数据同步的方式
数据同步的2大方式
-
基于SQL查询的 CDC(Change Data Capture):
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据。也就是我们说的基于SQL查询抽取;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟;
- 工具软件以Kettle(Apache Hop最新版)、DataX为代表,需要结合任务调度系统使用。
-
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据;
- 工具软件以Flink CDC、阿里巴巴Canal、Debezium为代表。
基于SQL查询增量数据同步原理
我们考虑用SQL如何查询增量数据? 数据有增加、修改、删除 删除数据采用逻辑删除的方式,比如定义一个is_deleted字段标识逻辑删除 如果数据是 UPDATE的,也就是会被修改的,那么 where update_datetime >= last_datetime(调度滚动时间)就是增量数据 如果数据是 APPEND ONLY 的除了用更新时间还可以用where id >= 调度上次last_id
结合任务调度系统 调度时间是每日调度执行一次,那么 last_datetime = 当前调度开始执行时间 - 24小时,延迟就是1天 调度时间是15分钟一次,那么 last_datetime = 当前调度开始执行时间 - 15分钟,延迟就是15分钟
这样就实现了捕获增量数据,从而实现增量同步
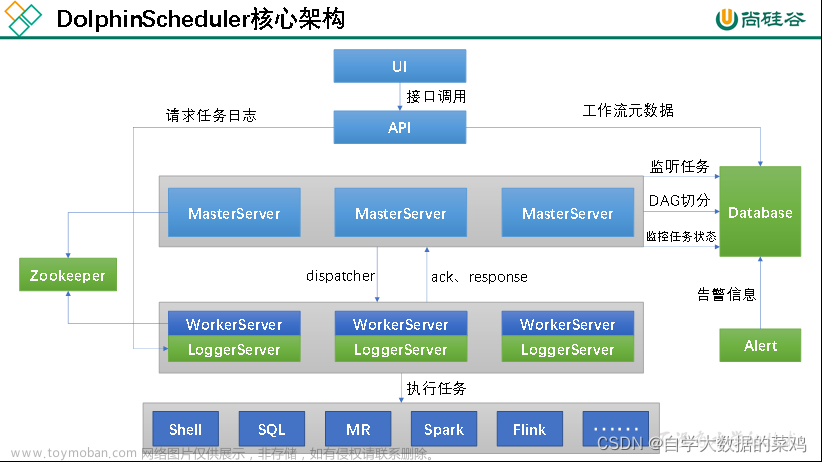
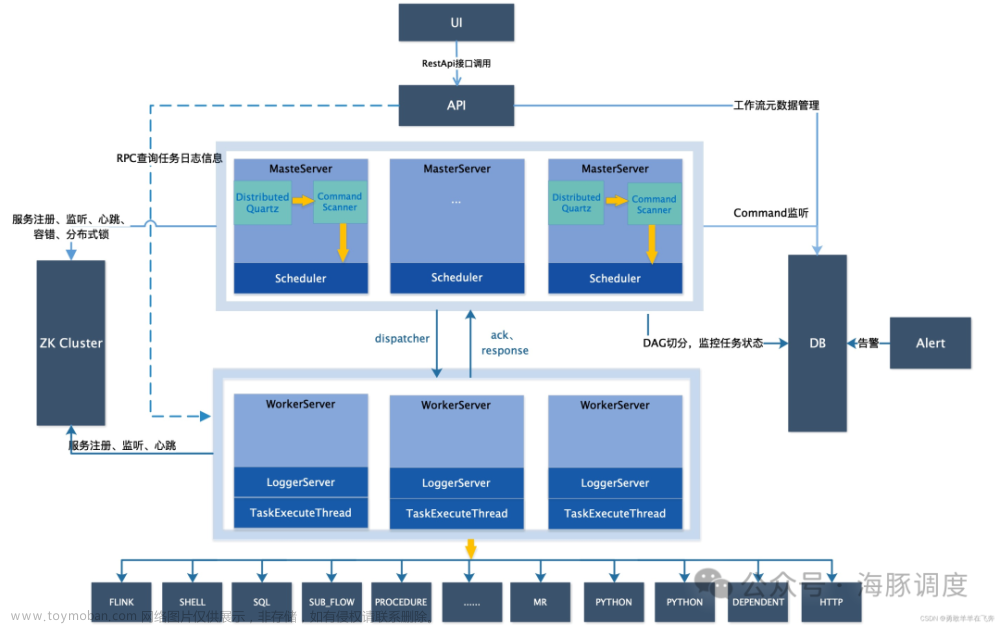
DolphinScheduler + Datax 构建离线增量数据同步平台
本实践使用 单机8c16g DataX 2022-03-01 官网下载 DolphinScheduler 2.0.3(DolphinScheduler的安装过程略,请参考官网)
DolphinScheduler 中设置好DataX环境变量 DolphinScheduler 提供了可视化的作业流程定义,用来离线定时调度DataX Job作业,使用起来很是顺滑文章来源:https://www.toymoban.com/news/detail-435576.html
基于SQL查询离线数据同步的用武之地 为什么不用基于日志实时的方式?不是不用,而是根据场合用。考虑到业务实际文章来源地址https://www.toymoban.com/news/detail-435576.html
到了这里,关于DolphinScheduler 调度 DataX 实现 MySQL To ElasticSearch 增量数据同步实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!