目录:导读
引言
po模式
优势:
目录解释:
页面对象设计模式:
base基础层:
page对象层:
test:测试层
data数据层:
common层:
untils:
config层:
run层:
report:
结语
引言
你是否曾经因为每次更新功能都要重新写一堆自动化测试代码而感到疲惫不堪?
或者因为页面元素的频繁变动而不得不持续地修复测试脚本?
如果你也有这些苦恼,那么PO模式设计框架可能是解决之道。它可以让你以更简单、更高效的方式编写自动化测试代码,减少反复劳动和错误率。
在本文中,我们将介绍如何采用PO模式设计框架来秒杀繁琐的自动化测试操作,让你轻松应对变化万千的测试环境。
po模式
在UI级的自动化测试中,对象设计模式表示测试正在交互的web应用,程序用户界面中的一个区域,这个是减少了代码的重复,也就是说,如果用户界面发生了改变,只需要在一个地方修改程序就可以了。
优势:
1、创建可以跨越多个测试用例共享的代码
2、减少重复代码的数量
3、如果用户界面发生变更后,只需要在一个地方维护就可以了。
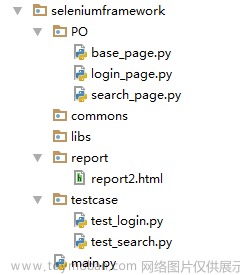
创建ui,在ui的工程中创建对应的包和目录。utils 最后一个包的名称

目录解释:
各个目录详解:
(1)base:基础层,主要编写底层定位元素的类,它是一个包。
(2)common:公共类,里面编写公共使用到的方法。
(3)config:配置文件存储目录。
(4)data:存储测试使用到测试数据。
(5)page:对象层,编写具体的业务逻辑,把页面每一个操作行为单独的写一个方法或者是函数。
(6)report:测试报告目录,主要用来存放测试报告。
(7)test:测试层,里面主要是测试模块,也可以说是每个测试的场景的代码。
(8)utils:工具类,存放工具,如文件处理、说明文档等。
(9)run:运行层:整个自动化测试的运行目录。
页面对象设计模式:
base基础层:
在该层中主要编写了基础代码。在该层主要定义了类WebUI,在这个类中编写了单个元素和多个元素定位的方法。
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# author:张红
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.expected_conditions import NoSuchElementException
import time as t
class WebUI(object):
def __init__(self,driver):
#webdriver实例化后的对象
self.driver=driver
def findElement(self,*args):
'''
单个元素定位的方式
:param args:
:return: 它是一个元组,需要带上具体什么方式定位元素属性以及元素属性的值
'''
try:
return self.driver.find_element(*args)
except NoSuchElementException as e:
return e.args[0]
def findsElement(self,*args,index):
'''
多个元素定位的方式
:param args:
:param index: 被定位的目标索引值
:return: 它是一个元组,需要带上具体什么方式定位元素属性以及元素属性的值
'''
try:
return self.driver.find_elements(*args)[index]
except NoSuchElementException as e:
return e.args[0]page对象层:
在这一层的类直接继承了基础层的类,以类属性的方法指明每个操作元素属性的值,然后依据操作步骤编写对应的方法,(比如关于登录的操作:输入用户名、输入密码,点击登录,获取文本的信息操作会在实例中实现的登录操作,然后把每个登录操作封装成一个方法,这样实现登录测试用例直接调用,返回失败信息---其中形式参数会在测试层赋值)
注意:获取文件信息的方法,要有return返回值否则在测试层断言时获取不到文本信息,数据属性和方法名字不要一样

test:测试层
在这里首先需要导入对象层中的类和unittest单元测试框架,在测试类中,继承了unittest.TestCase和对象层中的类,TestCase是由于在编写自动化测试的用例中,用到的测试固件、测试断言和测试执行都是需要它中的方法,而对象层中的类包含对象层中的测试操作步骤的方法,继承后可以直接进行调用。
注意事项:
1、在编写用例的时候需要添加备注信息,明确表示该用例是测试的哪个点,验证的哪个场景.
2、测试模块都是以test_开头,测试方法也是以test_开头的
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|
data数据层:
春初测试使用到的测试数据(主要是把数据写入json文件,yaml文件)
在data下创建json文件

common层:
common:公共层,里面编写公共使用到的文件(处理路径---重点处理的是json文件或者yaml文件)一般时定义基础路径的
1、在这个层创建public.py 文件
导入os库,定义基础路径(也就是把基础路径处理为将要读取文件所在文件夹的路径,这样方便使用的时候做路径拼接)

untils:
工具层:基本上是对data里面的(json yaml文件的读取)
在untils下创建模块:operationJson.py,设置方法readJson()来读取数据
在这个模块我们需要导入os来进行路径拼接,Json反序列化用来读取文件,还有就是导入公共层下的基础路径



config层:
配置文件存储目录
run层:
运行层,主要是运行测试用例的目录,我们可以根据测试模块来运行,也可以运行所有的模块,该层的内容也适用于所有场景(适用的前提是po设计模式的目录结构如上所示)
测试报告:
1 import time
2 # 时间
3 import unittest
4 # 加载测试模块
5 import os
6 # 处理路径
7 import HTMLTestRunner
8 # 生成测试报告必须要用的库
9 def getSuite():
10 # start_dir=加载所有的测试模块来执行,pattern=通过正则的模式加载所有的模块
11 '''获取所有执行的测试模块'''
12 suite = unittest.TestLoader().discover(
13 start_dir=os.path.dirname(__file__),
14 pattern='test_*.py'
15 )
16 return suite
17
18 # 获取当前时间
19 def getNowtime():
20 return time.strftime("%y-%m-%d %H_%M_%S",time.localtime(time.time()))
21
22 # 执行获取的测试模块,并获取测试报告
23 def main():
24 filename=os.path.join(os.path.dirname(__file__),'report',getNowtime()+"report.html")
25 # 把测试报告写入文件中,b是以二进制的方式写入
26 fp=open(filename,"wb")
27 # HTMLTestRunner实例化的过程,stream是流式写入,title是测试报告的标题,description是对测试报告的描述
28 runner=HTMLTestRunner.HTMLTestRunner(
29 stream=fp,
30 title="UI自动化测试报告",
31 description="UI自动化测试报告"
32 )
33 runner.run(getSuite())
34 if __name__=="__main__":
35 main()report:
主要用于存放测试报告
结语
这篇贴子到这里就结束了,最后,希望看这篇帖子的朋友能够有所收获。
PO模式教程获取方式:留言【po模式学习】即可文章来源:https://www.toymoban.com/news/detail-433402.html
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!文章来源地址https://www.toymoban.com/news/detail-433402.html
到了这里,关于让自动化测试秒杀繁琐操作?试试PO模式设计框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!