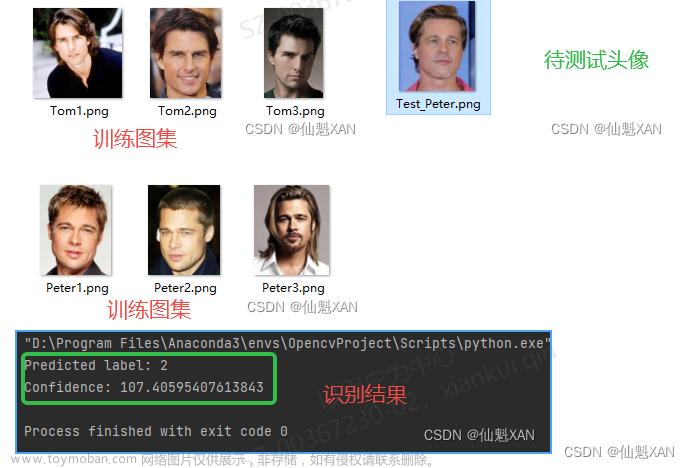
这学期在上《数字图像处理》这门课程,老师布置了几个大作业,自己和同学一起讨论完成后,感觉还挺有意思的,就想着把这个作业整理一下 :
目录
1.实验任务和要求
2.实验原理
3.实验代码
3.1利用人脸特征点检测工具dlib获取人脸关键点
目录
1.实验任务和要求
2.实验原理
3.实验代码
3.1利用人脸特征点检测工具dlib获取人脸关键点以及delaunay三角划分
3.2 实现人脸的warpping(几何变换)
3.3 实现两张人脸的morphing(渐变合成)
1.实验任务和要求
(1) 利用人脸特征点检测工具如dlib(http://dlib.net/)获得人脸关键点;
(2) 获得Delaunay Triangulation,可利用Opencv
(https://www.learnopencv.com/delaunay-triangulation-and-voronoi-diagram-using-opencv-c-python/)或matlab提供的delaunay函数;
(3) 自己编写triangle-to-triangle的几何变换(形变warp)函数,实现人脸Warping, 即表观属性(色彩,亮度,身份等)保持,仅变换几何属性,如人脸的胖瘦变化和角度变化,注意身份不变还是这个人;
(4)实现两幅人脸图像之间的几何属性交换和表观渐变合成视频Morphing,即从第一张人脸逐渐过渡到第二张人脸,几何属性(shape,view)和表观属性(illumination,color,identification等)都变了。
2.实验原理
实验原理方面,delaunay三角划分和其余原理均可以较轻松地在网上查到,故不再赘述,这里只列出进行仿射变换的原理:
根据人脸检测得到的特征点进行delaunay三角划分后,就需要对三角形逐个进行仿射变换了,具体原理如下:
给定两个三角形:ABC和A’B’C’,现在需要找到一个变换矩阵T来把ABC中的像素变换到A’B’C’中去。

图2.2.1 三角形仿射变换
假设ABC内一点坐标为(x,y),那么就需要找到其在A’B’C’中的对应点(x’,y’),然后把(x,y)点处的像素值赋值给(x’,y’)点即可。现在给定变换矩阵T,则变换公式如下:

公式2.2.2 仿射变换公式
其中, 即为变换矩阵T。
即为变换矩阵T。
当然,仿射变换有两种,分为前向仿射和后向仿射。前向仿射是根据(x,y)点的坐标寻找(x’,y’)点的坐标,根据公式2.2.3
(x’,y’)=T(x,y)
公式2.2.3 前向仿射变换公式
进行相应像素值的赋值;
 |
图2.2.4 前向仿射变换图示
后向仿射是根据(x’,y’)点的坐标寻找(x,y)点的坐标,根据公式2.2.5
(x,y)=T-1(x’,y’)
公式2.2.5 后向仿射变换公式
进行相应像素值的赋值。
图2.2.6 后向仿射变换图示
遍历三角形内的各个点,根据得到的仿射变换矩阵T或者是T-1寻找其在另一个三角形中对应的点,然后进行像素值的赋值即可。
3.实验代码
3.1利用人脸特征点检测工具dlib获取人脸关键点以及delaunay三角划分
注意:因为dlib官方给的是人脸68个关键点的检测,而在人脸图像的warpping的处理中,会涉及到整张图像,所以新增了8个关键点,分别对应着图像的四个角以及四个边的中间点,本代码将结果保存到了txt文件中:
import dlib
import cv2 as cv
import numpy as np
#dlib人脸特征点检测调用,返回值是68个检测点构成的一个列表
def character_point(image, save_path):
detector = dlib.get_frontal_face_detector() #使用dlib库提供的人脸提取器
predictor = dlib.shape_predictor('F:/BaiduNetdiskDownload/pictures/renlian/shape_predictor_68_face_landmarks.dat') #构建特征提取器
#注意,这个dat文件要放在和你代码相同的路径下
rects = detector(image,1) #rects表示人脸数 人脸检测矩形框4点坐标:左上角(x1,y1)、右下角(x2,y2)
f = open(save_path, 'w+')
points_lst = []
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(image,rects[i]).parts()]) #人脸关键点识别 landmarks:获取68个关键点的坐标
#shape=predictor(img,box) 功能:定位人脸关键点 img:一个numpy ndarray,包含8位灰度或RGB图像 box:开始内部形状预测的边界框
#返回值:68个关键点的位置
for idx, point in enumerate(landmarks): #enumerate函数遍历序列中的元素及它们的下标
# 68点的坐标
pos = (int(point[0, 0]), int(point[0, 1]))
#print(idx,pos)
points_lst.append(pos)
#将特征点写入txt文件中,方便后面使用
f.write(str(point[0, 0]))
f.write('\t')
f.write(str(point[0, 1]))
f.write('\n')
f.write(str(0))
f.write('\t')
f.write(str(0))
f.write('\n') #图像左上角的点
f.write(str(0))
f.write('\t')
f.write(str(image.shape[0]//2))
f.write('\n') #左边界中间的点
f.write(str(0))
f.write('\t')
f.write(str(image.shape[0]-1))
f.write('\n') #左下角的点
f.write(str(image.shape[1]//2))
f.write('\t')
f.write(str(0))
f.write('\n') #上边界中间的点
f.write(str(image.shape[1]//2))
f.write('\t')
f.write(str(image.shape[0]-1))
f.write('\n') #下边界中间的点
f.write(str(image.shape[1]-1))
f.write('\t')
f.write(str(0))
f.write('\n') #右上角的点
f.write(str(image.shape[1]-1))
f.write('\t')
f.write(str(image.shape[0]//2))
f.write('\n') #右边界中间的点
f.write(str(image.shape[1]-1))
f.write('\t')
f.write(str(image.shape[0]-1))
f.write('\n') #右下角的点
points_lst.append((0,0)) #图像左上角的点
points_lst.append((0,image.shape[0]//2)) #左边界中间的点
points_lst.append((0,image.shape[0]-1)) #左下角的点
points_lst.append((image.shape[1]//2,0)) #上边界中间的点
points_lst.append((image.shape[1]//2,image.shape[0]-1)) #下边界中间的点
points_lst.append((image.shape[1]-1,0)) #右上角的点
points_lst.append((image.shape[1]-1,image.shape[0]//2)) #右边界中间的点
points_lst.append((image.shape[1]-1,image.shape[0]-1)) #右下角的点
