背景
记录一次云上排查内存泄露的问题,最近监控告警云上有空指针异常报出,于是找到运维查日志定位到具体是哪一行代码抛出的空指针异常,
问题分析
发现是在解析cookie的一个方法内,调用HttpServletRequest.getServerName()获取不到抛出的NPE,这个获取服务名获取不到,平时都没有出现过的问题,又没有发版,那初步怀疑应该前端或者传输过程有问题导致获取不到参数,
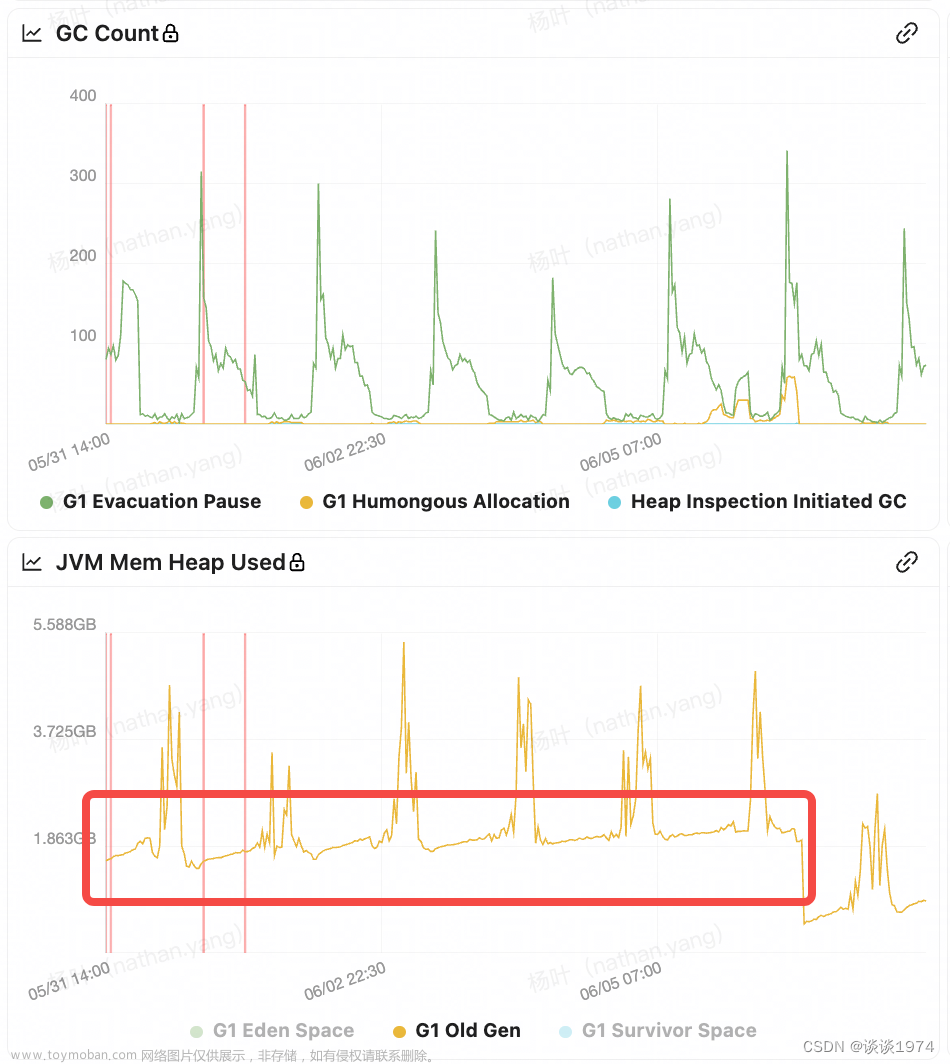
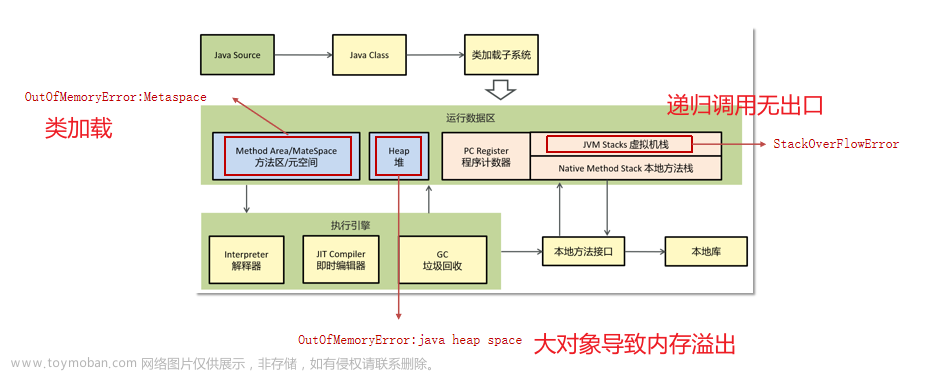
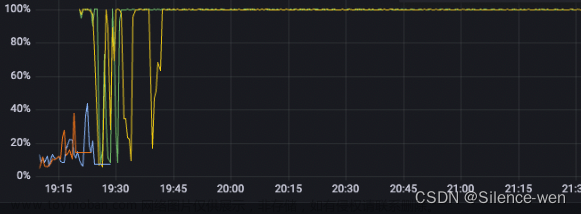
后续找了运维查了ng的日志,确实存在状态码为499的错误码,查了一下这个是客户端端主动关闭请求或者客户端网络断掉时报的错误码,那也就是前端断开了请求,继续排查为啥前端会中断请求的原因,问了前端同学说是超时时间设置了10秒,又看了日志,确实是有处理时间超过10秒的,那问题大概定位到了。接下来就是分析处理时长为什么会那么长,看了报错的时候请求量并没有很大,2.0云上本身就还没有放量,后续让运维查了机器有几台cpu用量处于30%左右,明显高于另外几台3%,而且499错误的集中在cpu用量高的几台,怀疑是否是内存问题导致,让运维跑了jstat -gcutil 看了一下,确实存在full GC问题,又跑了jmap -dump下了dump文件,定位到是ip限流的方法,有一个清除Map的方法在多线程并发情况下没有生效,导致内存泄露,知道问题后反推感觉就一切的疑问有了结果,ng报499是前置超时,超时是服务频繁full gc导致stw,无法处理请求导致耗时增加,ng探活接口在机器stw期间无法响应产生了error.log,而有几台机器cpu不高是因为之前重启过所以释放掉了内存没有触发full gc。
