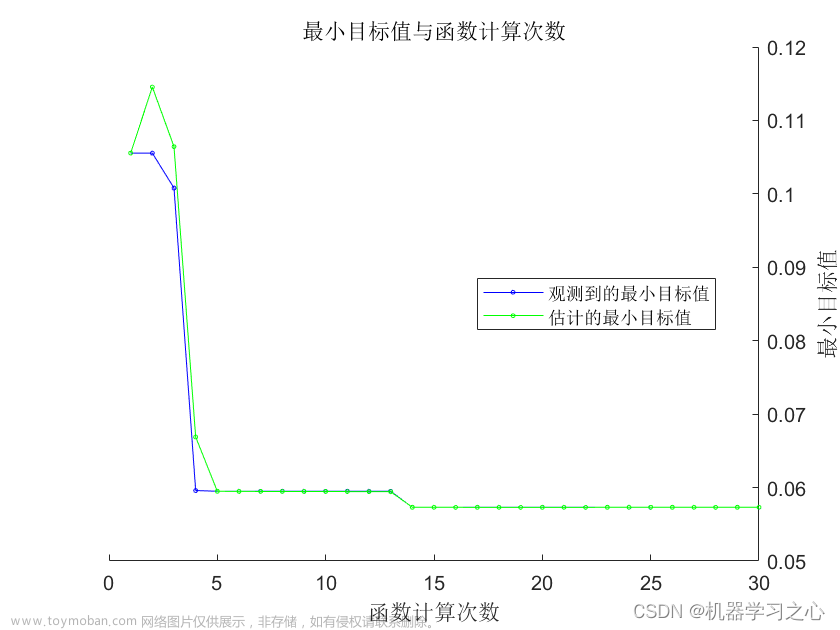
贝叶斯优化也称为基于序列模型的优化方法 (sequential model-based optimization method, SMBO), 属于无导数技术。BO 方法包括使用高斯过程回归模型估计目标函数[40]。首先,评估 2 组随机超参数。使用概率模型顺序建立优化问题的先验知识,然后对目标函数 f(z)进行标量[41],如式所示。

式中,z* 是 f(z)约束域的全局最优值,包括实数、整数或分类特征值。BO 算法的优点是收敛速度快、性能好、可扩展性强、适用于超参数寻优问题,特别是在特征为非参数的情况下。然而,基于 BO 的超参数寻优的缺点可以归结为两类:训练时间和 BO 参数的调整。由于 BO 是一种顺序方法,为减少计算时间,对其进行并行化很困难[27]。此外,BO 的核函数很难调整,最近的一项研究工作解决了这些问题,如标准化BO 参数。文章来源:https://www.toymoban.com/news/detail-433166.html
📚2 运行结果








🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]邹智,吴铁洲,张晓星等.基于贝叶斯优化CNN-BiGRU混合神经网络的短期负荷预测[J].高电压技术,2022,48(10):3935-3945.DOI:10.13336/j.1003-6520.hve.20220168.文章来源地址https://www.toymoban.com/news/detail-433166.html
🌈4 Matlab代码实现
到了这里,关于基于贝叶斯优化CNN-LSTM混合神经网络预测(Matlab代码实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!