for i,item in enumerate(points_lst):
pos=item
#'''
# 利用cv2.circle给每个特征点画一个圈,共68个
cv.circle(image, pos, 2, color=(0, 255, 0))
#利用cv.putText输出1-68
#各参数依次是:图片,添加的文字,坐标,字体,字体大小,颜色,字体粗细
cv.putText(image, str(i), pos, cv.FONT_HERSHEY_PLAIN, 0.8, (0, 255, 0), 1,cv.LINE_AA)
#cv.namedWindow("img", point_detect)
cv.imshow("img", image) #显示图像
cv.waitKey(100) #等待按键,随后退出
#'''
#cv.imwrite('telangpu_point_detect',image)
f.close()
return points_lst,image
def rect_contains(rect, point):
if point[0] < rect[0]:
return False
elif point[1] < rect[1]:
return False
elif point[0] > rect[2]:
return False
elif point[1] > rect[3]:
return False
return True
#Draw delaunay triangles
def draw_delaunay(image, subdiv, delaunary_color,save_path,save_path_index):
f1=open(save_path_index,'w') #创建text文本,存入三角形三个顶点的索引
save_path_lst=[]
with open(save_path,'r') as f: #打开存有76个关键点的文件,放入列表中
for line in f:
x,y=line.split()
save_path_lst.append((int(x),int(y)))
triangleList = subdiv.getTriangleList()
for t in triangleList:
pt1 = (int(t[0]), int(t[1]))
pt2 = (int(t[2]), int(t[3]))
pt3 = (int(t[4]), int(t[5]))
if rect_contains(rect, pt1) and rect_contains(rect, pt2) and rect_contains(rect, pt3):
cv.line(image, pt1, pt2, delaunary_color, 1, cv.LINE_AA, 0)
cv.line(image, pt2, pt3, delaunary_color, 1, cv.LINE_AA, 0)
cv.line(image, pt3, pt1, delaunary_color, 1, cv.LINE_AA, 0)
for index,item in enumerate(save_path_lst):
if pt1==item:
f1.write(str(index))
f1.write('\t')
elif pt2==item:
f1.write(str(index))
f1.write('\t')
elif pt3==item:
f1.write(str(index))
f1.write('\t')
f1.write('\n')
f1.close()
#####################################
# 以下是主程序 #
#####################################
image = cv.imread("clinton.jpg") #读取图像
save_path1 = 'clinton1.txt' #将特征点保存入text文件中
point_list1,image1 = character_point(image, save_path1) #dlib人脸特征点检测调用,返回值是68个检测点构成的一个列表
save_path2='tri3_clinton.txt' #创建text文本,存入三角形三个顶点的索引
size = image.shape #使用矩形定义要区分的空间
rect = (0, 0, size[1], size[0])
subdiv = cv.Subdiv2D(rect) #创建 Subdiv2D 的实例
delaunary_color = (0, 0, 255) #使用红色画三角形
image_origin = image.copy() #拷贝一份图像
animate=True #当画三角形的时候打开动画
for p in point_list1:
subdiv.insert(p)
#显示动画
if animate :
img_copy = image_origin.copy()
# Draw delaunay triangles
draw_delaunay( img_copy, subdiv, (0, 0, 255) ,save_path1,save_path2);
cv.imshow('win_delaunay', img_copy)
k=cv.waitKey(100)
#if k==ord('s'):
#cv.destroyAllWindows()
draw_delaunay(image_origin, subdiv, delaunary_color,save_path1,save_path2);
#dim=(550,700)
#image_origin=cv.resize(image_origin,dim) #更改图像尺寸
cv.imshow('win_delaunay', image_origin)
#cv.imshow('win_0',image)
k=cv.waitKey(0)
if k==ord('s'):
cv.imwrite("after delaunary/'s image.jpg",image_origin)
cv.imwrite("clinton point detect.jpg",image1)
cv.destroyAllWindows()
结果显示:
人脸关键点检测:

delaunay三角划分:

3.2 实现人脸的warpping(几何变换)
下面这段代码,我把前面的人脸检测获取关键点和delaunay三角划分一起整合进来了,为的是构成单独的一个完整的代码,这样的话,关键点的坐标和三角形的索引就直接转化成了列表,不需要再次读入txt文件了:
import cv2
import numpy as np
#import matplotlib.pyplot as plt
import dlib
#################################################################
#定义读取坐标点函数
def readpoints(path):
points=[]
with open(path,'r') as f:
for line in f:
x,y=line.split()
x=int(x)
y=int(y)
points.append((x,y))
return points
#######################################################################
#dlib人脸特征点检测调用,返回值是68个检测点构成的一个列表
def character_point(image, save_path):
detector = dlib.get_frontal_face_detector() #使用dlib库提供的人脸提取器
predictor = dlib.shape_predictor(save_path) #构建特征提取器
rects = detector(image,1) #rects表示人脸数 人脸检测矩形框4点坐标:左上角(x1,y1)、右下角(x2,y2)
