这篇文章是对《动手深度学习》注意力机制部分的简单理解。
生物学中的注意力
生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于有意识的线索是想要读书,即使红色杯子比较突出,注意力依旧指向了书籍。

图一

图二
卷积层、全连接层、池化层就好像无意识的注意力,总是指向突出的特征;注意力机制有区别于此,它包含了有意识的注意力。
在注意力的背景下,有意识线索(想读书)被称为Query,无意识线索(杯子、书等)被称为Key,感官的输入(视觉接收到的无意识线索)称为Value,我们的目标是,通过有意识线索(Query)的引导,将注意力放到权重较大的输入(Value)上。
点积注意力


为什么相似度能衡量权重大小?直观来讲,我们在预测一个结果时,通过尽可能的了解与我们相似的人或事情,便对结果有了大致把握。想读书和书的相似度要比和水杯的高,因此注意力引导在书本而不是水杯。
至于为什么除以根号d?可以参考下面的解释。

图三

最后将得到的权重矩阵B与输入V点积,其结果为n×v维的矩阵,即每个查询通过权重矩阵B对输入V进行加权平均,得到预测的结果。这种加权平均,可以看作一种对输入信息的过滤或者是对输入信息的聚合。对,同池化层的作用,注意力机制可以看作一种带有意识线索的、有权重的池化层,它不会像最大池化层只留下明显的特征,也不会像平均池化层一视同仁的处理,而是根据查询,有轻重的保留特征。
目前为止,经过感性与理性的认识,应该大致清楚QKV各含义,李沐老师在视频里将了另一个更直观的例子帮助理解。
假设有一个人想要了解自己到新公司的薪资(Query), 他可以先了解在公司中其它人的情况(Key),其中与他具有相似技术、学历等特征的人权重当然比较大,反之则会小,那么通过对这些人的薪资(Value)做加权平均,可以估计得到我们想要(Query)的薪资(Value)。
点积自注意力
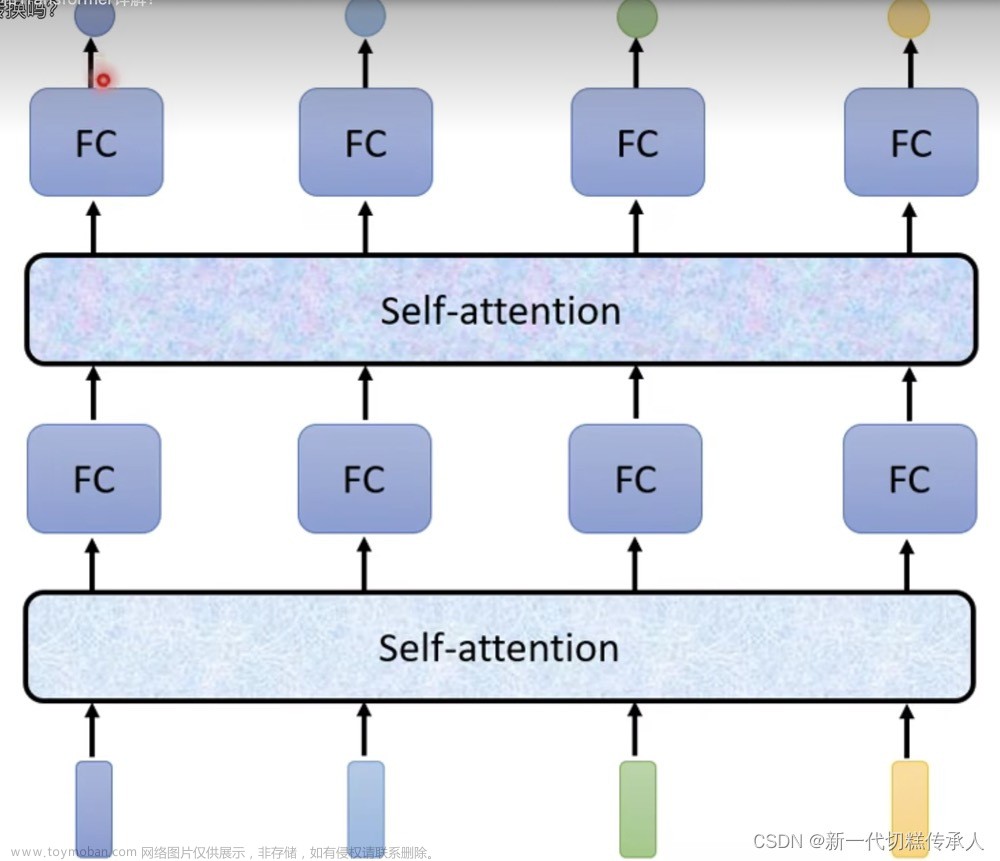
一般来说,Query,Key,Value 可以不相同,即使Key和Value相同是容易理解的。比如,上面的例子,Value仅指薪资,或者Value与key相同,薪资作为Key的一个属性,这都不妨碍得到想要的结果。但在Transformer的自注意力中,QKV均相同,Query是输入的tokens,Value也是输入的tokens,计算相似度矩阵也是在输入的tokens之间。因此,注意力计算的结果使得每个token融合了其它tokens的信息,实现全局信息交互,当然更多的是自己的信息。
多头自注意力

普遍认为的是,多头意味着有多组自注意力,多组QKV参数,多组参数学习token不同的特征部分,使得学习具有多样性,从而均衡一组QKV可能产生的偏差,当然多头自注意力也使得每组参数空间变小。
也有工作[2]认为,多层单头和多头都可以学习到不同子空间特征,但是多头训练更具有稳定性。如24层16头transformer(BERT-large)和384层单头transformer的总注意头数相同,模型尺寸大致相同,但是多头自注意力使得网络层数更浅,有利于训练。
参考
注意力机制 — 动手学深度学习 2.0.0 documentation (d2l.ai)
[2106.09650] Multi-head or Single-head? An Empirical Comparison for Transformer Training (arxiv.org)
简单理解注意力机制 - 知乎 (zhihu.com)文章来源:https://www.toymoban.com/news/detail-435438.html
推荐文章
《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces (kexue.fm) 文章来源地址https://www.toymoban.com/news/detail-435438.html
到了这里,关于简单理解Transformer注意力机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!