前言
如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
大模型的涌现能力 (Emergent Ability)
下图是模型性能(Loss for next token prediction)与「参数量」和「数据集大小」之间的关系,可以看出随着「参数量」和「数据集大小」不断变大,模型性能不断增强,仿佛不会遇到瓶颈。

下图展现了大模型的涌现能力,即语言模型的性能随着参数量增加并不是线性关系,而是突然跃升,即涌现。在未达到门槛之前,性能一直在随机的水平徘徊。


Calibration
在上面的实验图中,Calibration 指「模型置信度」与「真实概率」之间的关系,即满足「置信度高 -> 正确」、「置信度低 -> 可能错误」的模型,其 Calibration 指标越好。
因此 Calibration 实际上对应着「模型是否知道自己错了」这件事,如下图所示,不同参数量的模型对应不同的颜色,可以看到模型越大,其对自己是否出错的把握越大,即「模型置信度」与「真实概率」更为贴合。

Inverse Scaling Prize
一个比赛,奖金悬赏,寻找能让「模型越大,性能越差」的任务。

在这个比赛的任务中,许多之前的 “大模型” 随着参数量变大,其性能确实变差了,但当拿出更大的模型之后,其性能又好了起来,并产生了一段 U 型曲线。

这个比赛中的任务,一般都是「具体误导性的」,例如下述这个例子:

因此对于上述这种 U 型曲线,一种猜测是:这些任务里通常包含着一些误导任务,例如上述的 5 元,当模型还没有很大的时候,由于一知半解,就会接受被误导的方法,进而使其比随机效果还要差,但当其变得足够大时,就会得到真正的结果,类似于上述的计算期望值。

Switch Transformer
Switch Transformer 模型参数量为 1.6T(GPT-3 为 1750 亿,GPT-3.5 为 2000 亿),其使用了 Mixture-of-expert 的结构,即在模型推断(Inference)的时候,选取不同的 Module,进而加快推断速度。

大数据的重要性
足够大量的数据才能让模型学会「常识,即世界知识」,如下图所示,横坐标为数据量。
数据集准备过程:
- 过滤有害内容(google 安全搜索)
- 去除 HTML 标签
- 用规则去除低品质数据
- 去除重复数据
- 过滤出测试集(例如 GPT-3 就未过滤出测试集)

「大模型」还是「大数据」
在固定的运算资源时,应该优先「大模型」还是「大数据」?看目前的趋势,模型大小越来越大,但训练数据量并没有明显变化。

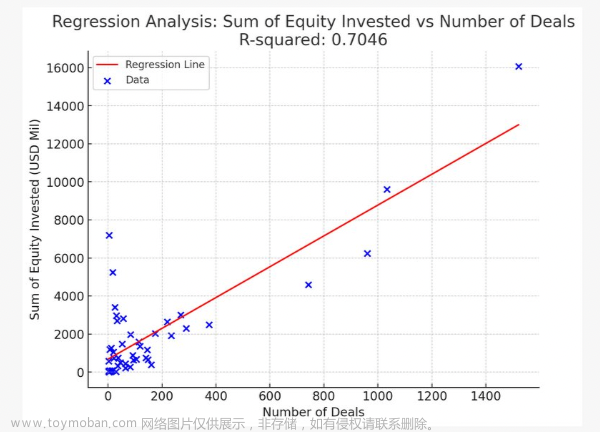
根据下图(颜色代表固定的运算资源,横坐标为参数量,参数量越大,数据量越小),可以发现「大模型」和「大数据」需要取得平衡,只增加模型大小,不增加算力,只会让训练结果变得更差。

每个 U 型曲线取一个最低点,得到下图所示的算力与参数量(Parameters)和数据量(Tokens)之间的关系。

根据上述估计图,Google 重新估计了 Gopher(参数量为 280 Billion,数据量为 300 Billion) 对应的算力下,应该采取的参数量和数据量方案,于是训练得到了 Chinchilla(参数量为 63 Billon,数据量为 1.4 Trillion)。对比之后,发现 Chinchilla 大胜 Gopher。

根据上述结果,进一步给出了具体的「参数量」与「数据量」之间的关系:

最新的 LLaMA 也采用了这种「减少参数量,扩大数据量」的方案:

KNN LM
通常来说,语言模型在做一个分类问题,即输入为「清华大」,输出为各个候选词的概率,随后选出概率最高的词即可。
如下所示,Transformer 得到 Text 的 Embedding,随后通过线性层 + softmax 转换为分类问题。
与之对比,KNN LM 在得到 Repesentation 后,不仅训练了一个分类器,还将测试 Text 的 Repesentation 与训练数据得到的 Repesentation 进行距离计算,并根据距离得到下一个词的预测概率,再与原始分类器结合起来,得到最终结果。文章来源:https://www.toymoban.com/news/detail-434507.html

另外,KNN LM 可以拿任意资料与测试 Text 的 Representation 计算距离,并不局限于训练数据。因此 KNN LM 这种机制可以使模型训练时更专注于一些难度更高的问题,对于一些仅需记忆的问题则可以通过这种方式解决。文章来源地址https://www.toymoban.com/news/detail-434507.html
参考资料
- Hung-yi Lee:生成式 AI(一)
- Scaling Laws for Neural Language Models
- Emergent Abilities of Large Language Models
- Inverse scaling can become U-shaped
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- When Do You Need Billions of Words of Pretraining Data?
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- Deduplicating Training Data Makes Language Models Better
- Training Compute-Optimal Large Language Models
- Scaling Instruction-Finetuned Language Models
- Introduction of ChatGPT
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Ggeneralization Through Memorization: Nearest Neighbor Language Models
- Language Is Not All You Need: Aligning Perception with Language Models
到了这里,关于生成式 AI 分析:大模型 + 大量数据的神奇效果的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!