points_lst = []
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(image,rects[i]).parts()]) #人脸关键点识别 landmarks:获取68个关键点的坐标
#shape=predictor(img,box) 功能:定位人脸关键点 img:一个numpy ndarray,包含8位灰度或RGB图像 box:开始内部形状预测的边界框
#返回值:68个关键点的位置
for idx, point in enumerate(landmarks): #enumerate函数遍历序列中的元素及它们的下标
# 68点的坐标
pos = (int(point[0, 0]), int(point[0, 1]))
#print(idx,pos)
points_lst.append(pos)
points_lst.append((0,0)) #图像左上角的点
points_lst.append((0,image.shape[0]//2)) #左边界中间的点
points_lst.append((0,image.shape[0]-1)) #左下角的点
points_lst.append((image.shape[1]//2,0)) #上边界中间的点
points_lst.append((image.shape[1]//2,image.shape[0]-1)) #下边界中间的点
points_lst.append((image.shape[1]-1,0)) #右上角的点
points_lst.append((image.shape[1]-1,image.shape[0]//2)) #右边界中间的点
points_lst.append((image.shape[1]-1,image.shape[0]-1)) #右下角的点
return points_lst
######################################################################
#delaunay三角划分
def rect_contains(rect, point):
if point[0] < rect[0]:
return False
elif point[1] < rect[1]:
return False
elif point[0] > rect[2]:
return False
elif point[1] > rect[3]:
return False
return True
def get_delaunary(img,point_list):
size=img.shape
rect = (0, 0, size[1], size[0]) #使用矩形定义要区分的空间
subdiv = cv2.Subdiv2D(rect) #创建 Subdiv2D 的实例
for p in point_list:
subdiv.insert(p)
lst=[] #创建列表,存入三角形三个顶点的索引
triangleList = subdiv.getTriangleList()
for t in triangleList:
pt1 = (int(t[0]), int(t[1]))
pt2 = (int(t[2]), int(t[3]))
pt3 = (int(t[4]), int(t[5]))
if rect_contains(rect, pt1) and rect_contains(rect, pt2) and rect_contains(rect, pt3):
#cv2.line(image, pt1, pt2, delaunary_color, 1, cv2.LINE_AA, 0)
#cv2.line(image, pt2, pt3, delaunary_color, 1, cv2.LINE_AA, 0)
#cv2.line(image, pt3, pt1, delaunary_color, 1, cv2.LINE_AA, 0)
lst_1=[]
for index,item in enumerate(point_list):
if pt1==item:
lst_1.append(index)
elif pt2==item:
lst_1.append(index)
elif pt3==item:
lst_1.append(index)
lst.append(lst_1)
return lst
#######################################################################################
#仿射变换函数求取变换矩阵以及变换矩阵的应用
# 获得仿射变换矩阵
def getAffineTransform(srctri, dsttri):
srctri = np.float32(srctri)
dsttri = np.float32(dsttri)
srctri1 = []
for i in range(len(srctri)):
src = srctri[i]
src = list(src)
srctri1.append(src)
A = np.reshape(np.array(srctri1), (3, 2)) # 求出基于原始多边形顶点的坐标所组成的矩阵
dsttri1 = []
for i in range(len(dsttri)):
dst = dsttri[i]
dst = list(dst)
dst.append(1) #得出[x,y,1]的形式
dsttri1.append(dst)
B = np.reshape(np.array(dsttri1), (3, 3)) # 求出基于目标多边形顶点的坐标所组成的矩阵
MT= np.linalg.pinv(B).dot(A)
M=MT.T
return M
#计算三角形面积
def is_trangle_area(x1,y1,x2,y2,x3,y3):
return abs((x1*(y2-y3))+(x2*(y3-y1))+(x3*(y1-y2)))
#将仿射变换矩阵应用到图像中
def warpAffine(src,warpMat,size,dstTri):
dst=np.zeros((size[1],size[0],3),dtype=src.dtype)
x1=dstTri[0][0]
y1=dstTri[0][1]
x2=dstTri[1][0]
y2=dstTri[1][1]
x3=dstTri[2][0]
y3=dstTri[2][1]
abc=is_trangle_area(x1,y1,x2,y2,x3,y3)
#k=0
for j in range(dst.shape[0]):
for i in range(dst.shape[1]):
abp=is_trangle_area(x1,y1,x2,y2,i,j)
acp=is_trangle_area(x1,y1,x3,y3,i,j)
bcp=is_trangle_area(x2,y2,x3,y3,i,j)
if abc==abp+acp+bcp :
lst=[]
lst.append(i)
lst.append(j)
lst.append(1)
A=np.reshape(np.array(lst),(3,1)) #将列表转换为矩阵(3*1)
B=np.dot(warpMat,A) #应用仿射变换矩阵,得到仿射后的坐标
lst_dst=[]
lst1=list(B)
for index in range(len(lst1)):
lst_dst.append(lst1[index][0])
x=lst_dst[0]-1
y=lst_dst[1]-1
m=int(y)
n=int(x)
u=y-m
v=x-n
dst[j][i]=(1-u)*(1-v)*src[m][n]+(1-u)*v*src[m][n+1]+u*(1-v)*src[m+1][n]+u*v*src[m+1][n+1]
#'''
return dst
def applyAffineTransform(src,srcTri,dstTri,size):
