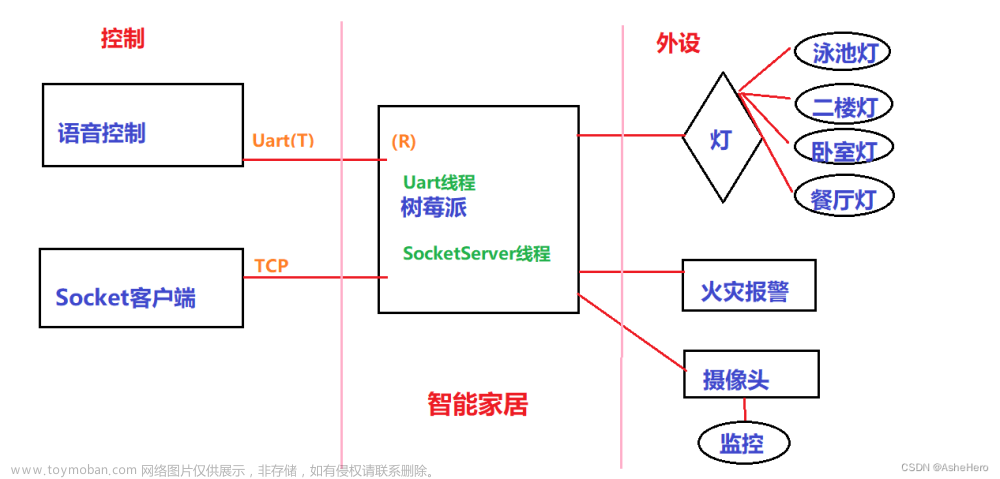
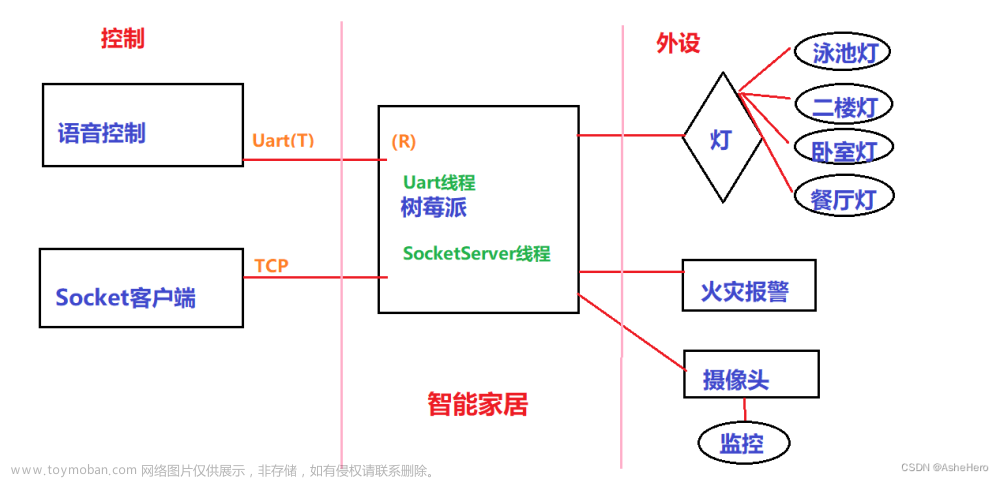
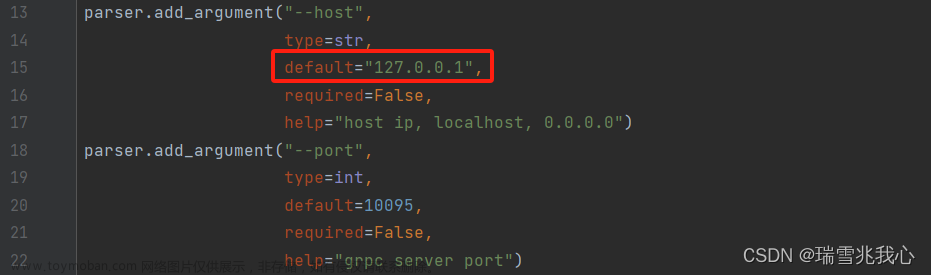
一、背景描述
vosk是一个开源语音识别工具,可识别中文,之前介绍过python使用vosk进行中文语音识别,今天记录下FreeSWITCH对接vosk实现实时语音识别。二、具体实现
1、编译及安装vosk模块
https://github.com/alphacep/freeswitch.git

