1、红酒数据介绍
经典的红酒分类数据集是指UCI机器学习库中的Wine数据集。该数据集包含178个样本,每个样本有13个特征,可以用于分类任务。
具体每个字段的含义如下:
alcohol:酒精含量百分比
malic_acid:苹果酸含量(克/升)
ash:灰分含量(克/升)
alcalinity_of_ash:灰分碱度(以mEq/L为单位)
magnesium:镁含量(毫克/升)
total_phenols:总酚含量(以毫克/升为单位)
flavanoids:类黄酮含量(以毫克/升为单位)
nonflavanoid_phenols:非类黄酮酚含量(以毫克/升为单位)
proanthocyanins:原花青素含量(以毫克/升为单位)
color_intensity:颜色强度(以 absorbance 为单位,对应于 1cm 路径长度处的相对宽度)
hue:色调,即色彩的倾向性或相似性(在 1 至 10 之间的一个数字)
od280/od315_of_diluted_wines:稀释葡萄酒样品的光密度比值,用于测量葡萄酒中各种化合物的浓度
proline:脯氨酸含量(以毫克/升为单位),是一种天然氨基酸,与葡萄酒的品质和口感有关。
2、红酒数据集分析
2.1 加载红酒数据集
# 加载红酒数据集
wineBunch = load_wine()
type(wineBunch)
sklearn.utils.Bunch
sklearn.utils.Bunch是Scikit-learn库中的一个数据容器,类似于Python字典(dictionary),
它可以存储任意数量和类型的数据,并且可以使用点(.)操作符来访问数据。Bunch常用于存储机器学习模型的数据集,
例如描述特征矩阵的数据、相关联的目标向量、特征名称等等,以便于组织和传递这些数据到模型中进行训练或预测。
2.2 红酒数据集形状
len(wineBunch.data),len(wineBunch.target)
(178, 178)
2.3 红酒数据集打印前5行和后5行
featuresDf = pd.DataFrame(data=wineBunch.data, columns=wineBunch.feature_names) # 特征数据
labelDf = pd.DataFrame(data=wineBunch.target, columns=["target"]) # 标签数据
wineDf = pd.concat([featuresDf, labelDf], axis=1) # 横向拼接
wineDf.head(5).append(wineDf.tail(5)) # 打印首尾5行

2.4 红酒数据集列名
wineDf.columns
Index([‘alcohol’, ‘malic_acid’, ‘ash’, ‘alcalinity_of_ash’, ‘magnesium’,
‘total_phenols’, ‘flavanoids’, ‘nonflavanoid_phenols’,
‘proanthocyanins’, ‘color_intensity’, ‘hue’,
‘od280/od315_of_diluted_wines’, ‘proline’, ‘target’],
dtype=‘object’)
2.5 红酒数据集目标标签
print(wineDf.target.unique())
[0 1 2]
3、Transformer对红酒进行分类
3.1 Transformer介绍
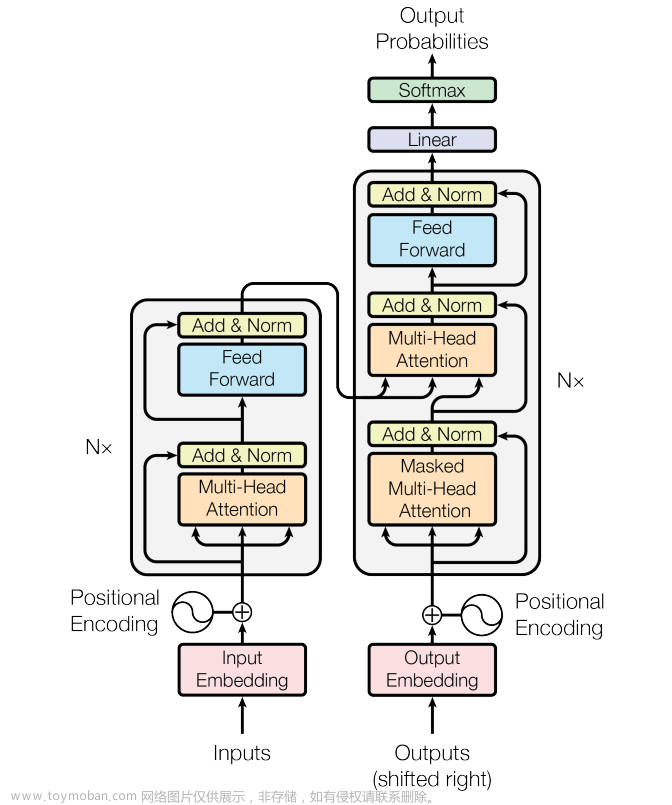
Transformer是一种基于注意力机制的神经网络结构,主要用于自然语言处理领域中的序列到序列转换任务,比如机器翻译、文本摘要等。它在2017年被Google提出,并被成功应用于Google Translate中。
Transformer的主要特点在于使用了完全基于注意力机制的编码器-解码器结构,避免了传统循环神经网络(如LSTM)中存在的长序列依赖问题和梯度消失问题。此外,Transformer还使用了残差连接和层归一化等技术,增强了模型的训练效果和泛化能力。
在Transformer模型中,输入序列和输出序列都被表示为固定长度的向量,称为词向量,由多个嵌入层和多个编码器和解码器层组成。其中,编码器和解码器层包括多头注意力机制、前馈神经网络和残差连接等模块,以实现对序列的有效建模和转换。
3.2 引入依赖库
import random # 导入 random 模块,用于随机数生成
import torch # 导入 PyTorch 模块,用于深度学习任务
import numpy as np # 导入 numpy 模块,用于数值计算
from torch import nn # 从 PyTorch 中导入神经网络模块