#获取仿射变换矩阵M
M=cv2.getAffineTransform(np.float32(srcTri),np.float32(dstTri))
#M=getAffineTransform(srcTri,dstTri)
#将仿射变换应用到图像块中
dst=cv2.warpAffine(src,M,(size[0],size[1]),None,flags=cv2.INTER_LINEAR,borderMode=cv2.BORDER_REFLECT_101)
#dst=warpAffine(src,M,size,dstTri)
return dst
#####################################################################
#定义warp函数来对图像块进行形变处理
def warpImage(srcTri,dstTri,img1,img):
#为每个三角形寻找边界矩形
r1=cv2.boundingRect(np.float32(srcTri))
r=cv2.boundingRect(np.float32(dstTri))
#每个三角形三个顶点与矩形左上角顶点的偏移
t1Rect=[]
tRect=[]
for i in range(0,3):
t1Rect.append(((srcTri[i][0]-r1[0]),(srcTri[i][1]-r1[1])))
tRect.append(((dstTri[i][0]-r[0]),(dstTri[i][1]-r[1])))
#为r设置掩膜
mask=np.zeros((r[3],r[2],3),dtype=np.float32)
cv2.fillConvexPoly(mask,np.int32(tRect),(1.0,1.0,1.0),16,0)
#裁剪矩形块
img1Rect=img1[r1[1]:r1[1]+r1[3],r1[0]:r1[0]+r1[2]]
#imgRect=img[r[1]:r[1]+r[3],r[0]:r[0]+r[2]]
#对img1Rect进行warpping操作
size=(r[2],r[3])
warpImage1=applyAffineTransform(img1Rect,t1Rect,tRect,size)
#dim=(size)
#img2Rect=cv2.resize(img1Rect,dim)
#imgmix=(1.0 - alpha) * img2Rect + alpha * warpImage1
#把warpping后的warpImage1复制到输出图像
img[r[1]:r[1]+r[3],r[0]:r[0]+r[2]]=img[r[1]:r[1]+r[3],r[0]:r[0]+r[2]] * (1-mask) + warpImage1 * mask
#imgRect=imgRect * (1-mask) + warpImage1
#return imgRect
######################################################################################
def interpolation(image):
'''
定义插值函数
:return:
'''
image_h=image.shape[0]
image_w=image.shape[1]
for j in range(image_h):
for i in range(image_w):
if image[j][i].all()==0 and (j+2)<image_h and (i+2)<image_w:
image[j][i]=image[j+2][i+2]
return image
##########################################################################################
if __name__=='__main__':
#设置alpha值
alpha=1
#读取图像
img_ori=cv2.imread('clinton.jpg')
img_refer=cv2.imread('telangpu1.jpg')
#将img图像转为浮点数据类型
img=np.float32(img_ori)
#读取坐标点
save_path_68='F:/BaiduNetdiskDownload/pictures/renlian/shape_predictor_68_face_landmarks.dat'
point_76_lst_ori=character_point(img_ori,save_path_68)
point_76_lst_refer=character_point(img_refer,save_path_68) #获取76个坐标点
#points1=readpoints('telangpu1.txt') #readpoints函数在前面有定义
#points2=readpoints('clinton1.txt')
points=[]
#'''
for i in range(0,len(point_76_lst_ori)):
x=alpha*point_76_lst_ori[i][0]+(1-alpha)*point_76_lst_refer[i][0]
y=alpha*point_76_lst_ori[i][1]+(1-alpha)*point_76_lst_refer[i][1]
points.append((int(x),int(y))) #获取目标图像的76个坐标点
#'''
lst=get_delaunary(img_ori,point_76_lst_ori) #获取每个三角形顶点在point_76_lst_ori中的索引
#为最终输出分配空间
warppingImage=np.zeros(img.shape,dtype=img.dtype)
#'''
for item in lst:
x=int(item[0])
y=int(item[1])
z=int(item[2])
t1=[point_76_lst_ori[x],point_76_lst_ori[y],point_76_lst_ori[z]]
t=[points[x],points[y],points[z]]
warpImage(t1,t,img,warppingImage) #对每个小块进行warp操作
#'''
#warppingImage=interpolation(np.uint8(warppingImage)) #对图像进行插值,去除黑线,函数在上面有定义
cv2.imshow('after warpping \'s image',np.uint8(warppingImage))
cv2.imshow('img_ori',img_ori)
k=cv2.waitKey(0)
if k==ord('s'):
#cv2.imwrite('final.jpg', np.uint8(warppingImage))
cv2.destroyAllWindows()注意:在这里有一段代码,是自己编写的,但是大家也可以调用cv2本身的库函数,效果要比自己写的好很多,而且速度也很快,而且调用库函数的话,是不需要进行插值的:
def applyAffineTransform(src,srcTri,dstTri,size):
#获取仿射变换矩阵M
M=cv2.getAffineTransform(np.float32(srcTri),np.float32(dstTri))
#M=getAffineTransform(srcTri,dstTri)
#将仿射变换应用到图像块中
dst=cv2.warpAffine(src,M,(size[0],size[1]),None,flags=cv2.INTER_LINEAR,borderMode=cv2.BORDER_REFLECT_101)
#dst=warpAffine(src,M,size,dstTri)
return dst结果:
 |
 |
alpha=0 alpha=0.2
 |
 |
||
alpha=0.4 alpha=0.6