这里描述下使用FreeSWITCH 1.10.9 编译 mod_vosk 的过程,大致步骤如下:
1)将 mod_vosk 代码复制到 freeswitch-1.10.9.-release/src/mod/asr_tts 目录;
2)modules.conf 文件中启用mod_vosk模块;

3)生成 Makefile 文件;
./devel-bootstrap.sh && ./configure
4) 编译并安装 vosk 模块;
cd freeswitch-1.10.9.-release/src/mod/asr_tts/mod_vosk make make install

fs编译遇到问题,可参考这篇文章:CentOS7环境源码安装freeswitch1.10
2、配置 vosk 模块
1)启用 vosk 模块;
编辑 autoload_configs/modules.conf.xml 文件,启用 vosk 模块:
<load module="mod_vosk"/>
2)配置 conf 文件;
将 mod_vosk/conf/vosk.conf.xml 配置文件复制到 如下路径:
/usr/local/freeswitch/conf/autoload_configs/
修改 vosk 服务器地址:

三、运行效果
1、启动 vosk 服务器
目录:vosk-server\websocket
启动命令如下:
workon py39env python asr_server.py vosk-model-cn-0.15
运行效果如下:

具体可参考我之前写的文章:python使用vosk进行中文语音识别
2、实时语音识别
编写拨号方案:
<condition field="destination_number" expression="^123456$"> <action application="answer"/> <action application="set" data="fire_asr_events=true"/> <action application="detect_speech" data="vosk default default"/> <action application="sleep" data="10000000"/> </condition>
本地分机拨打123456进行验证,运行效果如下:

运行效果视频获取途径:
3、回铃音识别
这里使用其它服务器配合来模拟回铃音。<extension name="public_extensions"> <condition field="destination_number" expression="^(654321)$"> <action application="pre_answer"/> <action application="set" data="ringback=/usr/local/freeswitch/sounds/test/tips1.wav"/> <action application="transfer" data="1008 XML default"/> </condition> </extension>
需要注意的是,如果回铃音不生效,可以看下后续的拨号方案是否有替换动作。
3.2 配置网关
网关配置信息:
[root@host32 conf]# cat sip_profiles/external/gw_a.xml <include> <gateway name="gw_A"> <param name="username" value="anonymous"/> <param name="from-user" value=""/> <param name="password" value=""/> <param name="outbound-proxy" value="192.168.137.31:5080"/> <param name="register-proxy" value="192.168.137.31:5080"/> <param name="expire-seconds" value="120"/> <param name="register" value="false"/> <param name="register-transport" value="UDP"/> <param name="caller-id-in-from" value="true"/> <param name="extension-in-contact" value="true"/> <variables> <variable name="gateway_name" value="gw_A"/> </variables> </gateway> </include> [root@host32 conf]#
3.3 编写本地拨号方案
本地拨号方案:
<condition field="destination_number" expression="^9123456$"> <action application="bridge" data="{ignore_early_media=false,bridge_early_media=true,fire_asr_events=true,execute_on_pre_answer='detect_speech vosk default default'}sofia/gateway/gw_A/654321"/> </condition>
本地分机拨打9123456,可听到回铃音,识别效果如下:

运行效果视频获取途径:
关注微信公众号(聊聊博文,文末可扫码)后回复 2023050402 获取。
四、资源下载
本文涉及源码及预编译模块二进制文件,可以从如下途径获取:文章来源:https://www.toymoban.com/news/detail-433605.html
 文章来源地址https://www.toymoban.com/news/detail-433605.html
文章来源地址https://www.toymoban.com/news/detail-433605.html
到了这里,关于FreeSWITCH对接vosk实现实时语音识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!