from sklearn import datasets # 从sklearn引入数据集
from sklearn.model_selection import train_test_split # 导入 sklearn 库中的 train_test_split 函数,用于数据划分
from sklearn.preprocessing import StandardScaler # 导入 sklearn 库中的 StandardScaler 类,用于数据标准化
3.3 设置随机种子
# 设置随机种子,让模型每次输出的结果都一样
seed_value = 42
random.seed(seed_value) # 设置 random 模块的随机种子
np.random.seed(seed_value) # 设置 numpy 模块的随机种子
torch.manual_seed(seed_value) # 设置 PyTorch 中 CPU 的随机种子
#tf.random.set_seed(seed_value) # 设置 Tensorflow 中随机种子
if torch.cuda.is_available(): # 如果可以使用 CUDA,设置随机种子
torch.cuda.manual_seed(seed_value) # 设置 PyTorch 中 GPU 的随机种子
torch.backends.cudnn.deterministic = True # 使用确定性算法,使每次运行结果一样
torch.backends.cudnn.benchmark = False # 不使用自动寻找最优算法加速运算
3.4 检测GPU是否可用
# 检测GPU是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
3.5 加载数据集
# 加载红酒数据集
wine = datasets.load_wine()
X = wine.data
y = wine.target
3.6 拆分训练集和测试集
# 拆分成训练集和测试集,训练集80%和测试集20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
3.7 缩放数据
# 缩放数据
scaler = StandardScaler() # 创建一个标准化转换器的实例
X_train = scaler.fit_transform(X_train) # 对训练集进行拟合(计算平均值和标准差)
X_test = scaler.transform(X_test) # 对测试集进行标准化转换,使用与训练集相同的平均值和标准差
3.8 转化成pytorch张量
# 将训练集转换为 PyTorch 张量,并转换为浮点数类型,如果 GPU 可用,则将张量移动到 GPU 上
X_train = torch.tensor(X_train).float().to(device)
# 将训练集转换为 PyTorch 张量,并转换为长整型,如果 GPU 可用,则将张量移动到 GPU 上
y_train = torch.tensor(y_train).long().to(device)
X_test = torch.tensor(X_test).float().to(device)
y_test = torch.tensor(y_test).long().to(device)
3.9 定义Transformer模型
定义 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, input_size, num_classes):
super(TransformerModel, self).__init__()
# 构建Transformer编码层,参数包括输入维度、注意力头数
# 其中d_model要和模型输入维度相同
self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_size, # 输入维度
nhead=1) # 注意力头数
# 构建Transformer编码器,参数包括编码层和层数
self.encoder = nn.TransformerEncoder(self.encoder_layer, # 编码层
num_layers=1) # 层数
# 构建线性层,参数包括输入维度和输出维度(num_classes)
self.fc = nn.Linear(input_size, # 输入维度
num_classes) # 输出维度
def forward(self, x):
#print("A:", x.shape) # torch.Size([142, 13])