 |
 |
||
alpha=0.8 alpha=1.0
3.3 实现两张人脸的morphing(渐变合成)
这里依然和上节的人脸warpping一样,把获取人脸的关键点和delaunay三角划分整合到了里面;并且依然是自己编写的仿射变换函数,但是这里结果却并不令人满意,会有大量的黑色条纹出现,需要进一步的改进,建议这里直接调用cv2的库函数即可:
import numpy as np
import cv2
import dlib
# Read points from text file 从text文件中读取点
def readPoints(path) :
# Create an array of points.
points = [];
# Read points
with open(path) as file :
for line in file :
x, y = line.split()
points.append((int(x), int(y)))
return points
########################################################################
def interpolation(image):
'''
定义插值函数
:return:
'''
image_h=image.shape[0]
image_w=image.shape[1]
for j in range(image_h):
for i in range(image_w):
if image[j][i].all()==0 and (j+2)<image_h and (i+2)<image_w:
image[j][i]=image[j+2][i+2]
return image
############################################################################################
#dlib人脸特征点检测调用,返回值是68个检测点构成的一个列表
def character_point(image, save_path):
detector = dlib.get_frontal_face_detector() #使用dlib库提供的人脸提取器
predictor = dlib.shape_predictor(save_path) #构建特征提取器
rects = detector(image,1) #rects表示人脸数 人脸检测矩形框4点坐标:左上角(x1,y1)、右下角(x2,y2)
points_lst = []
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(image,rects[i]).parts()]) #人脸关键点识别 landmarks:获取68个关键点的坐标
#shape=predictor(img,box) 功能:定位人脸关键点 img:一个numpy ndarray,包含8位灰度或RGB图像 box:开始内部形状预测的边界框
#返回值:68个关键点的位置
for idx, point in enumerate(landmarks): #enumerate函数遍历序列中的元素及它们的下标
# 68点的坐标
pos = (int(point[0, 0]), int(point[0, 1]))
#print(idx,pos)
points_lst.append(pos)
points_lst.append((0,0)) #图像左上角的点
points_lst.append((0,image.shape[0]//2)) #左边界中间的点
points_lst.append((0,image.shape[0]-1)) #左下角的点
points_lst.append((image.shape[1]//2,0)) #上边界中间的点
points_lst.append((image.shape[1]//2,image.shape[0]-1)) #下边界中间的点
points_lst.append((image.shape[1]-1,0)) #右上角的点
points_lst.append((image.shape[1]-1,image.shape[0]//2)) #右边界中间的点
points_lst.append((image.shape[1]-1,image.shape[0]-1)) #右下角的点
return points_lst
########################################################################
#delaunay三角划分
def rect_contains(rect, point):
if point[0] < rect[0]:
return False
elif point[1] < rect[1]:
return False
elif point[0] > rect[2]:
return False
elif point[1] > rect[3]:
return False
return True
def get_delaunary(img,point_list):
size=img.shape
rect = (0, 0, size[1], size[0]) #使用矩形定义要区分的空间
subdiv = cv2.Subdiv2D(rect) #创建 Subdiv2D 的实例
for p in point_list:
subdiv.insert(p)
lst=[] #创建列表,存入三角形三个顶点的索引
triangleList = subdiv.getTriangleList()
for t in triangleList:
pt1 = (int(t[0]), int(t[1]))
pt2 = (int(t[2]), int(t[3]))
pt3 = (int(t[4]), int(t[5]))
#print(pt1)
if rect_contains(rect, pt1) and rect_contains(rect, pt2) and rect_contains(rect, pt3):
#cv2.line(image, pt1, pt2, delaunary_color, 1, cv2.LINE_AA, 0)
#cv2.line(image, pt2, pt3, delaunary_color, 1, cv2.LINE_AA, 0)
#cv2.line(image, pt3, pt1, delaunary_color, 1, cv2.LINE_AA, 0)
lst_1=[]
for index,item in enumerate(point_list):
if pt1==item:
lst_1.append(index)
elif pt2==item:
lst_1.append(index)
elif pt3==item:
lst_1.append(index)
#print(item)
#print(lst_1)
lst.append(lst_1)
return lst
########################################################################
# 获得仿射变换矩阵
def getAffineTransform(srctri, dsttri):
srctri = np.float32(srctri)
dsttri = np.float32(dsttri)
srctri1 = []
for i in range(len(srctri)):
src = srctri[i]
src = list(src)
srctri1.append(src)
A = np.reshape(np.array(srctri1), (3, 2)) # 求出基于原始多边形顶点的坐标所组成的矩阵
dsttri1 = []
for i in range(len(dsttri)):
dst = dsttri[i]
dst = list(dst)
dst.append(1) #得出[x,y,1]的形式
