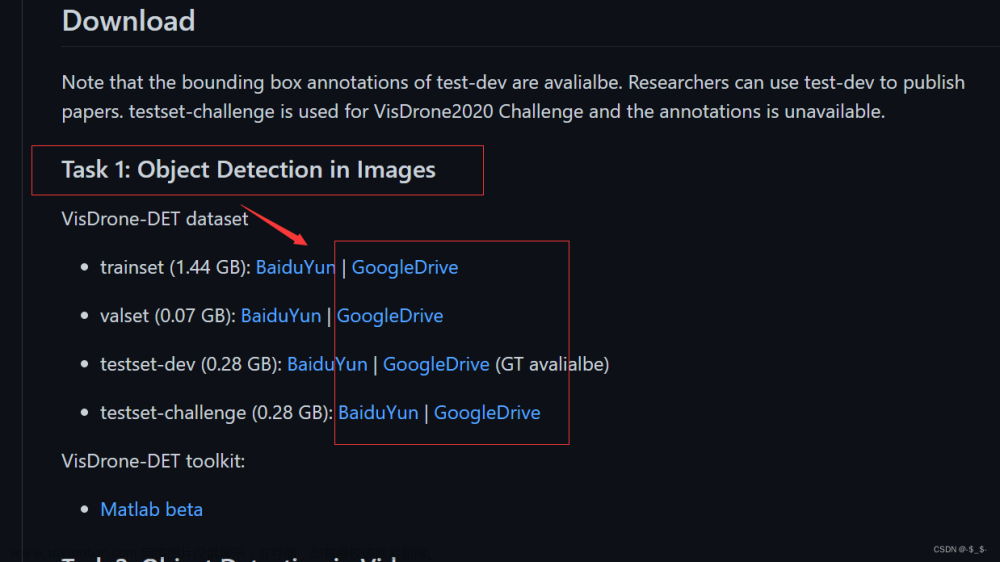
数据集
数据集目录如上,VOC数据集的格式
- JPEGImages目录下,放上自己的训练集和测试集

- Annotations 下,放上自己的xml文档配置,如上。
在VOCdevkit\VOC2012\ImageSets\Main下,放上自己的train.txt和val.txt,

上面,我按照VOC的格式来的,前面是所有的XML,因为VOC有21类,这里有我懒的删除,刚好前面代表XML文件,后面代表这张图片中有多少该目标,-1表示没有。
这样的话,数据就准备好了。
准备一个json,文件,选择自己需要分类的目标。
数据的读取
from torch.utils.data import Dataset
import os
import torch
import json
from PIL import Image
from lxml import etree
class VOC2012DataSet(Dataset):
"""读取解析PASCAL VOC2012数据集"""
def __init__(self, voc_root, transforms, txt_name: str = "train.txt",json_name="pascal_voc_classes.json"):
self.root = os.path.join(voc_root, "VOCdevkit", "VOC2012")
self.img_root = os.path.join(self.root, "JPEGImages")
self.annotations_root = os.path.join(self.root, "Annotations")
# read train.txt or val.txt file
txt_path = os.path.join(self.root, "ImageSets", "Main", txt_name)
assert os.path.exists(txt_path), "not found {} file.".format(txt_name)
with open(txt_path) as read:
self.xml_list = [os.path.join(self.annotations_root, line.strip().split()[0] + ".xml")
for line in read.readlines() if line.strip().split()[1] !="-1"]
# print(self.xml_list)
# check file
assert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path)
for xml_path in self.xml_list:
assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path)
# read class_indict
try:
json_file = open(json_name, 'r')
self.class_dict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
self.transforms = transforms
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
img_path = os.path.join(self.img_root, data["filename"])
image = Image.open(img_path)
if image.format != "JPEG":
raise ValueError("Image format not JPEG")
boxes = []
labels = []
iscrowd = []
for obj in data["object"]:
if obj["name"] in self.class_dict.keys():
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
iscrowd.append(int(obj["difficult"]))
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def get_height_and_width(self, idx):
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
data_height = int(data["size"]["height"])
data_width = int(data["size"]["width"])
return data_height, data_width
def parse_xml_to_dict(self, xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = self.parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def coco_index(self, idx):
"""
该方法是专门为pycocotools统计标签信息准备,不对图像和标签作任何处理
由于不用去读取图片,可大幅缩减统计时间
Args:
idx: 输入需要获取图像的索引
"""
# read xml
xml_path = self.xml_list[idx]
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = self.parse_xml_to_dict(xml)["annotation"]
data_height = int(data["size"]["height"])
data_width = int(data["size"]["width"])
# img_path = os.path.join(self.img_root, data["filename"])
# image = Image.open(img_path)
# if image.format != "JPEG":
# raise ValueError("Image format not JPEG")
boxes = []
labels = []
iscrowd = []
for obj in data["object"]:
if obj["name"] in self.class_dict.keys():
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
iscrowd.append(int(obj["difficult"]))
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
return (data_height, data_width), target
@staticmethod
def collate_fn(batch):
return tuple(zip(*batch))
if __name__ == '__main__':
data = VOC2012DataSet(r"D:/",transforms=None,txt_name="car_train.txt",json_name="car_class.json")
for i in data:
print(i)
注意一下,倒数的这几行
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
其实最重要的是boxes和labels,其他的都可以不要
VOC2012DataSet(r"D:/",transforms=None,txt_name="car_train.txt",json_name="car_class.json")
依次代表的是路径,图像增强,训练集文件名以及对应的目标。
训练文件
import os
import torch
import my_transforms as transforms
from network_files.faster_rcnn_framework import FasterRCNN, FastRCNNPredictor
from backbone.resnet50_fpn_model import resnet50_fpn_backbone
from my_dataset import VOC2012DataSet
from train_utils import train_eval_utils as utils
from torch.utils.data import DataLoader
def create_model(num_classes:int, device):
