1. Sharding-JDBC 分片策略
分片操作是分片键 + 分片算法,也就是分片策略。目前Sharding-JDBC 支持多种分片策略:
- 标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。 - 复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。 - 行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。 - Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
具体的请参考官方文档:sharding分片策略
2. Sharding-JDBC 分片算法
分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前 Sharding-JDBC提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
-
精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。 -
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。 -
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。 -
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
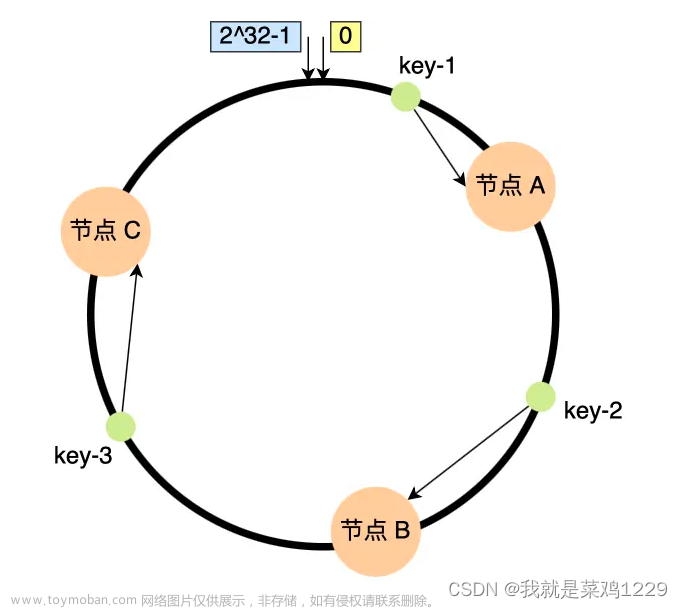
3. 自定义一致性哈希算法实践
什么是一致性哈希算法 请看这篇博客:文章来源:https://www.toymoban.com/news/detail-433934.html
- 首先实现ShardingJDBC提供的接口:
- PreciseShardingAlgorithm:精确分片算法,如果使用 == 来判定分片的情况,需要实现这个接口。
- RangeShardingAlgorithm:范围分片,如果有使用范围查找的话,需要使用这个进行分片策略。
/**
* 自定义哈希算法 + 虚拟节点实现数据分片
* 使用FNV1_32_HASH算法计算key的Hash值
* 也可以使用 MurmurHash3 或者别的加密方式
* @author manji
* @Date 2023/5/4
*/
public class ConsistenceHashAlgorithm implements RangeShardingAlgorithm<Long>, PreciseShardingAlgorithm<Long> {
/**
* 范围查找时需要用到改分片算法,这里暂不完善了
* @param collection
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
System.out.println(collection);
System.out.println(rangeShardingValue);
return collection;
}
/**
* @param collection collection 配置文件中解析到的所有分片节点
* @param preciseShardingValue 解析到的sql值
* @return
*/
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
System.out.println(collection);
InitTableNodesToHashLoop initTableNodesToHashLoop = SpringUtils.getBean(InitTableNodesToHashLoop.class);
if (CollectionUtils.isEmpty(collection)) {
return preciseShardingValue.getLogicTableName();
}
//这里主要为了兼容当联表查询时,如果两个表非关联表则
//当对副表分表时shardingValue这里传递进来的依然是主表的名称,
//但availableTargetNames中确是副表名称,所有这里要从availableTargetNames中匹配真实表
ArrayList<String> availableTargetNameList = new ArrayList<>(collection);
String logicTableName = availableTargetNameList.get(0).replaceAll("[^(a-zA-Z_)]", "");
SortedMap<Long, String> tableHashNode =
initTableNodesToHashLoop .getTableVirtualNodes().get(logicTableName);
ConsistenceHashUtil consistentHashAlgorithm = new ConsistenceHashUtil(tableHashNode,
collection);
return consistentHashAlgorithm.getTableNode(String.valueOf(preciseShardingValue.getValue()));
}
}
- 初始化hash环
注意:@Lazy 不添加的话会报错ShardingDataSource 找不到,因为在加载该类时,ShardingDataSource 还未放入容器中,所以获取不到,所以使用@Lazy 注解延后该类的加载。
/**
* 初始化hash环
* @author manji
* @Date 2023/5/4
*/
@Slf4j
@Component
@Lazy
public class InitTableNodesToHashLoop {
@Resource
private ShardingDataSource shardingDataSource;
@Getter
private HashMap<String, SortedMap<Long, String>> tableVirtualNodes = new HashMap<>();
@PostConstruct
public void init() {
try {
ShardingRule rule = shardingDataSource.getShardingContext().getShardingRule();
Collection<TableRule> tableRules = rule.getTableRules();
ConsistenceHashUtil consistenceHashUtil = new ConsistenceHashUtil();
for (TableRule tableRule : tableRules) {
String logicTable = tableRule.getLogicTable();