dsttri1.append(dst)
B = np.reshape(np.array(dsttri1), (3, 3)) # 求出基于目标多边形顶点的坐标所组成的矩阵
MT= np.linalg.pinv(B).dot(A)
M=MT.T
return M
#计算三角形面积
def is_trangle_area(x1,y1,x2,y2,x3,y3):
return abs((x1*(y2-y3))+(x2*(y3-y1))+(x3*(y1-y2)))
#将仿射变换矩阵应用到图像中
def warpAffine(src,warpMat,size,dstTri):
dst=np.zeros((size[1],size[0],3),dtype=src.dtype)
x1=dstTri[0][0]
y1=dstTri[0][1]
x2=dstTri[1][0]
y2=dstTri[1][1]
x3=dstTri[2][0]
y3=dstTri[2][1]
abc=is_trangle_area(x1,y1,x2,y2,x3,y3)
#k=0
for j in range(dst.shape[0]):
for i in range(dst.shape[1]):
abp=is_trangle_area(x1,y1,x2,y2,i,j)
acp=is_trangle_area(x1,y1,x3,y3,i,j)
bcp=is_trangle_area(x2,y2,x3,y3,i,j)
if abc==abp+acp+bcp :
lst=[]
lst.append(i)
lst.append(j)
lst.append(1)
A=np.reshape(np.array(lst),(3,1)) #将列表转换为矩阵(3*1)
B=np.dot(warpMat,A) #应用仿射变换矩阵,得到仿射后的坐标
lst_dst=[]
lst1=list(B)
for index in range(len(lst1)):
lst_dst.append(lst1[index][0])
#print(dst.shape)
#print(lst_dst)
#dst[j][i]=src[(int(lst_dst[1])-1)][int(lst_dst[0])-1]
#'''
x=lst_dst[0]-1
y=lst_dst[1]-1
m=int(y)
n=int(x)
u=y-m
v=x-n
dst[j][i]=(1-u)*(1-v)*src[m][n]+(1-u)*v*src[m][n+1]+u*(1-v)*src[m+1][n]+u*v*src[m+1][n+1]
#'''
#dst=cv2.resize(dst,(size[0],size[1]))
return dst
def applyAffineTransform(src, srcTri, dstTri, size) :
warpMat=getAffineTransform(srcTri,dstTri)
#warpMat = cv2.getAffineTransform( np.float32(srcTri), np.float32(dstTri) )
#M = cv2.GetAffineTransform(src, dst) src:原始图像中的三个点的坐标 dst:变换后的这三个点对应的坐标;M:根据三个对应点求出的仿射变换矩阵(2*3)
dst=warpAffine(src,warpMat,size,dstTri)
#dst = cv2.warpAffine( src, warpMat, (size[0], size[1]), None, flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REFLECT_101 )
#cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) → dst
#src:输入图像 M:变换矩阵 dsize:输出图像的大小 flags:插值方法的组合(int类型) borderMode:边界像素模式(int类型) borderValue:边界填充值;默认情况下,它为0
return dst
########################################################################################
def morphTriangle(img1, img2, img_1,img_2,t1, t2, t, alpha) :
#为每个三角形寻找边界矩形
r1 = cv2.boundingRect(np.float32([t1]))
r2 = cv2.boundingRect(np.float32([t2]))
r = cv2.boundingRect(np.float32([t]))
#r=cv2.boundingRect(cnt) cnt:一个轮廓点集合;r:返回值,x,y(矩阵左上点的坐标);w(矩阵的宽),h(矩阵的高)
#各个矩形左上角点的偏移点
t1Rect = []
t2Rect = []
tRect = [] #[(),(),()]
for i in range(0, 3):
tRect.append(((t[i][0] - r[0]),(t[i][1] - r[1]))) #三角形每个顶点与相应矩形左上角顶点的偏移
t1Rect.append(((t1[i][0] - r1[0]),(t1[i][1] - r1[1])))
t2Rect.append(((t2[i][0] - r2[0]),(t2[i][1] - r2[1])))
#通过填充三角形来获取掩膜
mask = np.zeros((r[3], r[2], 3), dtype = np.float32) #3是3个通道的意思
cv2.fillConvexPoly(mask, np.int32(tRect), (1.0, 1.0, 1.0), 16, 0);
#cv2.fillConvexPoly( image , 多边形顶点array , RGB color)
#把扭曲图像应用到小的矩形块
img1Rect = img1[r1[1]:r1[1] + r1[3], r1[0]:r1[0] + r1[2]]
img2Rect = img2[r2[1]:r2[1] + r2[3], r2[0]:r2[0] + r2[2]] #裁剪矩形块
size = (r[2], r[3])
warpImage1 = applyAffineTransform(img1Rect, t1Rect, tRect, size) #对裁剪的矩形块进行扭曲操作
warpImage2 = applyAffineTransform(img2Rect, t2Rect, tRect, size)
# Alpha 混合矩形块
#imgRect = (1.0 - alpha) * warpImage1 + alpha * warpImage2
#复制矩形块的三角形区域到到输出图像
img_1[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] = img_1[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] * ( 1 - mask ) + warpImage1 * mask
img_2[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] = img_2[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] * ( 1 - mask ) + warpImage2 * mask
############################################################################################
def morphing(alpha,img1,img2,points1,points2,lst,imgMorph1,imgMorph2):