backbone = resnet50_fpn_backbone()
# 训练自己数据集时不要修改这里的91,修改的是传入的num_classes参数
model = FasterRCNN(backbone=backbone, num_classes=91)
# 载入预训练模型权重
weights_dict = torch.load("./backbone/fasterrcnn_resnet50_fpn_coco.pth", map_location=device)
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
def main(parser_data):
device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")
print("Using {} device training.".format(device.type))
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
VOC_root = parser_data.data_path
# check voc root
if os.path.exists(os.path.join(VOC_root, "VOCdevkit")) is False:
raise FileNotFoundError("VOCdevkit dose not in path:'{}'.".format(VOC_root))
# load train data set
# VOCdevkit -> VOC2012 -> ImageSets -> Main -> train.txt
train_data_set = VOC2012DataSet(VOC_root, data_transform["train"], args.train_txt,args.json_name)
# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batch
batch_size = parser_data.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using %g dataloader workers' % nw)
train_data_loader = DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
# load validation data set
# VOCdevkit -> VOC2012 -> ImageSets -> Main -> val.txt
val_data_set = VOC2012DataSet(VOC_root, data_transform["val"], args.val_txt,args.json_name)
val_data_set_loader = DataLoader(val_data_set,
batch_size=batch_size,
shuffle=False,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
# create models num_classes equal background + 20 classes
# print(args.num_classes)
model = create_model(num_classes=args.num_classes, device=device)
# print(models)
model.to(device)
# print(model)
# exit()
# define optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.33)
# 如果指定了上次训练保存的权重文件地址,则接着上次结果接着训练
if parser_data.resume != "":
checkpoint = torch.load(parser_data.resume, map_location=device)
model.load_state_dict(checkpoint['models'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
parser_data.start_epoch = checkpoint['epoch'] + 1
print("the training process from epoch{}...".format(parser_data.start_epoch))
train_loss = []
learning_rate = []
val_mAP = []
for epoch in range(parser_data.start_epoch, parser_data.epochs):
# train for one epoch, printing every 10 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, train_loss=train_loss, train_lr=learning_rate,
print_freq=50, warmup=True)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
utils.evaluate(model, val_data_set_loader, device=device, mAP_list=val_mAP)
# save weights
save_files = {
'models': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch}
torch.save(save_files, "./save_weights/resNetFpn-models-{}.pth".format(epoch))
# plot loss and lr curve
if len(train_loss) != 0 and len(learning_rate) != 0:
from plot_curve import plot_loss_and_lr
plot_loss_and_lr(train_loss, learning_rate)
# plot mAP curve
if len(val_mAP) != 0:
from plot_curve import plot_map
plot_map(val_mAP)
if __name__ == "__main__":
version = torch.version.__version__[:5] # example: 1.6.0
# 因为使用的官方的混合精度训练是1.6.0后才支持的,所以必须大于等于1.6.0
if version < "1.6.0":
raise EnvironmentError("pytorch version must be 1.6.0 or above")
import argparse
parser = argparse.ArgumentParser(
description=__doc__)
# 训练设备类型
parser.add_argument('--device', default='cuda:0', help='device')
# 训练数据集的根目录
parser.add_argument('--data-path', default=r'D:/', help='dataset')
# 文件保存地址
parser.add_argument('--output-dir', default='./save_weights', help='path where to save')
# 若需要接着上次训练,则指定上次训练保存权重文件地址
parser.add_argument('--resume', default='', type=str, help='resume from checkpoint')
# 指定接着从哪个epoch数开始训练
parser.add_argument('--start_epoch', default=0, type=int, help='start epoch')
# 训练的总epoch数
parser.add_argument('--epochs', default=15, type=int, metavar='N',
help='number of total epochs to run')
# 训练的batch size
parser.add_argument('--batch_size', default=2, type=int, metavar='N',
help='batch size when training.')