x = x.unsqueeze(1) # 增加一个维度,变成(batch_size, 1, input_size)的形状
#print("B:", x.shape) # torch.Size([142, 1, 13])
x = self.encoder(x) # 输入Transformer编码器进行编码
#print("C:", x.shape) # torch.Size([142, 1, 13])
x = x.squeeze(1) # 压缩第1维,变成(batch_size, input_size)的形状
#print("D:", x.shape) # torch.Size([142, 13])
x = self.fc(x) # 输入线性层进行分类预测
#print("E:", x.shape) # torch.Size([142, 3])
return x
# 初始化Transformer模型,并移动到GPU
model = TransformerModel(input_size=13, # 输入维度
num_classes=3).to(device) # 输出维度
3.10 定义损失函数和优化器
定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 定义损失函数-交叉熵损失函数
定义优化器
optimizer = torch.optim.Adam(model.parameters(), # 模型参数
lr=0.01) # 学习率文章来源:https://www.toymoban.com/news/detail-433719.html
3.11 训练模型
# 训练模型
num_epochs = 100 # 训练100轮
for epoch in range(num_epochs):
# 正向传播:将训练数据放到模型中,得到模型的输出
outputs = model(X_train)
loss = criterion(outputs, y_train) # 计算交叉熵损失
# 反向传播和优化:清零梯度、反向传播计算梯度,并根据梯度更新模型参数
optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 根据梯度更新模型参数
# 每10轮打印一次损失值,查看模型训练的效果
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
3.12 测试模型
# 测试模型,在没有梯度更新的情况下,对测试集进行推断
with torch.no_grad():
outputs = model(X_test) # 使用训练好的模型对测试集进行预测
_, predicted = torch.max(outputs.data, 1) # 对输出的结果取 argmax,得到预测概率最大的类别
accuracy = (predicted == y_test).sum().item() / y_test.size(0) # 计算模型在测试集上的准确率
print(f'Test Accuracy: {accuracy:.2f}') # 打印测试集准确率
3.13 控制输出
Epoch [10/100], Loss: 0.1346
Epoch [20/100], Loss: 0.0325
Epoch [30/100], Loss: 0.0116
Epoch [40/100], Loss: 0.0064
Epoch [50/100], Loss: 0.0040
Epoch [60/100], Loss: 0.0029
Epoch [70/100], Loss: 0.0026
Epoch [80/100], Loss: 0.0021
Epoch [90/100], Loss: 0.0019
Epoch [100/100], Loss: 0.0019
Test Accuracy: 1.00
Process finished with exit code 0
正确率:100%文章来源地址https://www.toymoban.com/news/detail-433719.html
3.14 保存模型
# 保存模型
PATH = "model.pt"
torch.save(model.state_dict(), PATH)
3.15 加载模型
加载模型
model = Net()
model.load_state_dict(torch.load(PATH))
model.eval()
到了这里,关于Python使用pytorch深度学习框架构造Transformer神经网络模型预测红酒分类例子的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!