后续处理是改进了ip限流的方法,测试环境复现问题和改动限流方法,
(jstat命令使用参考:https://www.cnblogs.com/i-code/p/14157048.html)
1、FullGc触发的很频繁,时间或是次数并不是远小于Younggc的,但是每次回收都较为有效,回收后能有效清理内存释放空间。此时考虑内存分配不足,应调整Jvm启动参数(Xmx
Xms),以避免频繁gc影响性能甚至因内存不够造成 OOM。2、FullGc后期触发越发频繁,每次回收后老年代内存释放的很少,这种情况是内存泄漏或业务设计不合理导致,泄露的内存不能被有效回收,导致可用空间越来越小最后直至不可用,此种问题需要针对性的解决。
总结
通过guaua的LoadingCache监听器的方式过期自动处理,这次问题嵌套问题比较多,由于上报量低,ng侧报了499没有纳入监控范围,而且机器由于重启没有快速发现问题,后续改进是代码侧能复用规范代码最好复用,不要重复造轮子,和测试沟通阶段应该覆盖对应的场景测试,开发需要详尽跟测试反馈改动点和测试案例评审,定位问题应该从实际出发,出现问题得及时从现有信息的结果反馈去判断问题所在,及时处理和团队沟通。文章来源:https://www.toymoban.com/news/detail-435611.html
 文章来源地址https://www.toymoban.com/news/detail-435611.html
文章来源地址https://www.toymoban.com/news/detail-435611.html
到了这里,关于记录线上排查内存泄露问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!