# parser.add_argument('--json_name', default="pascal_voc_classes.json", type=str, metavar='N',
# help='the num of classes')
# parser.add_argument('--train_txt', default="train.txt", type=str, metavar='N',
# )
# parser.add_argument('--val_txt', default="val.txt", type=str, metavar='N',
# )
parser.add_argument('--num_classes', default=2, type=int, metavar='N',
help='the num of classes')
parser.add_argument('--json_name', default="car_class.json", type=str, metavar='N',
help='the num of classes')
parser.add_argument('--train_txt', default="car_train.txt", type=str, metavar='N',
)
parser.add_argument('--val_txt', default="car_val.txt", type=str, metavar='N',
)
args = parser.parse_args()
print(args)
# 检查保存权重文件夹是否存在,不存在则创建
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
main(args)
只需要自改最后几行,分类数,json名字,训练数据文件名,测试数据文件名文章来源:https://www.toymoban.com/news/detail-435467.html
预测文件
import os
import time
import json
import torch
import torchvision
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
from network_files.faster_rcnn_framework import FasterRCNN, FastRCNNPredictor
from backbone.resnet50_fpn_model import resnet50_fpn_backbone
from backbone.resnet152_fpn_model import resnet152_fpn_backbone
from network_files.rpn_function import AnchorsGenerator
# from backbone.mobilenetv2_model import MobileNetV2
from draw_box_utils import draw_box
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def create_model(num_classes):
# mobileNetv2+faster_RCNN
# backbone = MobileNetV2().features
# backbone.out_channels = 1280
#
# anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
# aspect_ratios=((0.5, 1.0, 2.0),))
#
# roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
# output_size=[7, 7],
# sampling_ratio=2)
#
# models = FasterRCNN(backbone=backbone,
# num_classes=num_classes,
# rpn_anchor_generator=anchor_generator,
# box_roi_pool=roi_pooler)
# resNet50+fpn+faster_RCNN
# backbone = resnet50_fpn_backbone()
backbone = resnet50_fpn_backbone()
model = FasterRCNN(backbone=backbone, num_classes=num_classes)
return model
def main():
# get devices
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# create models
model = create_model(num_classes=2)
# load train weights
train_weights = "./save_weights/resNetFpn-models-car.pth"
assert os.path.exists(train_weights), "{} file dose not exist.".format(train_weights)
model.load_state_dict(torch.load(train_weights, map_location=device)["models"])
model.to(device)
# read class_indict
label_json_path = './car_class.json'
assert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)
json_file = open(label_json_path, 'r')
class_dict = json.load(json_file)
category_index = {v: k for k, v in class_dict.items()}
# load image
for img in os.listdir("./test_image"):
img_head = img.split(".")[0]
original_img = Image.open(os.path.join("./test_image", img))
# from pil image to tensor, do not normalize image
data_transform = transforms.Compose([transforms.ToTensor()])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time.time()
predictions = model(img.to(device))[0]
print("inference+NMS time: {}".format(time.time() - t_start))
predict_boxes = predictions["boxes"].to("cpu").numpy()
predict_classes = predictions["labels"].to("cpu").numpy()
predict_scores = predictions["scores"].to("cpu").numpy()
if len(predict_boxes) == 0:
print("没有检测到任何目标!")
draw_box(original_img,
predict_boxes,
predict_classes,
predict_scores,
category_index,
thresh=0.8,
line_thickness=1)
plt.imshow(original_img)
plt.show()
# 保存预测的图片结果
original_img.save(f"{img_head}test_result.jpg")
if __name__ == '__main__':
main()
这里是主要修改的地方,FasterRcnn完整算法代码已上传csdn。
记录一下自己自定义数据集FasterRcnn,
链接: Faster代码下载.
欢迎有志之士一起交流。VX 文章来源地址https://www.toymoban.com/news/detail-435467.html
文章来源地址https://www.toymoban.com/news/detail-435467.html
到了这里,关于目标检测之FasterRcnn算法——训练自己的数据集(pytorch)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!