文章来源地址https://www.toymoban.com/news/detail-434567.html
文章来源:https://www.toymoban.com/news/detail-434567.html
到了这里,关于Spark大数据处理讲课笔记3.5 RDD持久化机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了Spark大数据处理讲课笔记3.5 RDD持久化机制。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-434567.html
文章来源:https://www.toymoban.com/news/detail-434567.html
到了这里,关于Spark大数据处理讲课笔记3.5 RDD持久化机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

目录 零、本讲学习目标 一、Spark SQL (一)Spark SQL概述 (二)Spark SQL功能 (三)Spark SQL结构 1、Spark SQL架构图 2、Spark SQL三大过程 3、Spark SQL内部五大组件 (四)Spark SQL工作流程 (五)Spark SQL主要特点 1、将SQL查询与Spark应用程序无缝组合 2、Spark SQL以相同方式连接多种数据
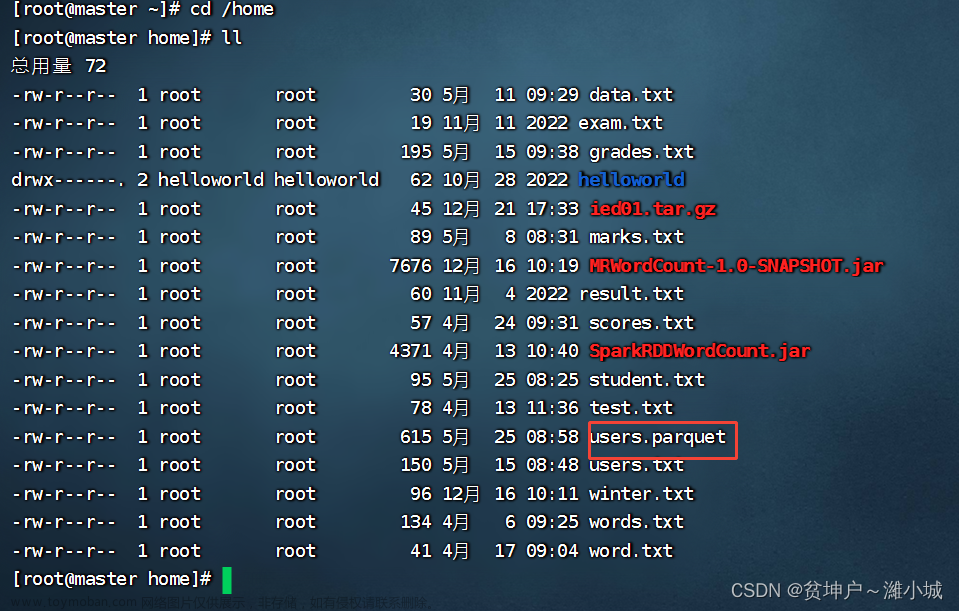
目录 零、本讲学习目标 一、基本操作 二、默认数据源 (一)默认数据源Parquet (二)案例演示读取Parquet文件 1、在Spark Shell中演示 2、通过Scala程序演示 三、手动指定数据源 (一)format()与option()方法概述 (二)案例演示读取不同数据源 1、读取房源csv文件 2、读取json,保
文章目录 一、准备工作 1.1 准备文件 1.1.1 准备本地系统文件 在/home目录里创建test.txt 单词用空格分隔 1.1.2 启动HDFS服务 执行命令:start-dfs.sh 1.1.3 上传文件到HDFS 将test.txt上传到HDFS的/park目录里 查看文件内容 1.2 启动Spark Shell 1.2.1 启动Spark服务 执行命令:start-all.sh 1.2.2 启动Sp
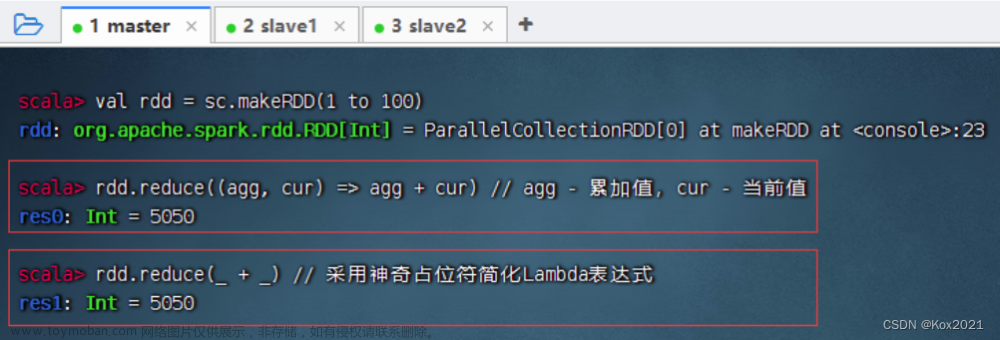
衔接上文:http://t.csdn.cn/Z0Cfj 功能: reduce()算子按照传入的函数进行归约计算 案例: 计算1 + 2 + 3 + …+100的值 计算1 × 2 × 3 × 4 × 5 × 6 的值(阶乘 - 累乘) 计算1 2 + 2 2 + 3 2 + 4 2 + 5**2的值(先映射,后归约) 功能: collect()算子向Driver以数组形式返回数据集的所有元素。通常对
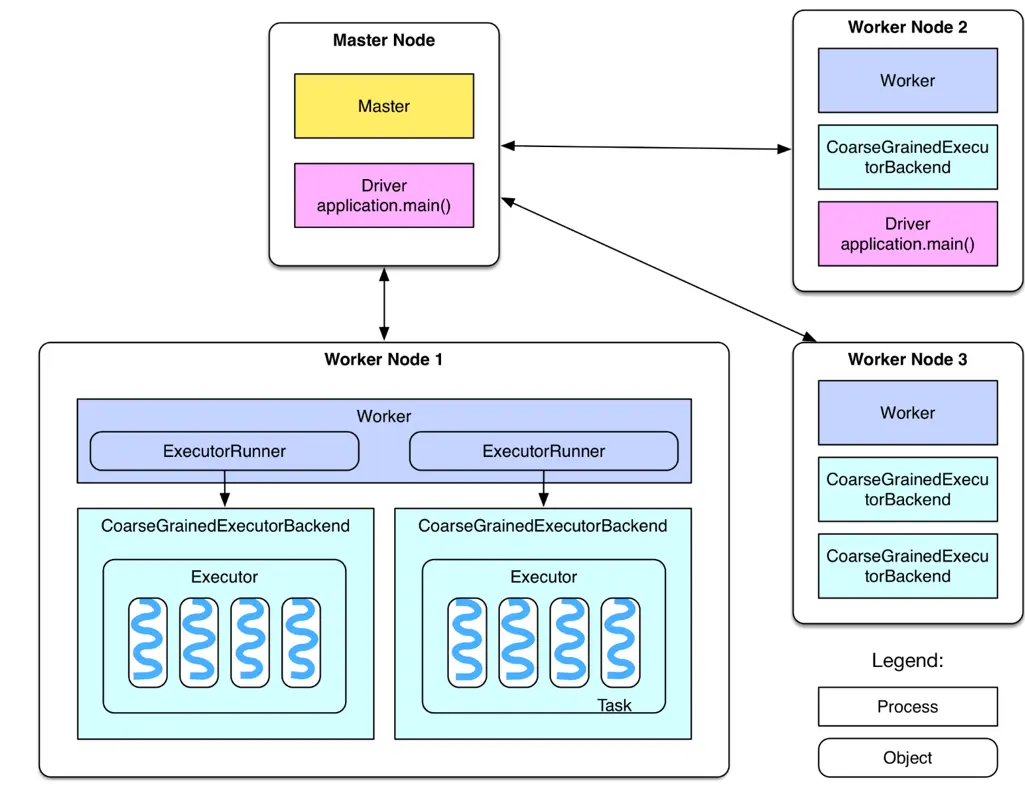
之前笔者参加了公司内部举办的一个 Big Data Workshop,接触了一些 Spark 的皮毛,后来在工作中陆陆续续又学习了一些 Spark 的实战知识。 本文笔者从小白的视角出发,给大家普及 Spark 的应用知识。 Spark 集群是基于 Apache Spark 的分布式计算环境,用于处理 大规模数据集 的计算任
一、RDD持久化 (一)引入持久化的必要性 Spark中的RDD是懒加载的,只有当遇到行动算子时才会从头计算所有RDD,而且当同一个RDD被多次使用时,每次都需要重新计算一遍,这样会严重增加消耗。为了避免重复计算同一个RDD,可以将RDD进行持久化。 Spark中重要的功能之一是可以