# 将图像转换为浮点数据类型
img1 = np.float32(img1)
img2 = np.float32(img2)
# 读取对应点的数组
points = [];
#计算加权平均点坐标
for i in range(0, len(points1)):
x = ( 1 - alpha ) * points1[i][0] + alpha * points2[i][0]
y = ( 1 - alpha ) * points1[i][1] + alpha * points2[i][1]
points.append((x,y))
# 从列表中读取三角形,列表中存放的是delaunay三角划分后的每个三角形的顶点的索引
for i in range(len(lst)):
a=lst[i][0]
b=lst[i][1]
c=lst[i][2]
#获得的t为三角形的三个顶点坐标
t1 = [points1[a], points1[b], points1[c]] #x,y,z分别为delaunay三角划分后对应的每个三角形的点的索引(顺序)
t2 = [points2[a], points2[b], points2[c]]
t = [ points[a], points[b], points[c] ]
#一次变形一个三角形
morphTriangle(img1, img2, imgMorph1,imgMorph2, t1, t2, t, alpha)
return imgMorph1,imgMorph2
#######################################################################################
def morphing_save(save_path_index):
lst=np.linspace(0,1,num=11)
for i,item in enumerate(lst):
alpha =item
#beta=lst[i+1]
imgM1,imgM2=morphing(alpha,img1,img2,point_76_lst_ori,point_76_lst_refer,save_path_index,imgMorph1,imgMorph2)
imgM1=interpolation(np.uint8(imgM1))
imgM2=interpolation(np.uint8(imgM2)) #对图像进行插值处理,去除黑线
imgMorph=(1.0 - alpha)*imgM1 + alpha * imgM2
cv2.imwrite("F:\\BaiduNetdiskDownload\\pictures\\renlian\\Morphing zibian\\{}.jpg".format(str(i+1)),imgMorph)
#cv2.waitKey(50)
###########################################################################################################
if __name__=='__main__':
# Read images 读取图像
img1 = cv2.imread('telangpu1.jpg');
img2 = cv2.imread('clinton.jpg');
#读取坐标点
#points1 = readPoints('F:\\BaiduNetdiskDownload\\pictures\\renlian\\telangpu1.txt') #points1为列表,里面存放的是获取的关键点的坐标[(),()...]
#points2 = readPoints('F:\\BaiduNetdiskDownload\\pictures\\renlian\\clinton1.txt')
save_path_68='F:/BaiduNetdiskDownload/pictures/renlian/shape_predictor_68_face_landmarks.dat'
point_76_lst_ori=character_point(img1,save_path_68)
point_76_lst_refer=character_point(img2,save_path_68) #获取76个坐标点
#save_path_index='tri2.txt' #从tri.txt文件中读取三角形,tri.txt中存放的是delaunay三角划分后的每个三角形的顶点的索引
#为最终输出分配空间
imgMorph1 = np.zeros(img1.shape, dtype = np.float32)
imgMorph2 = np.zeros(img1.shape, dtype = np.float32)
lst_index=get_delaunary(img1,point_76_lst_ori) #获取每个三角形顶点在point_76_lst_ori中的索引
'''
animate=True #打开动画
lst=np.linspace(0,1,num=11)
for i in lst:
alpha=i
if animate:
imgMorph1,imgMorph2=morphing(alpha,img1,img2,point_76_lst_ori,point_76_lst_refer,lst_index,imgMorph1,imgMorph2)
imgMorph1=interpolation(np.uint8(imgMorph1))
imgMorph2=interpolation(np.uint8(imgMorph2)) #对图像进行插值处理,去除黑线
imgMorph=(1.0 - alpha)*imgMorph1 + alpha * imgMorph2
cv2.imshow('Morphed Face',imgMorph)
cv2.waitKey(100)
#展示结果
cv2.imshow("Morphed Face", np.uint8(imgMorph))
cv2.waitKey(0)
'''
morphing_save(lst_index) #保存每个alptha值对应的morphing后的图片,前面有定义
'''
save_morphing_path='F:\BaiduNetdiskDownload\pictures\renlian\Morphing'
buff=[]
suffix='.jpg'
image_lst=seek_imagename(suffix) #寻找指定的morphing后的图像名称
for image_name in image_lst:
img_path=os.path.join(save_morphing_path,image_name)
buff.append(imageio.imread(img_path))
gif=imageio.mimsave('Morphed Face',buff,'GIF',duration=1) #保存生成的gif图像
# Display Result
#cv2.imshow("Morphed Face", np.uint8(imgMorph))
#cv2.waitKey(0)
'''这里面的morphing_save函数,是把每个alpha值对应合成的图片保存到一个文件夹之中,以便进行后续的gif动图制作或者是mp4视频的制作
注意:这里面,我把制作动图和mp4的代码写到了另一个py文件中,因为我试了试在morphing后面放入代码,结果总是跑不通,大家也可以自己试试能不能跑通:
制作gif动图的代码:
# !usr/bin/env python
# -*- coding:utf-8 _*-
"""
@Author:M兴M
@Blog(个人博客地址): https://blog.csdn.net/MbingxingM?spm=1000.2115.3001.5343
@File:creategif.py
@Time:2022/4/29 22:21
@Motto:不积跬步无以至千里,不积小流无以成江海,程序人生的精彩需要坚持不懈地积累!