tableVirtualNodes.put(logicTable,
consistenceHashUtil.initNodesToHashLoop(
tableRule.getActualDataNodes()
.stream()
.map(DataNode::getTableName)
.collect(Collectors.toList()))
);
}
} catch (Exception e) {
log.error("分表节点初始化失败 {}", e);
}
}
}
- 一致性hash算法的核心代码
/**
* 一致性哈希算法工具类
* @author manji
* @Date 2023/5/4
*/
public class ConsistenceHashUtil {
//存储所有节点,按照hash值排序的
@Getter
private SortedMap<Long, String> virtualNodes = new TreeMap<>();
// 设置虚拟节点的个数
private static final int VIRTUAL_NODES = 3;
public ConsistenceHashUtil() {
}
public ConsistenceHashUtil(SortedMap<Long, String> virtualTableNodes, Collection<String> tableNodes) {
if (Objects.isNull(virtualTableNodes)) {
virtualTableNodes = initNodesToHashLoop(tableNodes);
}
this.virtualNodes = virtualTableNodes;
}
public SortedMap<Long, String> initNodesToHashLoop(Collection<String> tableNodes) {
SortedMap<Long, String> virtualTableNodes = new TreeMap<>();
for (String node : tableNodes) {
for (int i = 0; i < VIRTUAL_NODES; i++) {
String s = String.valueOf(i);
String virtualNodeName = node + "-manji" + s;
long hash = getHash(virtualNodeName);
virtualTableNodes.put(hash, virtualNodeName);
}
}
return virtualTableNodes;
}
/**
* 通过计算key的hash
* 计算映射的表节点
*
* @param key
* @return
*/
public String getTableNode(String key) {
String virtualNode = getVirtualTableNode(key);
//虚拟节点名称截取后获取真实节点
if (!StringUtils.isEmpty(virtualNode)) {
return virtualNode.substring(0, virtualNode.indexOf("-"));
}
return null;
}
/**
* 获取虚拟节点
* @param key
* @return
*/
public String getVirtualTableNode(String key) {
long hash = getHash(key);
// 得到大于该Hash值的所有Map
SortedMap<Long, String> subMap = virtualNodes.tailMap(hash);
String virtualNode;
if (subMap.isEmpty()) {
//如果没有比该key的hash值大的,则从第一个node开始
Long i = virtualNodes.firstKey();
//返回对应的服务器
virtualNode = virtualNodes.get(i);
} else {
//第一个Key就是顺时针过去离node最近的那个结点
Long i = subMap.firstKey();
//返回对应的服务器
virtualNode = subMap.get(i);
}
return virtualNode;
}
/**
* 使用FNV1_32_HASH算法计算key的Hash值
* 也可以使用 MurmurHash3 或者别的加密方式
* @param key
* @return
*/
public long getHash(String key) {
// return MurmurHash3.murmurhash3_x86_32(key);
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++)
hash = (hash ^ key.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
}
- 配置Sharding-JDBC的分片策略
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
#数据源
spring.shardingsphere.datasource.names = m1
#数据源1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/shardingdemo?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12345678
spring.shardingsphere.sharding.default-data-source-name=m1
# 指定user表的数据分布情况
spring.shardingsphere.sharding.tables.user.actual-data-nodes = m1.user_$->{0..2}
# 指定user表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.user.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name=com.manji.shardingdemo.consistencehasg.ConsistenceHashAlgorithm
# 打开sql输出日志
spring.shardingsphere.props.sql.show = true
代码demo地址:sharding-一致性哈希算法文章来源地址https://www.toymoban.com/news/detail-433934.html
到了这里,关于Sharding-JDBC 自定义一致性哈希算法 + 虚拟节点 实现数据库分片策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!