一、在master虚拟机上安装配置Spark 1.1 将spark安装包上传到master虚拟机 下载Spark:pyw2 进入/opt目录,查看上传的spark安装包 1.2 将spark安装包解压到指定目录 执行命令: tar -zxvf spark-3.3.2-bin-hadoop3.tgz 修改文件名:mv spark-3.3.2-bin-hadoop3 spark-3.3.2 1.3 配置spark环境变量 执行命令:vim

该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/0qE1L】 从Scala官网下载Scala2.12.15 - https://www.scala-lang.org/download/2.12.15.html 安装在默认位置 安装完毕 在命令行窗口查看Scala版本(必须要配置环境变量) 启动HDFS服务 启动Spark集群 在master虚拟机上创建单词文件
大家想了解更多大数据相关内容请移驾我的课堂: 大数据相关课程 剖析及实践企业级大数据 数据架构规划设计 大厂架构师知识梳理:剖析及实践数据建模 PySpark入坑系列第三篇,该篇章主要介绍spark的编程核心RDD的其他概念,依赖关系,持久化,广播变量,累加器等 在spa
前言:今天是温习 Spark 的第 4 天啦!主要梳理了 SparkSQL 工作中常用的操作大全,以及演示了几个企业级案例,希望对大家有帮助! Tips:\\\"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博