"""
import imageio
from pathlib import Path
def imgs2gif(imgPaths, saveName, duration=None, loop=0, fps=None):
"""
生成动态图片 格式为 gif
:param imgPaths: 一系列图片路径
:param saveName: 保存gif的名字
:param duration: gif每帧间隔, 单位 秒
:param fps: 帧率
:param loop: 播放次数(在不同的播放器上有所区别), 0代表循环播放
:return:
"""
if fps:
duration = 1 / fps
images = [imageio.v2.imread(str(img_path)) for img_path in imgPaths]
imageio.mimsave(saveName, images, "gif", duration=duration, loop=loop)
pathlist = Path(r"F:\\BaiduNetdiskDownload\\pictures\\renlian\\Morphing\\").glob("*.jpg")
p_lis = []
for n, p in enumerate(pathlist):
if n % 1 == 0: #间隔几张图片显示
p_lis.append(p)
imgs2gif(p_lis, "morphing.gif", 0.033 * 11, 0)制作成mp4视频的代码:
"""
import cv2
#获取一张图片的宽高作为视频的宽高
image=cv2.imread('E:/face_morphing/mo/0.jpg')
image_info=image.shape
height=image_info[0]
width=image_info[1]
size=(height,width)
fps=10
fourcc=cv2.VideoWriter_fourcc(*"mp4v")
video = cv2.VideoWriter('E:\face_morphing\mo\001.mp4', cv2.VideoWriter_fourcc(*"mp4v"), fps, (width,height)) #创建视频流对象-格式一
for i in range(0,101,5):
file_name = "E:/face_morphing/mo/" + str(i) +".jpg "
image=cv2.imread(file_name)
video.write(image) # 向视频文件写入一帧--只有图像,没有声音
cv2.waitKey()
#video = cv2.VideoWriter('E:\face_morphing\morphing_video\001.mp4', cv2.VideoWriter_fourcc('m', 'p', '4', 'v'), fps, (width,height)) #创建视频流对象-格式二
参数1 即将保存的文件路径
参数2 VideoWriter_fourcc为视频编解码器
fourcc意为四字符代码(Four-Character Codes),顾名思义,该编码由四个字符组成,下面是VideoWriter_fourcc对象一些常用的参数,注意:字符顺序不能弄混
cv2.VideoWriter_fourcc('I', '4', '2', '0'),该参数是YUV编码类型,文件名后缀为.avi
cv2.VideoWriter_fourcc('P', 'I', 'M', 'I'),该参数是MPEG-1编码类型,文件名后缀为.avi
cv2.VideoWriter_fourcc('X', 'V', 'I', 'D'),该参数是MPEG-4编码类型,文件名后缀为.avi
cv2.VideoWriter_fourcc('T', 'H', 'E', 'O'),该参数是Ogg Vorbis,文件名后缀为.ogv
cv2.VideoWriter_fourcc('F', 'L', 'V', '1'),该参数是Flash视频,文件名后缀为.flv
cv2.VideoWriter_fourcc('m', 'p', '4', 'v') 文件名后缀为.mp4
参数3 为帧播放速率
参数4 (width,height)为视频帧大小
"""
import cv2
if __name__ == '__main__':
# 保存视频的FPS,可以适当调整, 帧率过低,视频会有卡顿
fps = 5
photo_size = (600, 800)
# 可以用(*'DVIX')或(*'X264'),如果都不行先装ffmepg: sudo apt-get install ffmepg
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# video: 要保存的视频地址
video = 'F:/BaiduNetdiskDownload/pictures/renlian/Morphing/video_fps1.mp4'
videoWriter = cv2.VideoWriter(video, fourcc, fps, photo_size)
for i in range(1, 12):
# image: 图片地址
image = "F:/BaiduNetdiskDownload/pictures/renlian/Morphing/" + str(i) + ".jpg"
frame = cv2.imread(image)
videoWriter.write(frame)
#videoWriter.release()
每个alpha值对应的合成图片:
alpha=0 alpha=0.1 alpha=0.2 alpha=0.3 alpha=0.4 alpha=0.5






alpha=0.6 alpha=0.7 alpha=0.8 alpha=0.9 alpha=1.0




 文章来源:https://www.toymoban.com/news/detail-435519.html
文章来源:https://www.toymoban.com/news/detail-435519.html
最后合成的gif动图:文章来源地址https://www.toymoban.com/news/detail-435519.html
到了这里,关于《数字图像处理》dlib人脸检测获取关键点,delaunay三角划分,实现人脸的几何变换warpping,接着实现两幅人脸图像之间的渐变合成morphing的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!